Mitigating Social Bias in Large Language Models: A Multi-Objective Approach within a Multi-Agent Framework
作者: Zhenjie Xu, Wenqing Chen, Yi Tang, Xuanying Li, Cheng Hu, Zhixuan Chu, Kui Ren, Zibin Zheng, Zhichao Lu
分类: cs.CL
发布日期: 2024-12-20 (更新: 2025-02-12)
备注: This work has been accepted at The 39th Annual AAAI Conference on Artificial Intelligence (AAAI-2025)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MOMA多智能体框架,在降低大语言模型社会偏见的同时维持性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 多智能体系统 因果干预 公平性 自然语言处理 可信AI
📋 核心要点
- 大型语言模型存在社会偏见,直接提示模型进行道德行为会导致性能下降。
- MOMA通过多智能体对输入进行因果干预,打破偏见内容与答案的直接关联。
- 实验表明,MOMA显著降低偏见,在BBQ数据集上偏见降低87.7%,性能下降仅6.8%。
📝 摘要(中文)
大型语言模型(LLMs)的出现推动了自然语言处理(NLP)的显著进步。然而,这些模型常常产生带有社会偏见的输出。目前的研究主要通过提示LLMs以符合道德规范的方式运行来解决这个问题,但这种方法会导致性能的显著下降。本文提出了一种多智能体框架下的多目标方法(MOMA),旨在减轻LLMs中的社会偏见,同时避免显著降低其性能。MOMA的关键思想是部署多个智能体对输入问题中与偏见相关的内容进行因果干预,从而打破这些内容与相应答案之间的捷径连接。与导致性能下降的传统去偏见技术不同,MOMA在大幅降低偏见的同时,保持了下游任务的准确性。在两个数据集和两个模型上进行的实验表明,MOMA将偏见分数降低了高达87.7%,而在BBQ数据集中仅有高达6.8%的性能下降。此外,它还在StereoSet数据集中显著提高了多目标指标icat,高达58.1%。代码将在https://github.com/Cortantse/MOMA上提供。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时,常常会表现出社会偏见,例如性别歧视、种族歧视等。现有的缓解方法,如直接提示模型进行道德行为,虽然可以减少偏见,但往往会导致模型在其他任务上的性能显著下降,无法兼顾公平性和准确性。
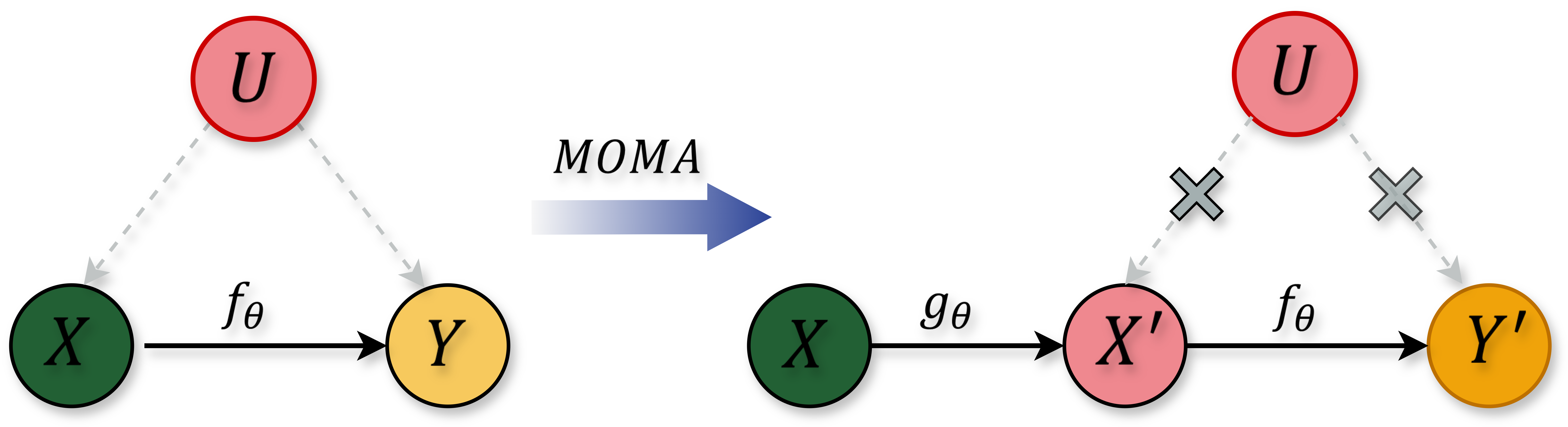
核心思路:MOMA的核心思路是通过因果干预来消除输入文本中与偏见相关的“捷径”。这些捷径是指输入中的某些词语或短语会直接触发模型产生带有偏见的输出。通过部署多个智能体对这些词语进行干预,可以打破这种直接的因果关系,从而减少偏见。
技术框架:MOMA采用多智能体框架,包含以下主要模块:1) 偏见内容识别模块:识别输入文本中可能引发偏见的关键词或短语。2) 因果干预模块:部署多个智能体,对识别出的偏见内容进行修改或替换,生成多个经过干预的输入文本。3) 答案生成模块:利用LLM对每个经过干预的输入文本生成答案。4) 答案聚合模块:将多个答案进行聚合,得到最终的输出结果。
关键创新:MOMA的关键创新在于其多智能体因果干预框架。与传统的直接修改模型参数或训练数据的方法不同,MOMA通过在输入层面进行干预,避免了对模型本身的修改,从而可以在不显著降低模型性能的情况下,有效地减少偏见。此外,多智能体的设计可以探索不同的干预策略,提高模型的鲁棒性。
关键设计:MOMA的关键设计包括:1) 智能体的数量和类型:需要根据具体的任务和数据集选择合适的智能体数量和类型,例如可以使用不同的智能体来替换不同的偏见词语。2) 干预策略:需要设计有效的干预策略,例如可以使用同义词替换、反义词替换或随机替换等方法。3) 答案聚合方法:需要选择合适的答案聚合方法,例如可以使用投票法、平均法或加权平均法等方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MOMA在两个数据集(BBQ和StereoSet)和两个模型上都取得了显著的效果。在BBQ数据集上,MOMA将偏见分数降低了高达87.7%,而性能下降仅为6.8%。在StereoSet数据集上,MOMA显著提高了多目标指标icat,高达58.1%。这些结果表明,MOMA可以在有效降低偏见的同时,保持模型的性能。
🎯 应用场景
MOMA具有广泛的应用前景,可用于各种需要使用大型语言模型的场景,例如智能客服、文本生成、机器翻译等。通过降低模型中的社会偏见,可以提高这些应用的用户体验和公平性,避免产生歧视性或冒犯性的内容。此外,MOMA还可以用于评估和改进现有的LLMs,帮助开发者构建更加负责任和可靠的AI系统。
📄 摘要(原文)
Natural language processing (NLP) has seen remarkable advancements with the development of large language models (LLMs). Despite these advancements, LLMs often produce socially biased outputs. Recent studies have mainly addressed this problem by prompting LLMs to behave ethically, but this approach results in unacceptable performance degradation. In this paper, we propose a multi-objective approach within a multi-agent framework (MOMA) to mitigate social bias in LLMs without significantly compromising their performance. The key idea of MOMA involves deploying multiple agents to perform causal interventions on bias-related contents of the input questions, breaking the shortcut connection between these contents and the corresponding answers. Unlike traditional debiasing techniques leading to performance degradation, MOMA substantially reduces bias while maintaining accuracy in downstream tasks. Our experiments conducted on two datasets and two models demonstrate that MOMA reduces bias scores by up to 87.7%, with only a marginal performance degradation of up to 6.8% in the BBQ dataset. Additionally, it significantly enhances the multi-objective metric icat in the StereoSet dataset by up to 58.1%. Code will be made available at https://github.com/Cortantse/MOMA.