TL-Training: A Task-Feature-Based Framework for Training Large Language Models in Tool Use
作者: Junjie Ye, Yilong Wu, Sixian Li, Yuming Yang, Zhiheng Xi, Tao Gui, Qi Zhang, Xuanjing Huang, Peng Wang, Zhongchao Shi, Jianping Fan, Zhengyin Du
分类: cs.CL, cs.AI
发布日期: 2024-12-20 (更新: 2025-08-26)
备注: Accepted by EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
TL-Training:一种基于任务特征的工具使用大语言模型训练框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 工具使用 监督微调 强化学习 任务特征 动态权重调整 近端策略优化
📋 核心要点
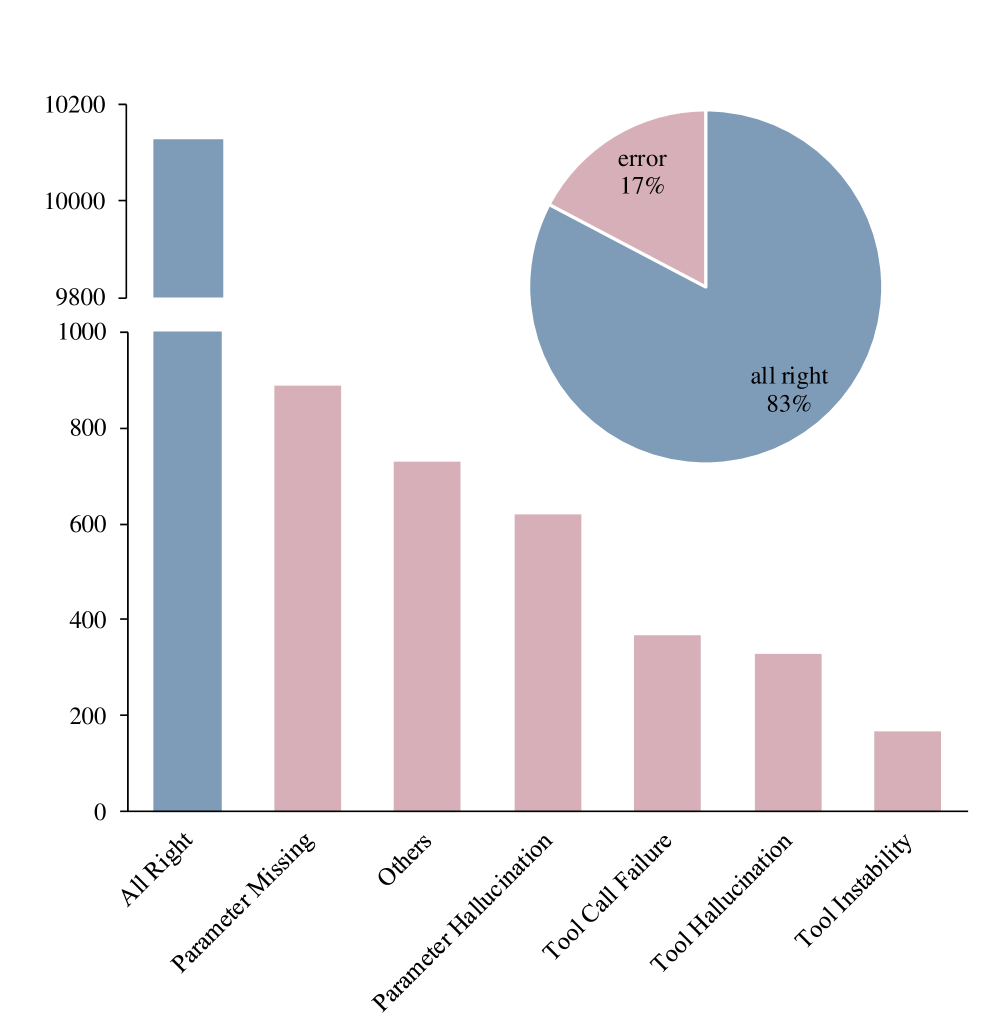
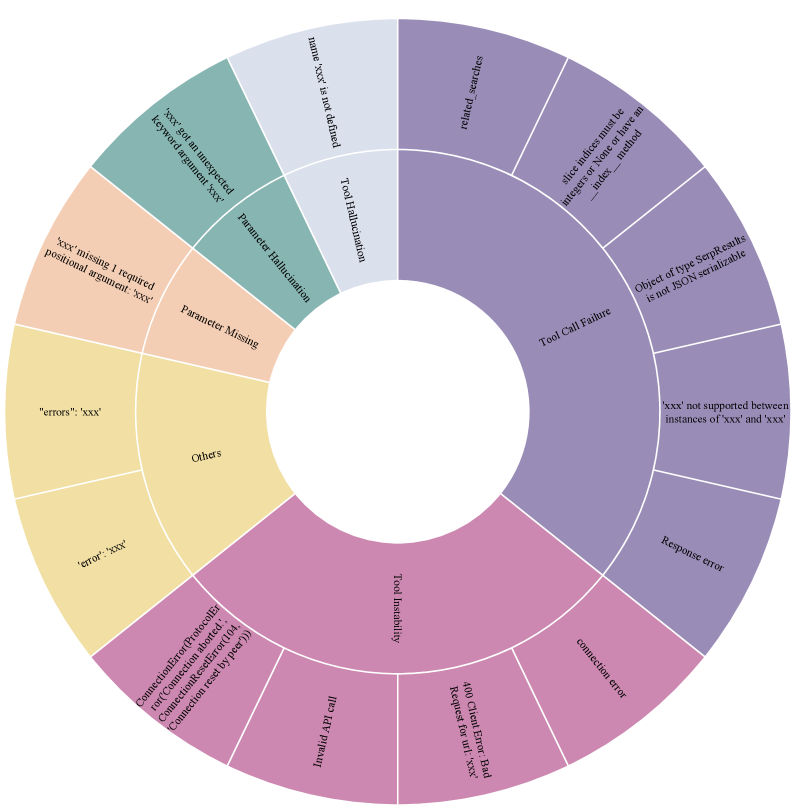
- 现有SFT方法在工具使用训练中忽略了任务特定特征,导致LLM在工具使用上存在性能瓶颈。
- TL-Training框架通过减轻次优数据影响、动态调整token权重和优化奖励机制来提升工具使用性能。
- 实验表明,TL-Training仅用少量数据即可使LLM在工具使用上达到或超过现有模型,并增强了鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)通过利用工具与环境交互,取得了显著进展,这是通向通用人工智能的关键一步。然而,标准的监督微调(SFT)方法依赖于大规模数据集,通常忽略了工具使用中特定于任务的特征,导致性能瓶颈。为了解决这个问题,我们分析了三个现有的LLM,并揭示了关键见解:训练数据可能无意中阻碍工具使用行为,token重要性分布不均匀,以及工具调用中的错误属于少数几个类别。基于这些发现,我们提出了TL-Training,这是一个基于任务特征的框架,可以减轻次优训练数据的影响,动态调整token权重以在SFT期间优先考虑关键token,并结合针对错误类别量身定制的强大奖励机制,通过近端策略优化进行优化。我们通过训练CodeLLaMA-2-7B并在四个开源测试集上评估它来验证TL-Training。我们的结果表明,使用我们的方法训练的LLM在使用1,217个训练数据点的情况下,在工具使用性能方面与开源和闭源LLM相匹配或超过它们。此外,我们的方法增强了在嘈杂环境中的鲁棒性并提高了通用任务性能,为LLM中的工具使用训练提供了一种可扩展且高效的范例。代码和数据可在https://github.com/Junjie-Ye/TL-Training获得。
🔬 方法详解
问题定义:现有的大语言模型在工具使用训练中,标准的监督微调方法依赖大规模数据集,但忽略了任务的特定特征,导致模型在工具使用上的性能受限。此外,训练数据可能包含噪声或次优数据,进一步阻碍模型的学习。现有方法没有充分考虑token的重要性差异以及工具调用错误的类别信息。
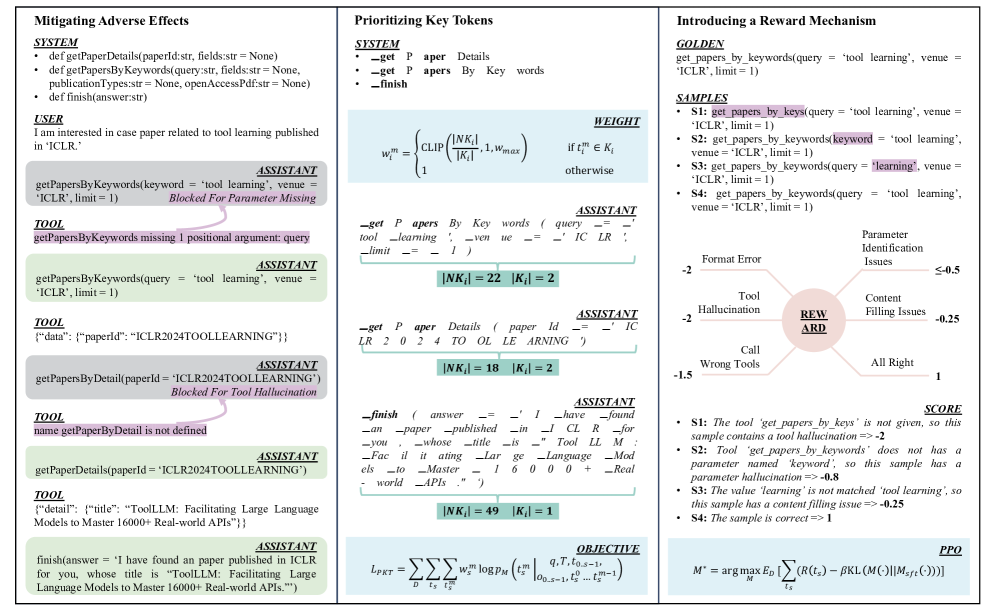
核心思路:TL-Training的核心思路是基于任务特征进行训练,通过三个关键组件来解决上述问题。首先,减轻次优训练数据的影响;其次,动态调整token权重,优先考虑关键token;最后,设计针对错误类别的奖励机制,并使用近端策略优化进行优化。这种方法旨在更有效地利用训练数据,提高模型在工具使用方面的性能和鲁棒性。
技术框架:TL-Training框架包含三个主要模块:1) 数据过滤模块,用于减轻次优训练数据的影响;2) 动态权重调整模块,根据token的重要性动态调整权重,优先考虑关键token;3) 强化学习模块,设计针对错误类别的奖励机制,并使用近端策略优化(PPO)进行优化。整个流程首先对数据进行过滤,然后进行SFT训练,期间动态调整token权重,最后使用PPO进行强化学习。
关键创新:TL-Training的关键创新在于其基于任务特征的训练方法,它与传统的SFT方法不同,后者通常平等对待所有token,并且没有针对特定错误类别进行优化。TL-Training通过动态调整token权重和设计针对错误类别的奖励机制,更有效地利用训练数据,从而提高了模型在工具使用方面的性能和鲁棒性。此外,该框架仅使用少量数据即可达到甚至超过现有模型的性能。
关键设计:在动态权重调整模块中,论文可能使用了某种注意力机制或梯度信息来评估token的重要性,并据此调整权重。在强化学习模块中,奖励函数的设计至关重要,需要根据不同的错误类别进行精细化设计,例如,对于工具调用失败的错误,给予负向奖励,对于成功完成任务的,给予正向奖励。PPO算法的具体参数设置(如学习率、clip ratio等)也会影响训练效果。数据过滤模块的具体实现方式(如基于规则或基于模型的过滤)也需要根据具体任务进行选择。
🖼️ 关键图片
📊 实验亮点
TL-Training在四个开源测试集上进行了验证,结果表明,使用该方法训练的CodeLLaMA-2-7B仅使用1,217个训练数据点,在工具使用性能方面与开源和闭源LLM相匹配或超过它们。此外,该方法还增强了模型在嘈杂环境中的鲁棒性,并提高了通用任务性能。这些结果表明,TL-Training是一种高效且可扩展的工具使用训练方法。
🎯 应用场景
TL-Training框架可应用于各种需要大语言模型进行工具使用的场景,例如智能助手、自动化流程、代码生成和调试等。该方法能够提高模型在复杂任务中的表现,并降低对大规模标注数据的依赖,具有广泛的应用前景。未来,该方法可以进一步扩展到更多类型的工具和任务,并与其他技术(如知识图谱、强化学习)相结合,以实现更强大的通用人工智能。
📄 摘要(原文)
Large language models (LLMs) achieve remarkable advancements by leveraging tools to interact with environments, a critical step toward generalized AI. However, the standard supervised fine-tuning (SFT) approach, which relies on large-scale datasets, often overlooks task-specific characteristics in tool use, leading to performance bottlenecks. To address this issue, we analyze three existing LLMs and uncover key insights: training data can inadvertently impede tool-use behavior, token importance is distributed unevenly, and errors in tool calls fall into a small set of categories. Building on these findings, we propose~\emph{TL-Training}, a task-feature-based framework that mitigates the effects of suboptimal training data, dynamically adjusts token weights to prioritize key tokens during SFT, and incorporates a robust reward mechanism tailored to error categories, optimized through proximal policy optimization. We validate TL-Training by training CodeLLaMA-2-7B and evaluating it on four open-source test sets. Our results demonstrate that the LLM trained by our method matches or surpasses both open- and closed-source LLMs in tool-use performance using only 1,217 training data points. Additionally, our method enhances robustness in noisy environments and improves general task performance, offering a scalable and efficient paradigm for tool-use training in LLMs. Code and data are available at https://github.com/Junjie-Ye/TL-Training.