ViFactCheck: A New Benchmark Dataset and Methods for Multi-domain News Fact-Checking in Vietnamese
作者: Tran Thai Hoa, Tran Quang Duy, Khanh Quoc Tran, Kiet Van Nguyen
分类: cs.CL, cs.IR
发布日期: 2024-12-19
备注: Accepted at AAAI'2025 Main Conference
💡 一句话要点
ViFactCheck:提出越南语多领域新闻事实核查基准数据集与方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 越南语 自然语言处理 基准数据集 大型语言模型
📋 核心要点
- 现有越南语事实核查资源匮乏,缺乏高质量、多领域的数据集支持。
- ViFactCheck通过构建包含7232个标注样本的越南语数据集,为该领域提供基准。
- 实验表明,Gemma模型在ViFactCheck数据集上取得了89.90%的宏平均F1得分,性能显著。
📝 摘要(中文)
数字时代信息的快速传播凸显了有效的事实核查工具的关键需求,特别是对于像越南语这样资源有限的语言。为了应对这一挑战,我们推出了ViFactCheck,这是第一个公开可用的基准数据集,专门为越南语跨多个在线新闻领域的事实核查而设计。该数据集包含7,232个由人工标注的声明-证据组合,来源于信誉良好的越南在线新闻,涵盖12个不同的主题。它经过了细致的标注过程,以确保高质量和可靠性,实现了0.83的Fleiss Kappa跨标注者协议分数。我们的评估利用了最先进的预训练和大型语言模型,采用微调和提示技术来评估性能。值得注意的是,Gemma模型表现出卓越的有效性,宏平均F1得分高达89.90%,从而为事实核查基准树立了新的标准。这一结果突显了Gemma在准确识别和验证越南语事实方面的强大能力。为了进一步促进事实核查技术的进步并提高数字媒体的可靠性,我们已在GitHub上免费提供ViFactCheck数据集、模型检查点、事实核查管道和源代码。此举旨在激发进一步的研究并提高低资源语言信息的准确性。
🔬 方法详解
问题定义:论文旨在解决越南语新闻事实核查领域缺乏高质量、多领域数据集的问题。现有方法由于数据资源的限制,难以有效训练和评估事实核查模型,阻碍了该领域的发展。
核心思路:论文的核心思路是构建一个高质量、人工标注的越南语事实核查数据集,并利用该数据集对现有的预训练语言模型进行微调,以提升其在越南语事实核查任务上的性能。通过提供公开的数据集和基线模型,促进该领域的研究和发展。
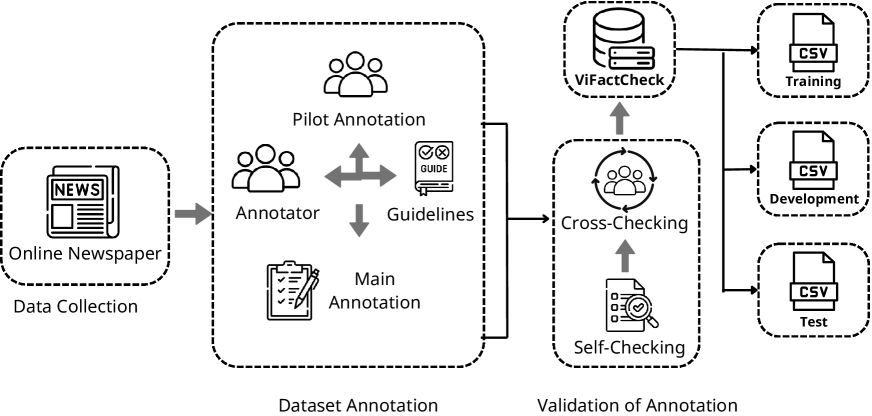
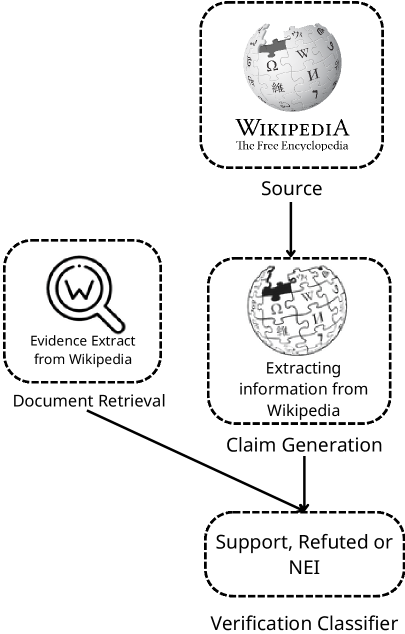
技术框架:整体框架包括数据收集、数据标注、模型训练和评估四个主要阶段。首先,从信誉良好的越南在线新闻中收集新闻文章和相关声明。然后,由人工标注员对声明和证据进行标注,判断证据是否支持、反对或不相关于声明。接着,使用标注好的数据对预训练语言模型(如Gemma)进行微调。最后,使用标准的事实核查指标(如宏平均F1得分)评估模型的性能。
关键创新:论文的关键创新在于构建了首个公开可用的越南语多领域事实核查基准数据集ViFactCheck。该数据集的规模较大,覆盖了多个主题,并且经过了严格的人工标注,保证了数据的质量和可靠性。
关键设计:数据集包含7,232个声明-证据对,涵盖12个不同的主题。标注过程采用了Fleiss Kappa系数来衡量标注者之间的一致性,最终达到了0.83的高分。模型训练方面,采用了微调和提示技术,并使用了宏平均F1得分作为主要的评估指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过在ViFactCheck数据集上微调的Gemma模型取得了89.90%的宏平均F1得分,显著优于其他基线模型。这一结果证明了ViFactCheck数据集的有效性,并为越南语事实核查任务树立了新的性能标准。该研究还公开了数据集、模型检查点和源代码,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于自动化新闻事实核查系统,帮助用户识别和过滤虚假信息,提高信息的可信度。此外,该数据集和模型可以促进越南语自然语言处理领域的研究,并为其他低资源语言的事实核查研究提供借鉴。未来,可以进一步扩展数据集的规模和领域,并探索更先进的模型和技术。
📄 摘要(原文)
The rapid spread of information in the digital age highlights the critical need for effective fact-checking tools, particularly for languages with limited resources, such as Vietnamese. In response to this challenge, we introduce ViFactCheck, the first publicly available benchmark dataset designed specifically for Vietnamese fact-checking across multiple online news domains. This dataset contains 7,232 human-annotated pairs of claim-evidence combinations sourced from reputable Vietnamese online news, covering 12 diverse topics. It has been subjected to a meticulous annotation process to ensure high quality and reliability, achieving a Fleiss Kappa inter-annotator agreement score of 0.83. Our evaluation leverages state-of-the-art pre-trained and large language models, employing fine-tuning and prompting techniques to assess performance. Notably, the Gemma model demonstrated superior effectiveness, with an impressive macro F1 score of 89.90%, thereby establishing a new standard for fact-checking benchmarks. This result highlights the robust capabilities of Gemma in accurately identifying and verifying facts in Vietnamese. To further promote advances in fact-checking technology and improve the reliability of digital media, we have made the ViFactCheck dataset, model checkpoints, fact-checking pipelines, and source code freely available on GitHub. This initiative aims to inspire further research and enhance the accuracy of information in low-resource languages.