MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
作者: Qihao Zhao, Yangyu Huang, Tengchao Lv, Lei Cui, Qinzheng Sun, Shaoguang Mao, Xin Zhang, Ying Xin, Qiufeng Yin, Scarlett Li, Furu Wei
分类: cs.CL, cs.AI, cs.LG, cs.PF
发布日期: 2024-12-19
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出MMLU-CF:一个无污染的多任务语言理解基准,用于更可靠地评估LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 基准测试 数据污染 多任务学习 知识理解 模型评估 无污染基准
📋 核心要点
- 现有MMLU等基准测试因其开源性和LLM训练数据的广泛性,面临着严重的数据污染问题,导致评估结果不可靠。
- MMLU-CF通过从更广泛的领域获取数据并设计去污规则,避免无意的数据泄露;同时采用闭源测试集防止恶意泄露。
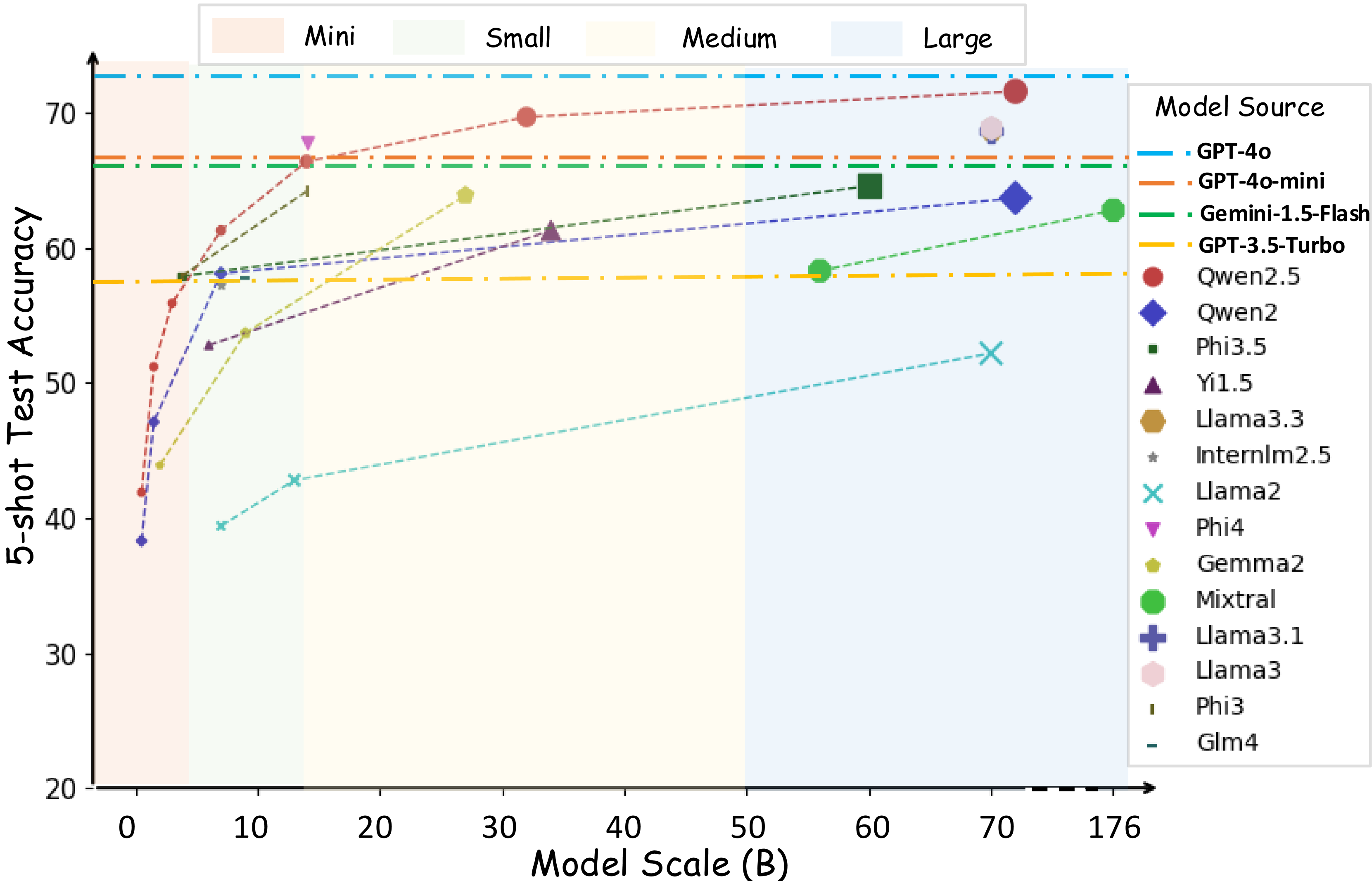
- 实验表明,即使是强大的GPT-4o在MMLU-CF测试集上的表现也显著下降,验证了该基准在消除污染和提高评估严格性方面的有效性。
📝 摘要(中文)
大规模多任务语言理解(MMLU)等选择题数据集被广泛用于评估大型语言模型(LLM)的常识、理解和问题解决能力。然而,这些基准的开源性质以及LLM训练数据的广泛来源不可避免地导致了基准污染,从而导致不可靠的评估结果。为了缓解这个问题,我们提出了一个无污染且更具挑战性的选择题基准,称为MMLU-CF。该基准通过避免无意和恶意的数据泄露,重新评估LLM对世界知识的理解。为了避免无意的数据泄露,我们从更广泛的领域获取数据,并设计了三个去污规则。为了防止恶意的数据泄露,我们将基准分为难度和主题分布相似的验证集和测试集。测试集保持闭源以确保可靠的结果,而验证集公开以提高透明度并促进独立验证。我们对主流LLM的评估表明,强大的GPT-4o在测试集上仅实现了73.4%的5-shot得分和71.9%的0-shot得分,这表明我们的方法在创建更严格和无污染的评估标准方面的有效性。
🔬 方法详解
问题定义:论文旨在解决现有大规模多任务语言理解基准(如MMLU)中普遍存在的“污染”问题。这种污染源于LLM训练数据中可能包含基准测试集中的样本,导致模型在测试中表现虚高,无法真实反映其泛化能力。现有方法难以有效避免无意和恶意的基准数据泄露,评估结果的可靠性受到质疑。
核心思路:MMLU-CF的核心思路是构建一个“无污染”的基准测试集,通过多管齐下的策略来避免数据泄露。一方面,扩大数据来源范围,并设计严格的去污规则,以减少无意的数据泄露。另一方面,将测试集设为闭源,防止恶意的数据泄露,确保评估结果的可靠性。
技术框架:MMLU-CF的构建主要包含以下几个阶段:1) 数据收集:从更广泛的知识领域收集多选题数据。2) 数据清洗:应用三个去污规则,包括基于关键词的过滤、基于相似度的过滤和人工审核,以去除潜在的污染数据。3) 数据集划分:将数据集划分为公开的验证集和闭源的测试集,保证两者在难度和主题分布上相似。4) 模型评估:使用验证集进行模型调优,使用闭源测试集进行最终评估。
关键创新:MMLU-CF的关键创新在于其系统性的污染控制方法。它不仅考虑了无意的数据泄露,还针对恶意的数据泄露进行了防范。通过闭源测试集的设计,确保了评估结果的公正性和可靠性。此外,该基准的构建过程更加透明,验证集公开,方便研究人员进行独立验证。
关键设计:MMLU-CF的关键设计包括:1) 三个去污规则:基于关键词的过滤旨在去除包含与训练数据高度相关的关键词的样本;基于相似度的过滤旨在去除与已知训练数据过于相似的样本;人工审核则用于进一步确认和去除潜在的污染数据。2) 验证集和测试集的难度和主题分布对齐:确保模型在验证集上获得的性能能够可靠地预测其在测试集上的性能。3) 闭源测试集:只有基准的维护者可以访问测试集,防止模型开发者通过直接训练测试集来提高分数。
🖼️ 关键图片


📊 实验亮点
在MMLU-CF测试集上,即使是强大的GPT-4o模型,其5-shot得分仅为73.4%,0-shot得分仅为71.9%。这一结果远低于GPT-4o在传统MMLU基准上的表现,表明MMLU-CF能够有效检测出模型在受污染数据上的过拟合现象,并提供更可靠的性能评估。
🎯 应用场景
MMLU-CF可用于更可靠地评估大型语言模型在常识、理解和问题解决方面的能力。该基准的无污染特性使其能够更准确地反映模型的真实性能,从而推动LLM的研发和改进。此外,MMLU-CF可以作为评估LLM安全性和鲁棒性的重要工具,帮助识别和解决潜在的安全风险。
📄 摘要(原文)
Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs' understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.