Language Models as Continuous Self-Evolving Data Engineers
作者: Peidong Wang, Ming Wang, Zhiming Ma, Xiaocui Yang, Shi Feng, Daling Wang, Yifei Zhang, Kaisong Song
分类: cs.CL, cs.AI
发布日期: 2024-12-19 (更新: 2025-02-13)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LANCE:一种基于LLM的持续自进化数据工程框架,提升模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自进化学习 数据工程 Qwen2 自主数据构建
📋 核心要点
- 现有LLM训练依赖专家标注数据,成本高昂且限制了模型性能的进一步提升。
- LANCE利用LLM自主生成、清洗、审查和标注数据,实现持续自进化训练。
- 实验表明,LANCE能有效提升Qwen2系列模型在多个基准测试上的性能。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中展现了卓越的能力,但进一步发展受到高质量训练数据缺乏的限制。此外,传统的训练方法过度依赖专家标注数据,限制了LLMs的性能上限。为了解决这个问题,我们提出了一种名为LANCE(LANguage models as Continuous self-Evolving data engineers)的新范式,使LLMs能够通过自主生成、清洗、审查和标注带有偏好信息的数据来训练自己。我们的方法表明,LLMs可以作为持续自进化的数据工程师,显著减少后训练数据构建的时间和成本。通过在Qwen2系列模型上进行迭代微调,我们验证了LANCE在各种任务中的有效性,表明它可以保持高质量的数据生成并持续提高模型性能。在多个基准维度上,LANCE使Qwen2-7B的平均得分提高了3.64,Qwen2-7B-Instruct的平均得分提高了1.75。这种具有自主数据构建的训练范式不仅减少了对人类专家或外部模型的依赖,而且确保了数据与人类偏好对齐,为未来能够超越人类能力的超智能系统的发展铺平了道路。
🔬 方法详解
问题定义:现有大型语言模型的训练严重依赖于人工标注的高质量数据,这不仅成本高昂,而且专家标注的数据可能存在偏差,限制了模型性能的进一步提升。此外,如何使模型更好地对齐人类偏好也是一个挑战。
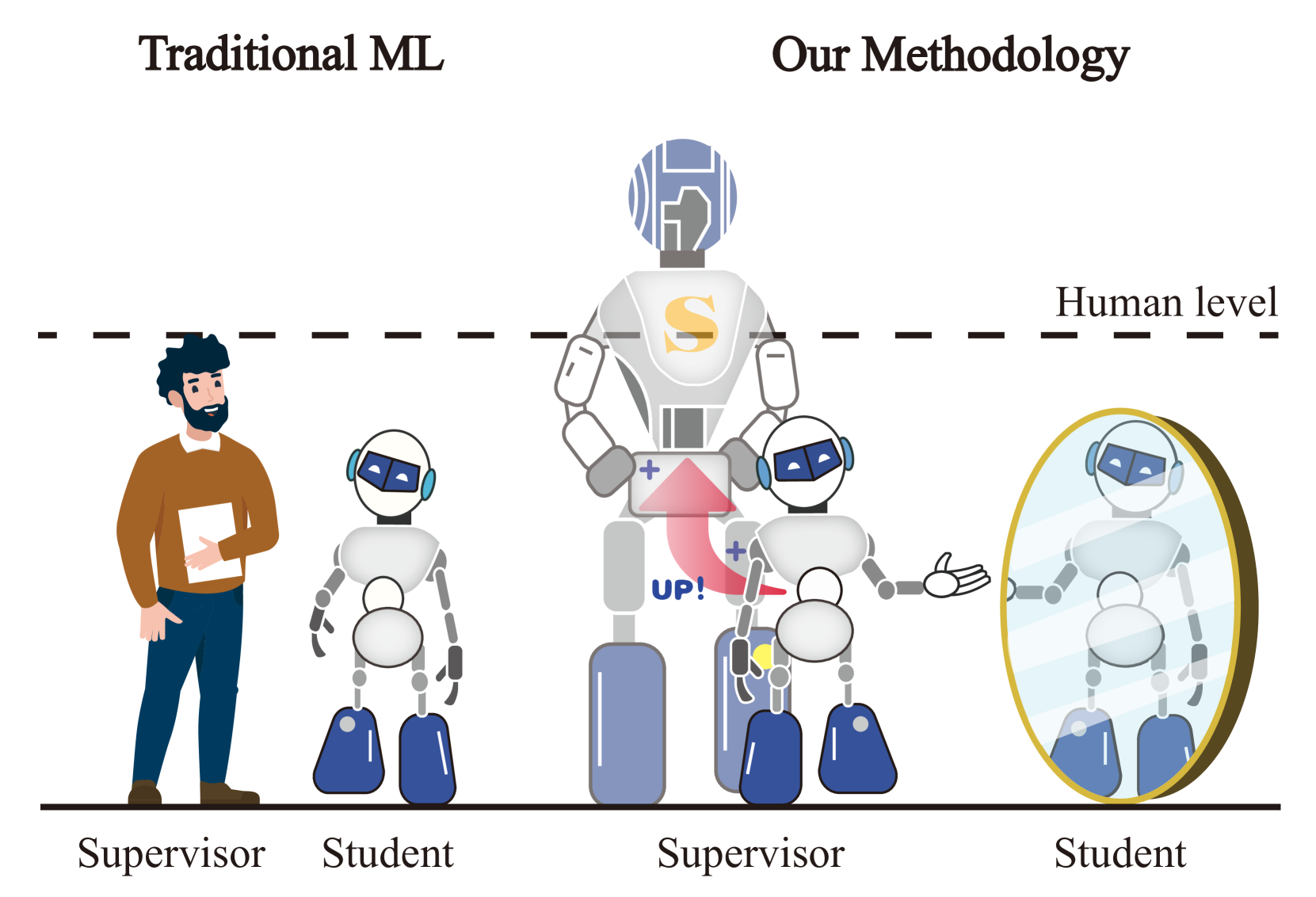
核心思路:LANCE的核心思想是让LLM扮演“数据工程师”的角色,使其能够自主地生成、清洗、审查和标注数据,从而实现持续的自进化训练。通过这种方式,可以降低对人工标注数据的依赖,并使模型更好地适应人类偏好。
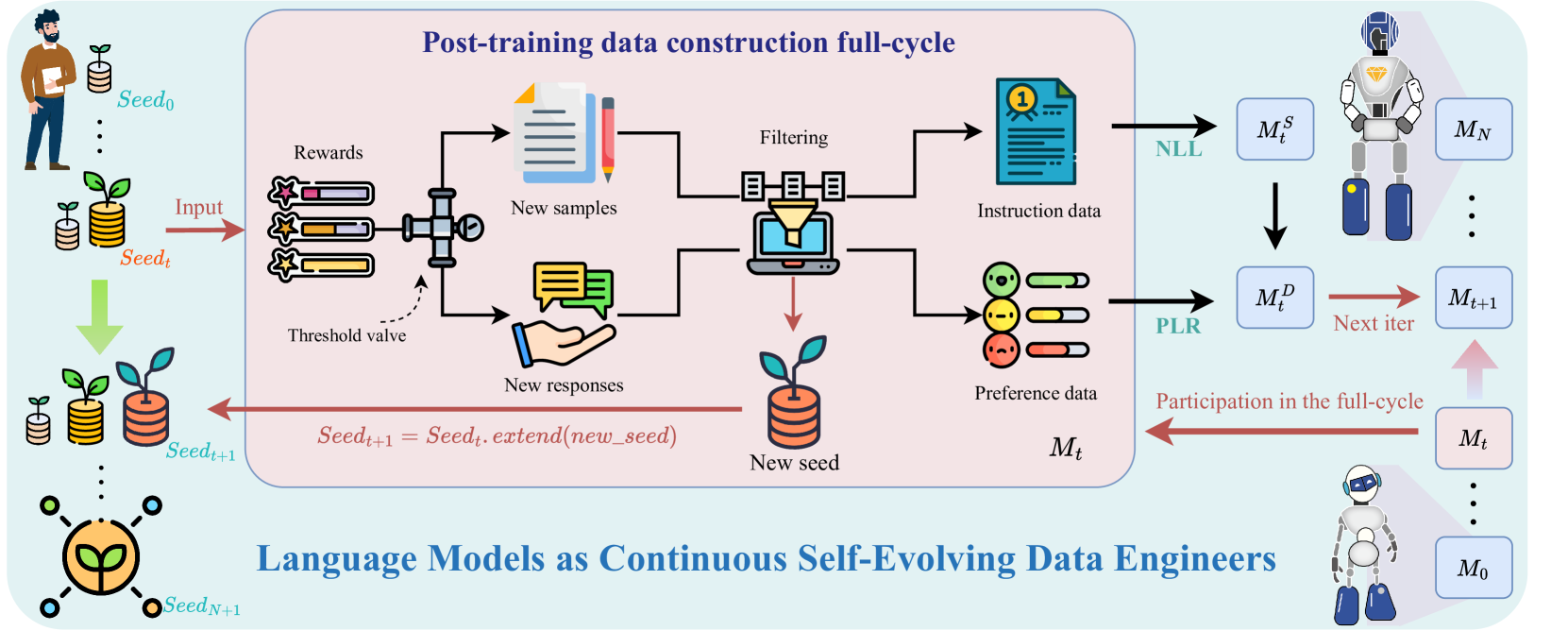
技术框架:LANCE框架包含以下几个主要阶段:1) 数据生成:LLM根据预设的任务和目标,自主生成训练数据。2) 数据清洗:LLM对生成的数据进行清洗,去除噪声和错误。3) 数据审查:LLM对清洗后的数据进行审查,评估其质量和相关性。4) 数据标注:LLM根据人类偏好对数据进行标注,为后续的训练提供指导。5) 模型训练:使用生成、清洗、审查和标注后的数据对LLM进行微调。这个过程是迭代进行的,LLM在每次迭代中不断改进其数据生成和处理能力。
关键创新:LANCE的关键创新在于它将LLM从一个被动接受数据的模型转变为一个主动创造数据的“数据工程师”。这种自主数据构建的训练范式不仅降低了对人工标注数据的依赖,而且使模型能够更好地适应人类偏好,从而实现持续的性能提升。
关键设计:LANCE框架的具体实现细节(如数据生成策略、清洗规则、审查标准和标注方法)会根据具体的任务和数据集进行调整。论文中使用了Qwen2系列模型进行实验,并针对不同的任务设计了相应的提示词和评估指标。此外,论文还探索了不同的数据生成和处理策略对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
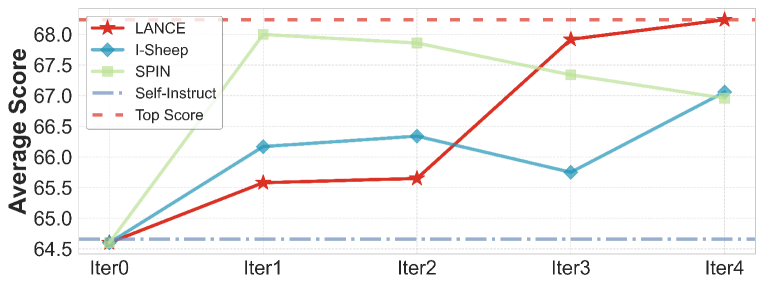
实验结果表明,LANCE能够显著提升Qwen2系列模型的性能。具体来说,LANCE使Qwen2-7B的平均得分提高了3.64,Qwen2-7B-Instruct的平均得分提高了1.75。这些结果表明,LANCE是一种有效的自主数据构建训练范式,能够持续提高LLM的性能。
🎯 应用场景
LANCE框架具有广泛的应用前景,可用于各种自然语言处理任务,如文本生成、机器翻译、对话系统等。它能够降低模型训练的成本,提高模型的性能,并使模型更好地对齐人类偏好。未来,LANCE有望应用于开发更智能、更可靠的AI系统。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities on various tasks, while the further evolvement is limited to the lack of high-quality training data. In addition, traditional training approaches rely too much on expert-labeled data, setting a ceiling on the performance of LLMs. To address this issue, we propose a novel paradigm named LANCE (LANguage models as Continuous self-Evolving data engineers) that enables LLMs to train themselves by autonomously generating, cleaning, reviewing, and annotating data with preference information. Our approach demonstrates that LLMs can serve as continuous self-evolving data engineers, significantly reducing the time and cost of the post-training data construction. Through iterative fine-tuning on Qwen2 series models, we validate the effectiveness of LANCE across various tasks, showing that it can maintain high-quality data generation and continuously improve model performance. Across multiple benchmark dimensions, LANCE results in an average score enhancement of 3.64 for Qwen2-7B and 1.75 for Qwen2-7B-Instruct. This training paradigm with autonomous data construction not only reduces the reliance on human experts or external models but also ensures that the data aligns with human preferences, paving the way for the development of future superintelligent systems that can exceed human capabilities. Codes are available at: https://github.com/Control-derek/LANCE.