ConfliBERT: A Language Model for Political Conflict
作者: Patrick T. Brandt, Sultan Alsarra, Vito J. D`Orazio, Dagmar Heintze, Latifur Khan, Shreyas Meher, Javier Osorio, Marcus Sianan
分类: cs.CL
发布日期: 2024-12-19
备注: 30 pages, 4 figures, 5 tables
💡 一句话要点
ConfliBERT:用于政治冲突事件抽取的专用语言模型,性能超越通用LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 政治冲突 自然语言处理 语言模型 信息抽取 领域专用模型
📋 核心要点
- 现有方法在从新闻报道和文本中提取政治暴力信息时,依赖于基于规则的方法,缺乏灵活性和泛化能力。
- ConfliBERT通过构建专门的语言模型,针对政治冲突领域进行优化,从而更有效地提取行动者和行动分类等信息。
- 实验结果表明,ConfliBERT在准确率、精确率和召回率方面优于通用LLM,并且推理速度更快,更适合实际应用。
📝 摘要(中文)
本文回顾了我们最近提出的ConfliBERT语言模型(Hu et al. 2022),该模型专门用于处理与政治和暴力相关的文本。ConfliBERT旨在从政治冲突相关的文本中提取行动者和行动分类信息。经过微调后,结果表明,在相关领域内,ConfliBERT在准确率、精确率和召回率方面均优于其他大型语言模型(LLM),如谷歌的Gemma 2 (9B)、Meta的Llama 3.1 (7B)和阿里巴巴的Qwen 2.5 (14B)。此外,ConfliBERT的速度比这些更通用的LLM快数百倍。这些结果通过来自BBC、re3d和全球恐怖主义数据库(GTD)的文本进行了验证。
🔬 方法详解
问题定义:论文旨在解决从文本中自动提取政治冲突相关信息的问题,特别是行动者和行动的分类。现有基于规则的方法难以适应复杂多变的文本,而通用大型语言模型在特定领域的表现和效率存在不足。
核心思路:论文的核心思路是构建一个专门针对政治冲突领域进行预训练和微调的语言模型ConfliBERT。通过领域相关的预训练,使模型能够更好地理解和处理政治冲突文本,从而提高信息提取的准确性和效率。
技术框架:ConfliBERT的技术框架基于Transformer架构,包含预训练和微调两个主要阶段。预训练阶段使用政治冲突相关的文本数据进行训练,使模型学习到领域相关的知识和语言模式。微调阶段则使用标注数据,针对特定的信息提取任务进行优化。
关键创新:ConfliBERT的关键创新在于其领域专用性。与通用LLM相比,ConfliBERT通过领域预训练,能够更好地理解和处理政治冲突文本,从而在相关任务上取得更好的性能。此外,ConfliBERT的模型规模相对较小,推理速度更快,更适合实际应用。
关键设计:论文中未提供关于具体参数设置、损失函数或网络结构的详细信息。预训练数据来自政治冲突相关的文本,微调阶段使用的标注数据包括行动者和行动的分类信息。具体的训练细节和超参数设置可能在Hu et al. 2022中有所描述,但本文摘要中未提及。
🖼️ 关键图片
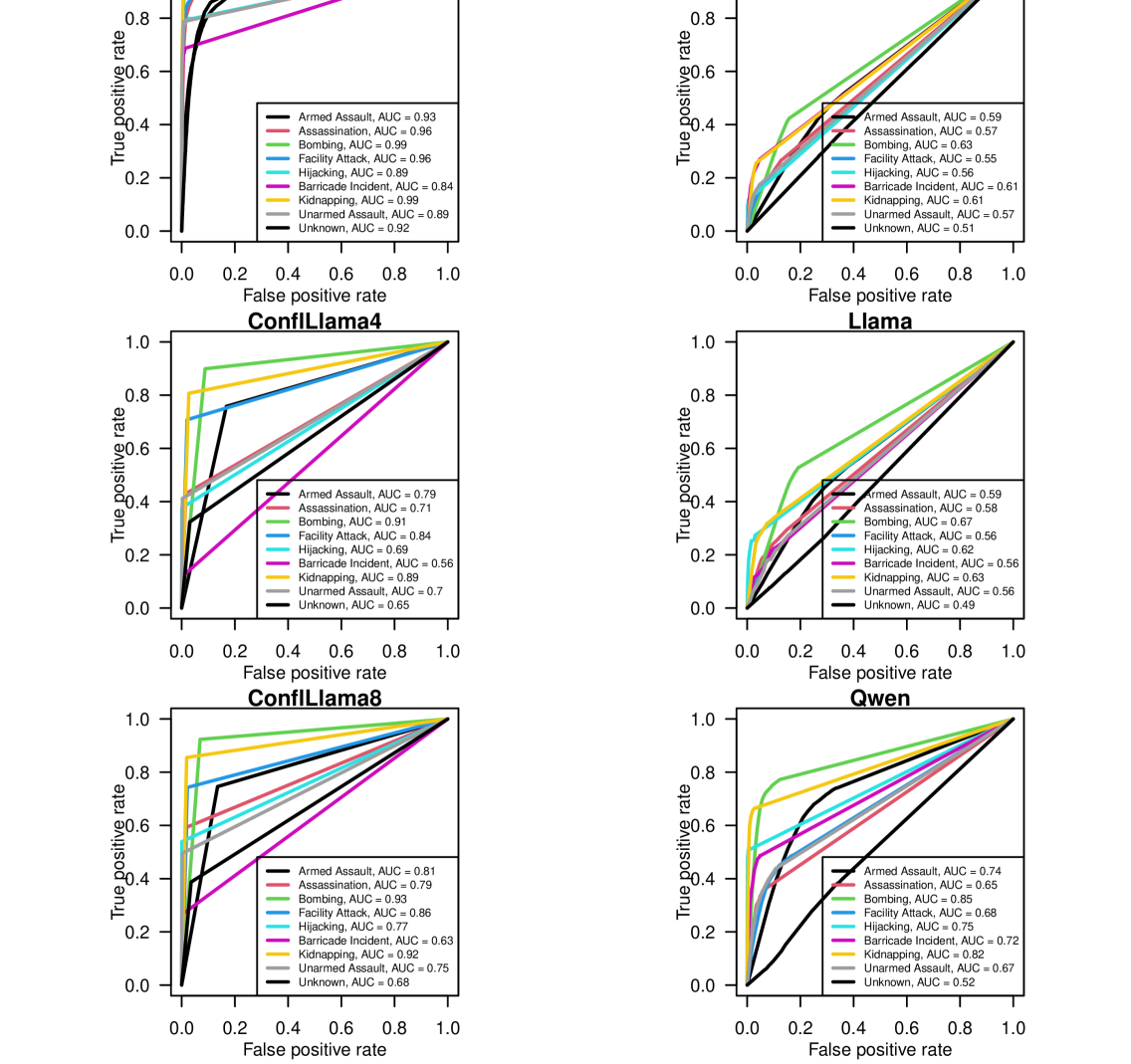
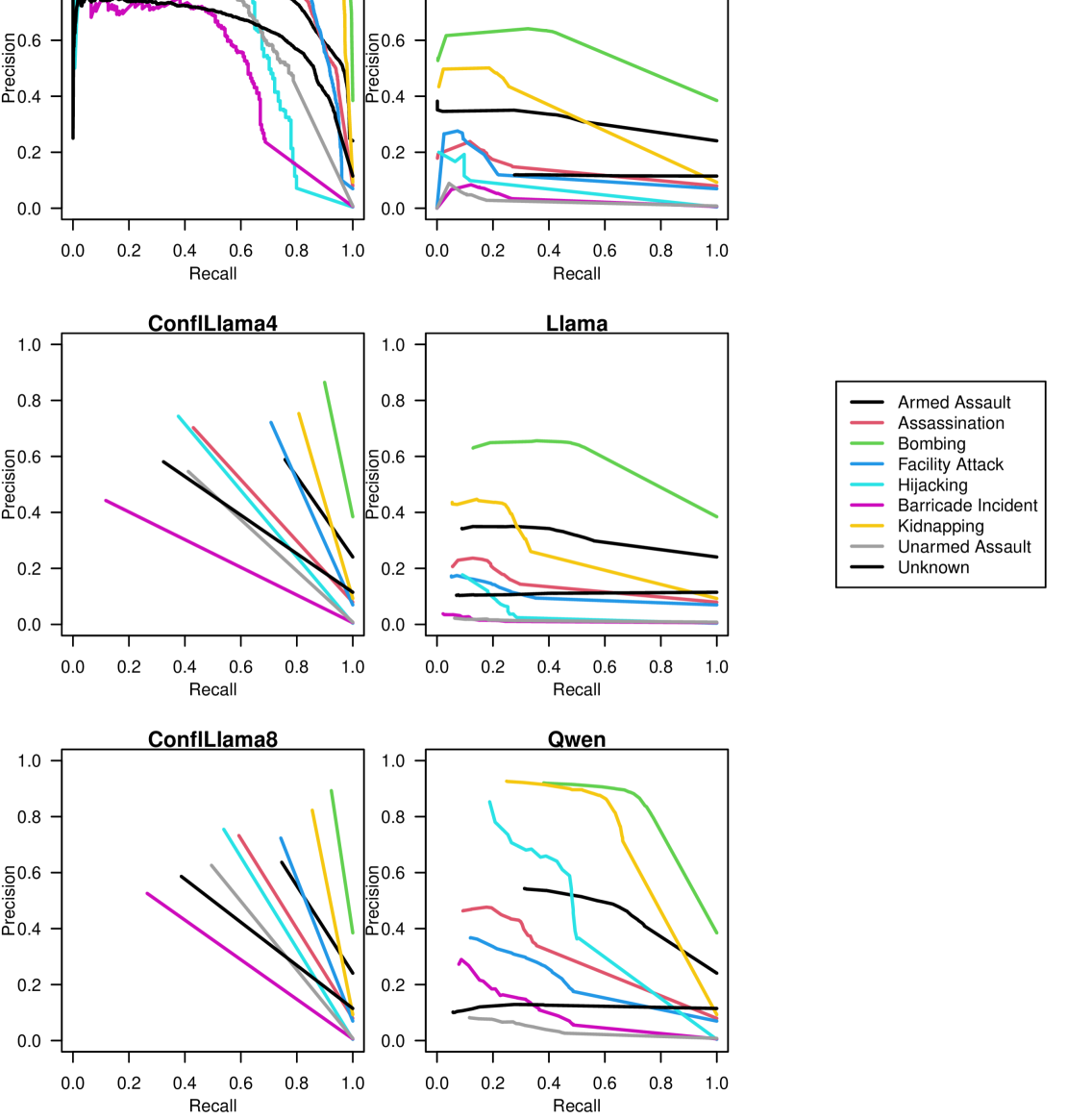

📊 实验亮点
ConfliBERT在政治冲突文本的信息提取任务中表现出色,优于Google的Gemma 2 (9B)、Meta的Llama 3.1 (7B)和阿里巴巴的Qwen 2.5 (14B)等通用LLM。此外,ConfliBERT的推理速度比这些大型模型快数百倍,使其更适合实际应用场景。实验数据来自BBC、re3d和全球恐怖主义数据库(GTD)。
🎯 应用场景
ConfliBERT可应用于政治风险评估、冲突预警、舆情分析等领域。通过自动提取和分析政治冲突相关信息,可以帮助决策者更好地了解局势,制定应对策略。该模型还可以用于构建政治冲突事件数据库,为学术研究提供数据支持。未来,可以进一步扩展ConfliBERT的应用范围,例如用于分析社交媒体上的政治冲突言论。
📄 摘要(原文)
Conflict scholars have used rule-based approaches to extract information about political violence from news reports and texts. Recent Natural Language Processing developments move beyond rigid rule-based approaches. We review our recent ConfliBERT language model (Hu et al. 2022) to process political and violence related texts. The model can be used to extract actor and action classifications from texts about political conflict. When fine-tuned, results show that ConfliBERT has superior performance in accuracy, precision and recall over other large language models (LLM) like Google's Gemma 2 (9B), Meta's Llama 3.1 (7B), and Alibaba's Qwen 2.5 (14B) within its relevant domains. It is also hundreds of times faster than these more generalist LLMs. These results are illustrated using texts from the BBC, re3d, and the Global Terrorism Dataset (GTD).