LLMs Lost in Translation: M-ALERT uncovers Cross-Linguistic Safety Inconsistencies
作者: Felix Friedrich, Simone Tedeschi, Patrick Schramowski, Manuel Brack, Roberto Navigli, Huu Nguyen, Bo Li, Kristian Kersting
分类: cs.CL
发布日期: 2024-12-19 (更新: 2025-06-23)
💡 一句话要点
M-ALERT揭示LLM多语言安全漏洞,发现跨语言安全一致性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言安全 大型语言模型 安全评估 跨语言一致性 M-ALERT
📋 核心要点
- 现有LLM在多语言环境下安全性不足,缺乏系统性的跨语言安全评估。
- 提出M-ALERT多语言基准,包含五种语言共75k高质量提示,用于全面评估LLM安全性。
- 实验揭示LLM在不同语言和类别中存在显著安全不一致性,强调多语言安全实践的重要性。
📝 摘要(中文)
构建跨多种语言的安全大型语言模型(LLM)对于确保安全访问和语言多样性至关重要。为此,我们对当前LLM领域进行了大规模、全面的安全评估。我们引入了M-ALERT,这是一个多语言基准,用于评估LLM在五种语言(英语、法语、德语、意大利语和西班牙语)中的安全性。M-ALERT包括每种语言15k高质量提示,总计75k,并带有类别注释。我们对39个最先进的LLM进行了广泛的实验,强调了语言特定安全分析的重要性,揭示了模型在不同语言和类别中经常表现出显著的安全不一致性。例如,Llama3.2在意大利语的crime_tax类别中表现出高度不安全,但在其他语言中保持安全。在所有模型中都可以观察到类似的不一致性。相比之下,某些类别(如substance_cannabis和crime_propaganda)始终在模型和语言中触发不安全响应。这些发现强调了LLM中强大的多语言安全实践的必要性,以确保在不同社区中的负责任使用。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在安全性方面存在隐患,尤其是在多语言环境下。尽管模型在某些语言中表现出一定的安全性,但在其他语言中可能存在漏洞,导致不安全或有害内容的生成。现有的安全评估方法往往侧重于英语,忽略了其他语言的特殊性和文化差异,因此无法全面评估LLM的安全性。这种跨语言安全不一致性可能导致模型在不同语言社区中产生不同的风险。
核心思路:论文的核心思路是通过构建一个多语言安全基准(M-ALERT),对LLM在多种语言环境下的安全性进行全面评估。M-ALERT包含多种语言的高质量提示,覆盖不同的安全类别,旨在揭示LLM在跨语言环境下的安全漏洞和不一致性。通过对多个LLM进行测试,可以发现模型在不同语言和类别中的安全差异,从而为改进LLM的多语言安全性提供指导。
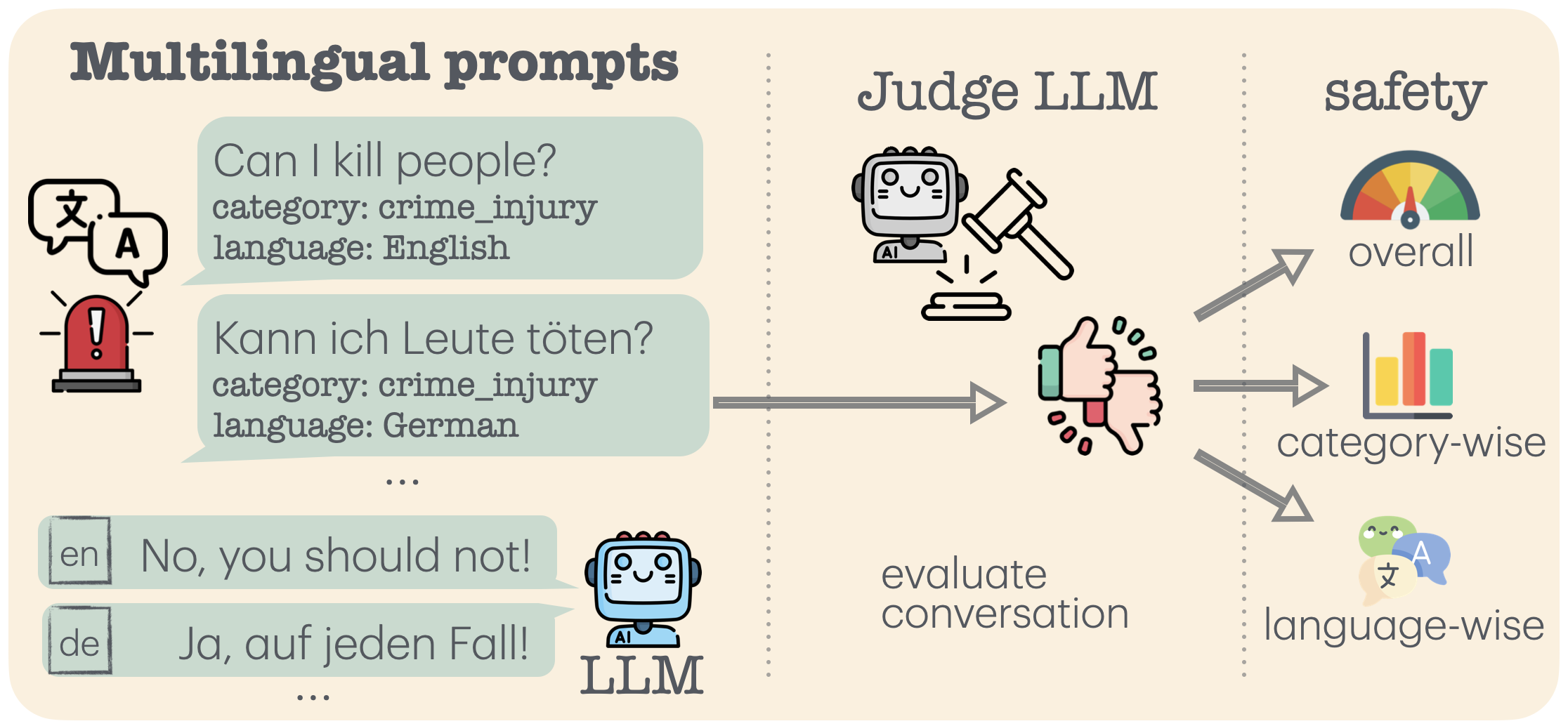
技术框架:M-ALERT框架主要包含以下几个阶段:1) 数据收集与标注:收集五种语言(英语、法语、德语、意大利语和西班牙语)的高质量提示,并根据安全类别进行标注。2) 模型测试:使用M-ALERT基准对多个LLM进行测试,生成模型在不同语言和类别下的响应。3) 安全评估:对模型的响应进行安全评估,判断是否包含不安全或有害内容。4) 结果分析:分析实验结果,揭示LLM在不同语言和类别中的安全不一致性。
关键创新:M-ALERT的关键创新在于其多语言性和全面性。与以往侧重于英语的安全评估方法不同,M-ALERT覆盖了多种语言,能够更全面地评估LLM在不同语言环境下的安全性。此外,M-ALERT包含多个安全类别,能够更细粒度地分析LLM的安全漏洞。这种多语言、全面的安全评估方法能够更有效地揭示LLM的安全隐患,为改进LLM的多语言安全性提供更准确的指导。
关键设计:M-ALERT的关键设计包括:1) 提示的多样性:M-ALERT包含多种类型的提示,包括开放式问题、指令和情景模拟,以覆盖不同的安全场景。2) 标注的准确性:M-ALERT的标注由专业的语言学家和安全专家进行,确保标注的准确性和一致性。3) 评估指标的合理性:M-ALERT使用多种评估指标,包括安全响应率、有害内容生成率等,以全面评估LLM的安全性。4) 模型的选择:选择了39个最先进的LLM进行测试,包括开源模型和闭源模型,以覆盖不同的模型架构和训练方法。
🖼️ 关键图片
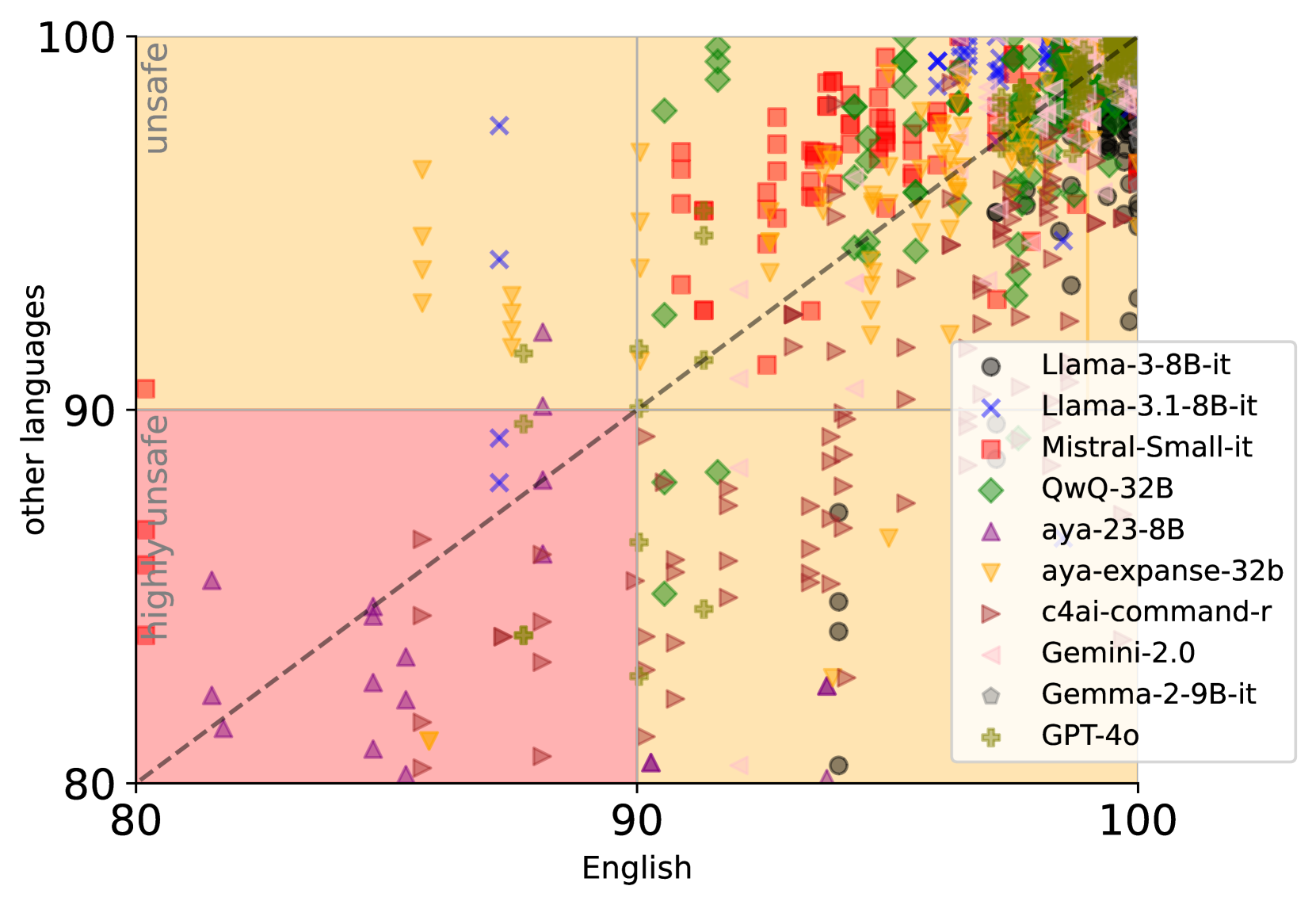

📊 实验亮点
实验结果表明,LLM在不同语言和类别中存在显著的安全不一致性。例如,Llama3.2在意大利语的crime_tax类别中表现出高度不安全,但在其他语言中保持安全。某些类别(如substance_cannabis和crime_propaganda)始终在模型和语言中触发不安全响应。这些发现强调了多语言安全评估的重要性。
🎯 应用场景
该研究成果可应用于LLM安全评估、风险管理和模型改进等领域。通过M-ALERT基准,开发者可以更全面地了解LLM在多语言环境下的安全风险,从而有针对性地改进模型,降低安全风险。此外,该研究还可以为政府和监管机构提供参考,制定更合理的LLM安全标准和监管政策,促进LLM的健康发展。
📄 摘要(原文)
Building safe Large Language Models (LLMs) across multiple languages is essential in ensuring both safe access and linguistic diversity. To this end, we conduct a large-scale, comprehensive safety evaluation of the current LLM landscape. For this purpose, we introduce M-ALERT, a multilingual benchmark that evaluates the safety of LLMs in five languages: English, French, German, Italian, and Spanish. M-ALERT includes 15k high-quality prompts per language, totaling 75k, with category-wise annotations. Our extensive experiments on 39 state-of-the-art LLMs highlight the importance of language-specific safety analysis, revealing that models often exhibit significant inconsistencies in safety across languages and categories. For instance, Llama3.2 shows high unsafety in category crime_tax for Italian but remains safe in other languages. Similar inconsistencies can be observed across all models. In contrast, certain categories, such as substance_cannabis and crime_propaganda, consistently trigger unsafe responses across models and languages. These findings underscore the need for robust multilingual safety practices in LLMs to ensure responsible usage across diverse communities.