Efficient Knowledge Injection in LLMs via Self-Distillation
作者: Kalle Kujanpää, Pekka Marttinen, Harri Valpola, Alexander Ilin
分类: cs.CL, cs.LG
发布日期: 2024-12-19 (更新: 2025-08-07)
备注: Preprint
💡 一句话要点
提出基于自蒸馏的prompt distillation方法,高效地将新知识注入大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识注入 自蒸馏 prompt distillation 微调 检索增强生成 知识学习
📋 核心要点
- 现有LLM在获取新知识时,依赖微调或RAG,但微调效果不如RAG。
- 论文提出prompt distillation,利用自蒸馏从自由文本中学习新知识,无需教师模型或结构化知识。
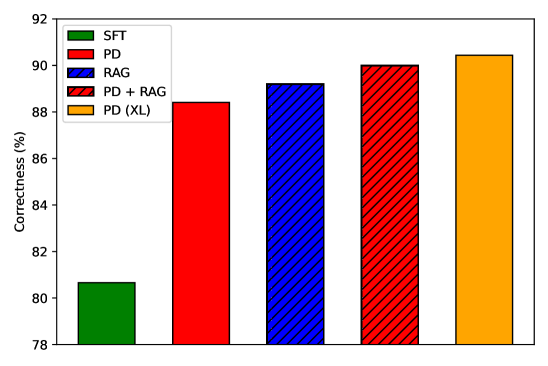
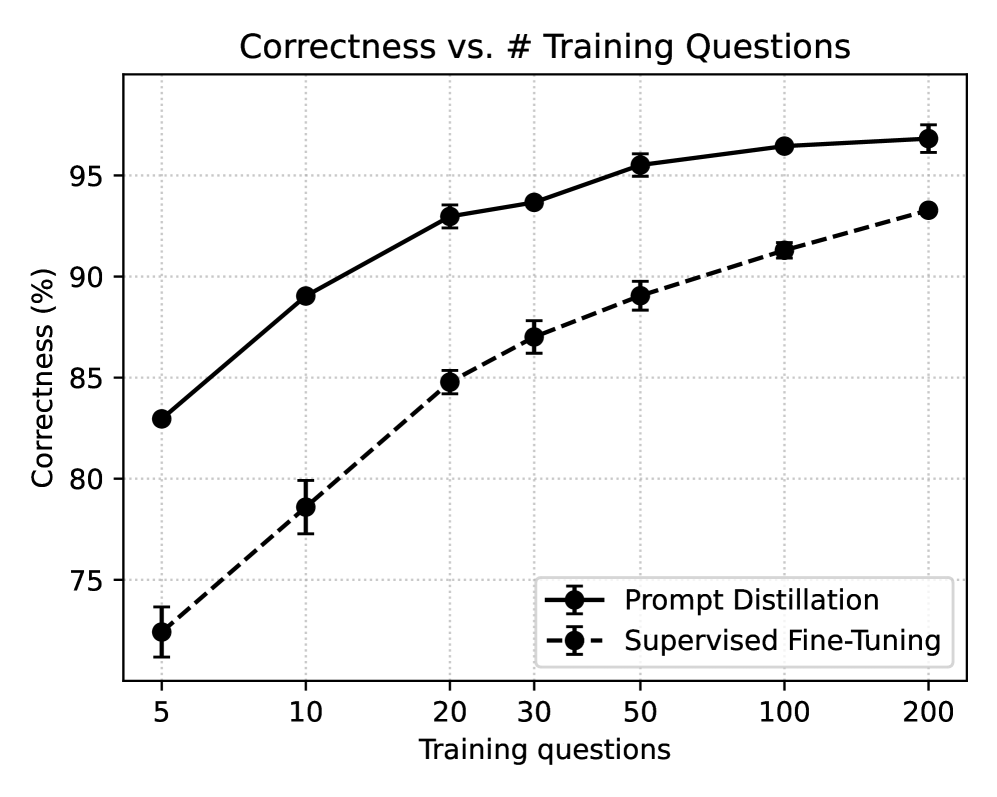
- 实验表明,prompt distillation在多种LLM上优于传统微调,甚至超越RAG。
📝 摘要(中文)
在许多实际应用中,大型语言模型(LLMs)需要获取预训练数据中不存在的新知识。有效利用这些知识通常依赖于监督微调或检索增强生成(RAG)。尽管RAG已成为知识注入的行业标准,但微调尚未取得可比的成功。本文提出利用prompt distillation,一种先前主要用于风格对齐和指令调整的基于自蒸馏的方法,从自由格式的文档中内化新的事实知识。与先前的方法不同,我们的方法既不需要更大的教师模型,也不需要结构化的知识格式。在多种LLM尺寸和模型系列中,我们表明prompt distillation优于标准监督微调,甚至可以超越RAG。我们分析了促成prompt distillation有效性的关键因素,并研究了它的扩展方式。
🔬 方法详解
问题定义:大型语言模型(LLMs)在实际应用中常常需要学习预训练数据中没有的新知识。传统的微调方法虽然可以注入知识,但效果往往不如检索增强生成(RAG)。现有的微调方法可能需要更大的教师模型或者结构化的知识表示,这限制了其应用范围和效率。因此,如何高效地将自由文本形式的新知识注入到LLM中是一个关键问题。
核心思路:论文的核心思路是利用prompt distillation,这是一种基于自蒸馏的方法。通过让LLM自身生成带有新知识的prompt,并用这些prompt来训练自身,从而实现知识的内化。这种方法不需要外部的教师模型,也不依赖于结构化的知识,因此更加灵活和高效。核心在于利用LLM自身的生成能力,创造高质量的训练数据。
技术框架:整体流程包括以下几个步骤:1)Prompt生成:使用LLM生成包含新知识的prompt。2)数据增强:对生成的prompt进行数据增强,例如通过同义词替换、句子重组等方式,增加训练数据的多样性。3)自蒸馏训练:使用增强后的prompt数据来微调LLM自身。目标是让LLM能够根据prompt生成正确的答案,从而内化prompt中包含的知识。
关键创新:最重要的技术创新点在于利用自蒸馏的方式进行知识注入,避免了对外部教师模型或结构化知识的依赖。与传统的微调方法相比,prompt distillation能够更有效地利用LLM自身的生成能力,从而实现更高效的知识学习。此外,该方法可以处理自由文本形式的知识,适用性更强。
关键设计:在prompt生成阶段,需要设计合适的prompt模板,以引导LLM生成包含新知识的prompt。在数据增强阶段,需要选择合适的增强策略,以保证增强后的数据质量。在自蒸馏训练阶段,需要选择合适的损失函数和优化器,以保证训练的稳定性和收敛性。论文中可能还涉及一些超参数的调整,例如学习率、batch size等,以达到最佳的训练效果。
🖼️ 关键图片
📊 实验亮点
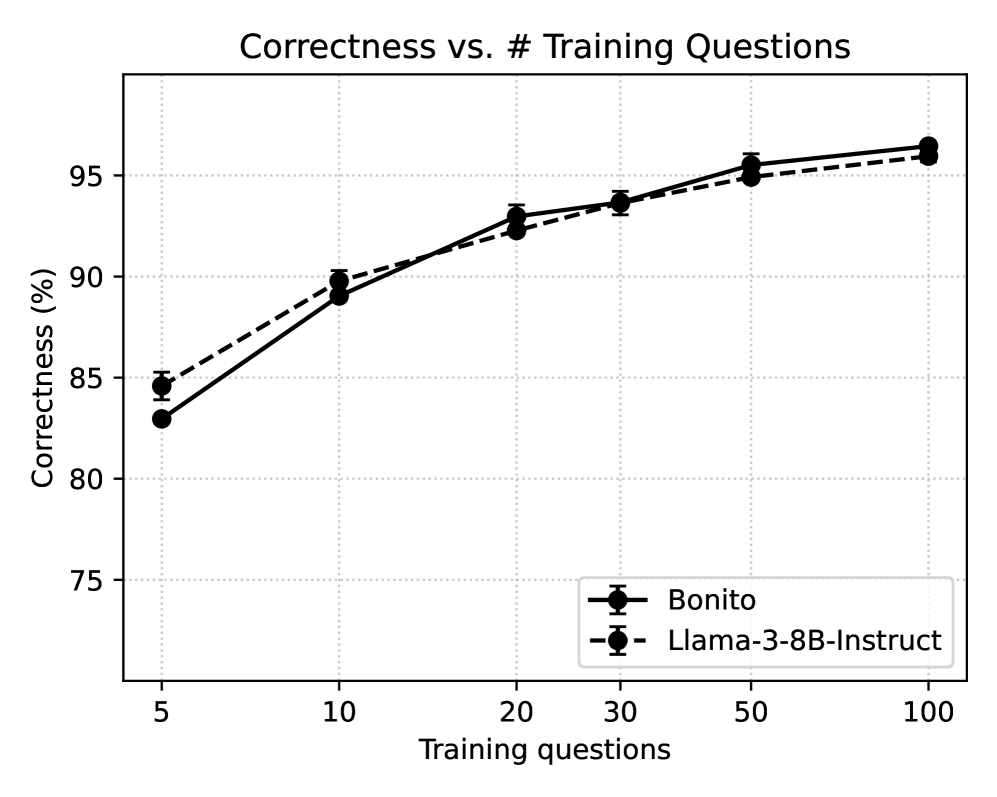
实验结果表明,prompt distillation在多种LLM尺寸和模型系列上均优于标准监督微调,甚至可以超越RAG。具体的性能提升幅度取决于数据集和模型,但总体趋势是prompt distillation能够更有效地将新知识注入到LLM中。论文还分析了prompt distillation有效性的关键因素,并研究了其扩展性。
🎯 应用场景
该研究成果可广泛应用于需要快速注入新知识的LLM应用场景,例如:快速更新的行业知识问答、特定领域的技术支持、个性化教育辅导等。通过prompt distillation,可以使LLM快速适应新的知识环境,提高其在特定任务中的性能,并降低对外部知识库的依赖,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
In many practical applications, large language models (LLMs) need to acquire new knowledge not present in their pre-training data. Efficiently leveraging this knowledge usually relies on supervised fine-tuning or retrieval-augmented generation (RAG). Although RAG has emerged as the industry standard for knowledge injection, fine-tuning has not yet achieved comparable success. This paper proposes utilizing prompt distillation, a self-distillation-based method previously explored primarily for style alignment and instruction tuning, to internalize new factual knowledge from free-form documents. Unlike prior methods, our approach requires neither larger teacher models nor structured knowledge formats. Across multiple LLM sizes and model families, we show that prompt distillation outperforms standard supervised fine-tuning and can even surpass RAG. We analyze the key factors contributing to prompt distillation's effectiveness and examine how it scales.