ResoFilter: Fine-grained Synthetic Data Filtering for Large Language Models through Data-Parameter Resonance Analysis
作者: Zeao Tu, Xiangdi Meng, Yu He, Zihan Yao, Tianyu Qi, Jun Liu, Ming Li
分类: cs.CL
发布日期: 2024-12-19 (更新: 2025-01-24)
备注: Accepted by NAACL 2025 Findings
💡 一句话要点
ResoFilter:通过数据-参数共振分析实现大语言模型精细化合成数据过滤
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据增强 合成数据 数据过滤 模型微调
📋 核心要点
- 现有数据增强方法生成的合成数据质量难以评估,缺乏明确的指标来衡量数据特征。
- ResoFilter通过微调过程提取数据-参数特征,利用模型权重表征数据,从而实现数据选择和质量评估。
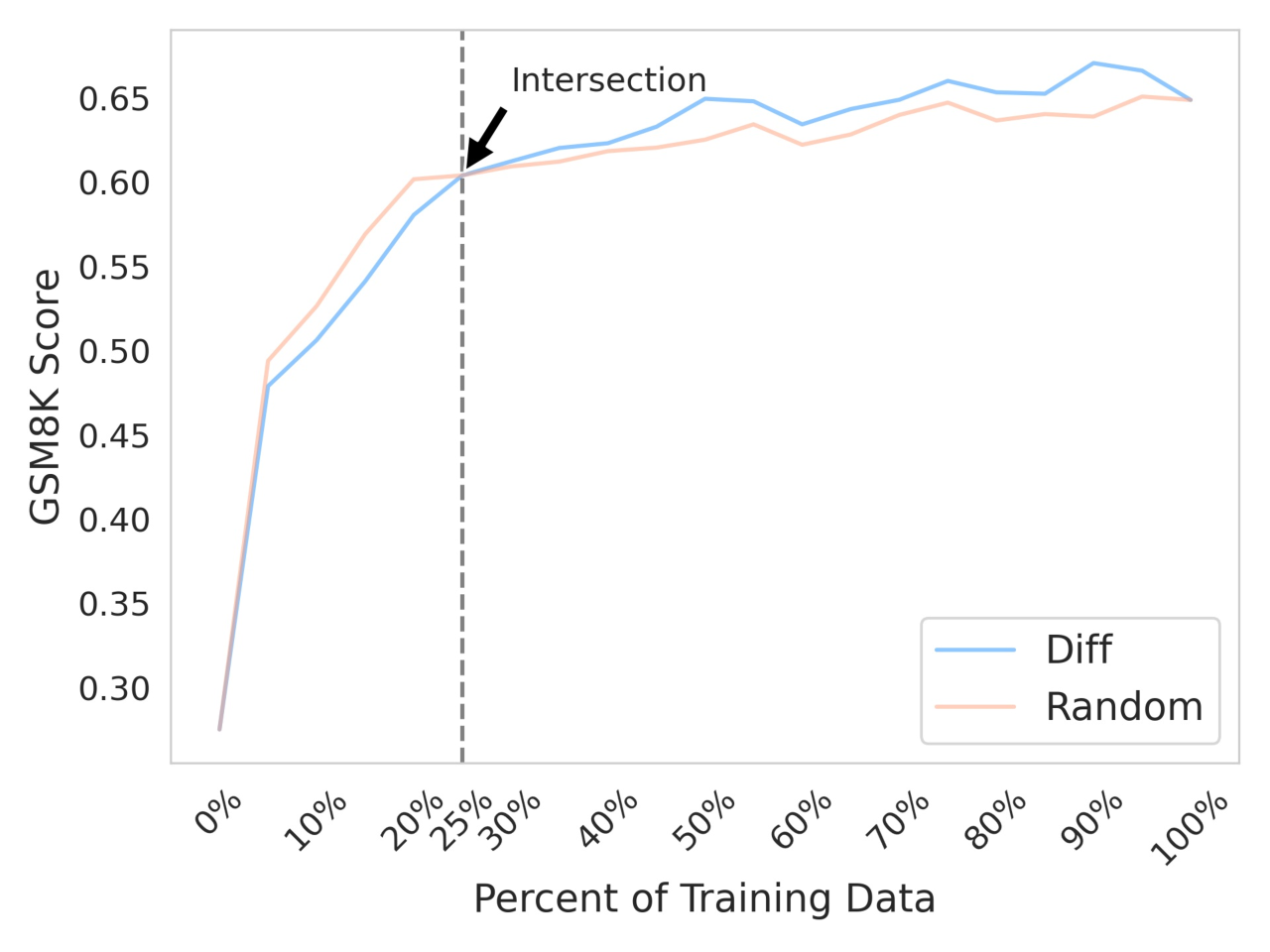
- 实验表明,ResoFilter仅用一半数据即可达到全量微调的效果,并在不同模型和领域展现出良好的泛化性。
📝 摘要(中文)
大型语言模型(LLM)在各个领域都表现出了卓越的有效性,利用GPT进行合成数据生成的数据增强方法变得越来越普遍。然而,增强数据的质量和效用仍然值得怀疑,并且当前的方法缺乏评估数据特征的明确指标。为了应对这些挑战,我们提出了一种新颖的方法ResoFilter,它集成了模型、数据和任务来改进数据集。ResoFilter利用微调过程来获得数据选择的数据-参数特征,通过模型权重表示数据特征,从而提供更好的可解释性。我们的实验表明,ResoFilter仅使用一半的数据在数学任务中就实现了与全尺寸微调相当的结果,并且在不同的模型和领域中表现出强大的泛化能力。该方法为构建合成数据集和评估高质量数据提供了有价值的见解,为增强数据增强技术和提高LLM的训练数据集质量提供了一个有希望的解决方案。为了可重复性,我们将在接受后发布我们的代码和数据。
🔬 方法详解
问题定义:论文旨在解决大语言模型训练中,如何有效过滤和选择高质量合成数据的问题。现有方法缺乏对合成数据质量的有效评估手段,导致训练效果不稳定,且计算资源浪费。现有方法难以区分对模型训练有益和有害的合成数据,影响模型性能。
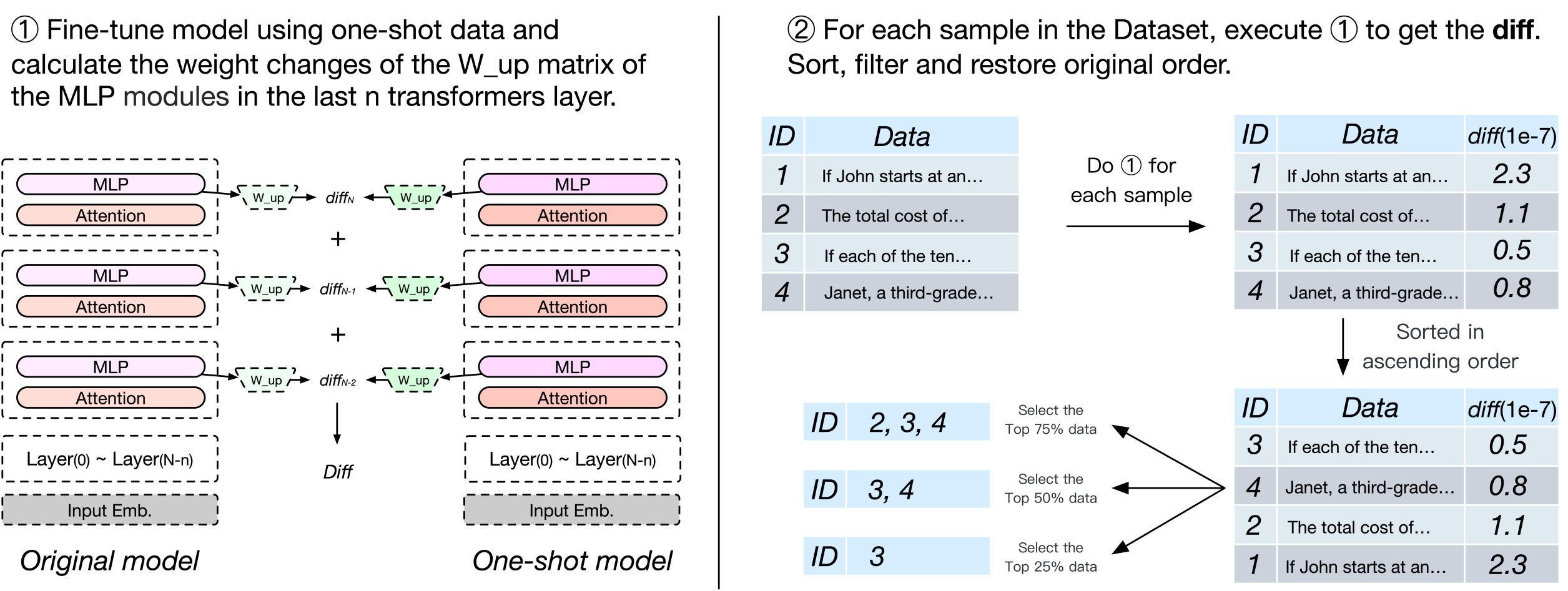
核心思路:ResoFilter的核心思想是利用模型微调过程中数据与模型参数之间的“共振”关系来评估数据质量。高质量的数据应该能更有效地影响模型参数的变化,从而在数据-参数空间中留下更明显的特征。通过分析这些特征,可以筛选出对模型训练更有价值的合成数据。
技术框架:ResoFilter包含以下主要阶段:1) 数据合成:使用GPT等生成模型创建合成数据集。2) 微调训练:使用少量数据对LLM进行微调,记录模型参数的变化。3) 数据-参数特征提取:分析微调过程中模型参数的变化,提取每个数据样本对应的“数据-参数特征”。4) 数据过滤:基于提取的特征,使用分类器或排序算法对数据进行过滤,选择高质量的合成数据。5) 最终训练:使用过滤后的数据对LLM进行最终训练。
关键创新:ResoFilter的关键创新在于将数据质量评估与模型训练过程紧密结合,通过分析数据对模型参数的影响来判断数据质量。与传统的基于数据本身特征的评估方法相比,ResoFilter更能反映数据对模型训练的实际价值。此外,ResoFilter提供了一种可解释性更强的数据评估方法,通过模型权重变化来理解数据特征。
关键设计:ResoFilter的关键设计包括:1) 数据-参数特征的定义:如何有效地提取和表示数据对模型参数的影响是关键。论文可能采用了梯度、激活值或其他模型内部状态作为特征。2) 过滤算法的选择:可以使用分类器(如SVM、逻辑回归)或排序算法(如RankNet)来对数据进行过滤。3) 微调策略:微调的学习率、batch size、epoch数等参数会影响数据-参数特征的提取效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ResoFilter在数学任务中仅使用一半的合成数据,就能达到与全量数据微调相当的性能。此外,ResoFilter在不同的模型和领域中表现出良好的泛化能力,证明了其有效性和通用性。具体性能提升数据未知,需要在论文中查找。
🎯 应用场景
ResoFilter可广泛应用于各种需要数据增强的大语言模型训练场景,例如数学推理、代码生成、文本摘要等。该方法能够有效提升合成数据的利用率,降低训练成本,并提高模型的泛化能力。未来,ResoFilter可以扩展到其他类型的数据增强方法,例如对抗训练、回译等,并应用于更广泛的机器学习任务。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable effectiveness across various domains, with data augmentation methods utilizing GPT for synthetic data generation becoming prevalent. However, the quality and utility of augmented data remain questionable, and current methods lack clear metrics for evaluating data characteristics. To address these challenges, we propose ResoFilter, a novel method that integrates models, data, and tasks to refine datasets. ResoFilter leverages the fine-tuning process to obtain Data-Parameter features for data selection, offering improved interpretability by representing data characteristics through model weights. Our experiments demonstrate that ResoFilter achieves comparable results to full-scale fine-tuning using only half the data in mathematical tasks and exhibits strong generalization across different models and domains. This method provides valuable insights for constructing synthetic datasets and evaluating high-quality data, offering a promising solution for enhancing data augmentation techniques and improving training dataset quality for LLMs. For reproducibility, we will release our code and data upon acceptance.