Disentangling Reasoning Tokens and Boilerplate Tokens For Language Model Fine-tuning
作者: Ziang Ye, Zhenru Zhang, Yang Zhang, Jianxin Ma, Junyang Lin, Fuli Feng
分类: cs.CL
发布日期: 2024-12-19
💡 一句话要点
提出RFT方法,通过解耦推理和样板 tokens,提升LLM在agent任务上的微调效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Agent任务 微调 推理tokens 样板tokens Shuffle-Aware Discriminator 自适应权重
📋 核心要点
- 现有LLM微调方法平等对待所有tokens,忽略了推理tokens和样板tokens的重要性差异。
- 提出Shuffle-Aware Discriminator (SHAD)区分推理和样板tokens,核心思想是基于打乱输入输出后的可预测性差异。
- Reasoning-highlighted Fine-Tuning (RFT)方法自适应地强调推理tokens,显著提升了微调性能。
📝 摘要(中文)
在使用agent-task数据集增强大型语言模型(LLM)的agent能力时,当前方法通常平等对待样本中的所有tokens。然而,我们认为不同角色的tokens——特别是推理tokens和样板tokens(例如,控制输出格式的tokens)——在重要性和学习复杂性上存在显著差异,因此需要对其进行解耦和区别对待。为了解决这个问题,我们提出了一种新颖的Shuffle-Aware Discriminator (SHAD)用于自适应token区分。SHAD通过利用在样本间打乱输入-输出组合后观察到的可预测性差异来对tokens进行分类:由于样板tokens在样本中的重复性,它们保持可预测性,而推理tokens则不然。使用SHAD,我们提出了推理高亮微调(Reasoning-highlighted Fine-Tuning, RFT)方法,该方法在微调期间自适应地强调推理tokens,与常见的监督微调(SFT)相比,产生了显著的性能提升。
🔬 方法详解
问题定义:现有的大语言模型微调方法在处理Agent任务时,通常将所有tokens一视同仁,没有区分不同类型token的重要性。然而,推理tokens(包含解决问题的关键信息)和样板tokens(例如,格式化输出的固定文本)在学习难度和对模型性能的贡献上存在显著差异。这种不区分对待的方式可能导致模型在学习过程中被大量冗余的样板tokens分散注意力,从而影响其推理能力的提升。
核心思路:本文的核心思路是解耦推理tokens和样板tokens,并在微调过程中更加关注推理tokens。作者认为,样板tokens在不同的训练样本中具有较高的重复性,因此即使打乱输入输出的对应关系,模型仍然可以较容易地预测这些tokens。相反,推理tokens与特定的输入输出关系紧密相关,打乱对应关系后,模型预测这些tokens的难度会显著增加。基于这一观察,作者设计了一种Shuffle-Aware Discriminator (SHAD)来区分这两种类型的tokens。
技术框架:RFT方法主要包含两个阶段:首先,利用SHAD对训练数据中的tokens进行分类,区分出推理tokens和样板tokens。然后,在微调阶段,RFT方法会自适应地增加推理tokens的权重,从而使模型更加关注这些重要的tokens。整体流程可以概括为:(1) 使用Agent任务数据集;(2) 利用SHAD区分推理tokens和样板tokens;(3) 使用RFT方法进行微调,其中推理tokens具有更高的权重。
关键创新:该论文的关键创新在于提出了Shuffle-Aware Discriminator (SHAD),这是一种新颖的token分类器,能够有效地解耦推理tokens和样板tokens。与现有方法不同,SHAD不需要人工标注或预定义的规则,而是通过分析tokens在打乱输入输出对应关系后的可预测性来自动区分不同类型的tokens。这种自适应的token区分方法更加灵活和通用,可以应用于不同的Agent任务和数据集。
关键设计:SHAD的核心在于衡量tokens在打乱输入输出对应关系后的可预测性。具体来说,对于每个token,SHAD会计算其在原始数据和打乱数据上的预测概率,并根据这两个概率之间的差异来判断该token是推理token还是样板token。RFT方法在微调阶段通过调整交叉熵损失函数的权重来实现对推理tokens的强调。推理tokens的权重会根据SHAD的输出进行自适应调整,确保模型能够更加关注这些重要的tokens。
🖼️ 关键图片

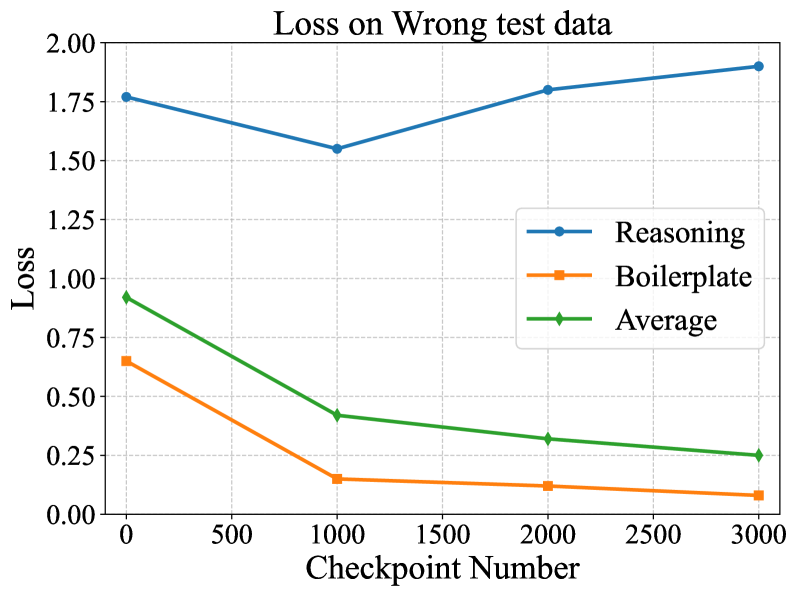

📊 实验亮点
实验结果表明,RFT方法在多个Agent任务数据集上都取得了显著的性能提升。例如,在某个数据集上,RFT方法相比于传统的监督微调(SFT)方法,性能提升了超过5%。此外,作者还进行了消融实验,验证了SHAD和自适应权重调整策略的有效性。实验结果表明,SHAD能够准确地识别推理tokens,并且自适应地增加推理tokens的权重能够有效地提升模型的推理能力。
🎯 应用场景
该研究成果可广泛应用于各种需要利用大型语言模型进行Agent任务的场景,例如智能客服、自动代码生成、机器人控制等。通过提升LLM在Agent任务上的推理能力,可以显著提高这些应用的性能和用户体验。此外,该方法还可以推广到其他类型的任务,例如文本摘要、机器翻译等,通过区分关键信息和冗余信息,提升模型的生成质量。
📄 摘要(原文)
When using agent-task datasets to enhance agent capabilities for Large Language Models (LLMs), current methodologies often treat all tokens within a sample equally. However, we argue that tokens serving different roles - specifically, reasoning tokens versus boilerplate tokens (e.g., those governing output format) - differ significantly in importance and learning complexity, necessitating their disentanglement and distinct treatment. To address this, we propose a novel Shuffle-Aware Discriminator (SHAD) for adaptive token discrimination. SHAD classifies tokens by exploiting predictability differences observed after shuffling input-output combinations across samples: boilerplate tokens, due to their repetitive nature among samples, maintain predictability, whereas reasoning tokens do not. Using SHAD, we propose the Reasoning-highlighted Fine-Tuning (RFT) method, which adaptively emphasizes reasoning tokens during fine-tuning, yielding notable performance gains over common Supervised Fine-Tuning (SFT).