Each Fake News is Fake in its Own Way: An Attribution Multi-Granularity Benchmark for Multimodal Fake News Detection
作者: Hao Guo, Zihan Ma, Zhi Zeng, Minnan Luo, Weixin Zeng, Jiuyang Tang, Xiang Zhao
分类: cs.CL, cs.AI
发布日期: 2024-12-19
💡 一句话要点
构建多粒度属性基准数据集AMG,并提出多粒度线索对齐模型MGCM,用于多模态假新闻检测与溯源。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态假新闻检测 多粒度学习 属性预测 线索对齐 数据集构建
📋 核心要点
- 现有数据集仅提供真假二元标签,忽略了多模态假新闻类型的多样性及其内在的虚假模式。
- 提出多粒度线索对齐模型MGCM,通过对齐不同粒度的线索,实现多模态假新闻的检测和溯源。
- 构建了具有属性的多粒度多模态假新闻检测数据集AMG,实验证明其具有挑战性,并为未来研究提供了新方向。
📝 摘要(中文)
社交平台在促进信息获取的同时,也充斥着大量的虚假新闻,造成了负面影响。自动多模态假新闻检测是一项有价值的研究。现有的多模态假新闻数据集仅提供真实或虚假的二元标签。然而,真实的新闻都是相似的,而每条虚假新闻都有其独特的虚假之处。这些数据集未能反映各种类型多模态假新闻的混合性质。为了弥补这一差距,我们构建了一个具有属性的多粒度多模态假新闻检测数据集AMG,揭示了其内在的虚假模式。此外,我们提出了一个多粒度线索对齐模型MGCM,以实现多模态假新闻检测和溯源。实验结果表明,AMG是一个具有挑战性的数据集,其属性设置为未来的研究开辟了新的途径。
🔬 方法详解
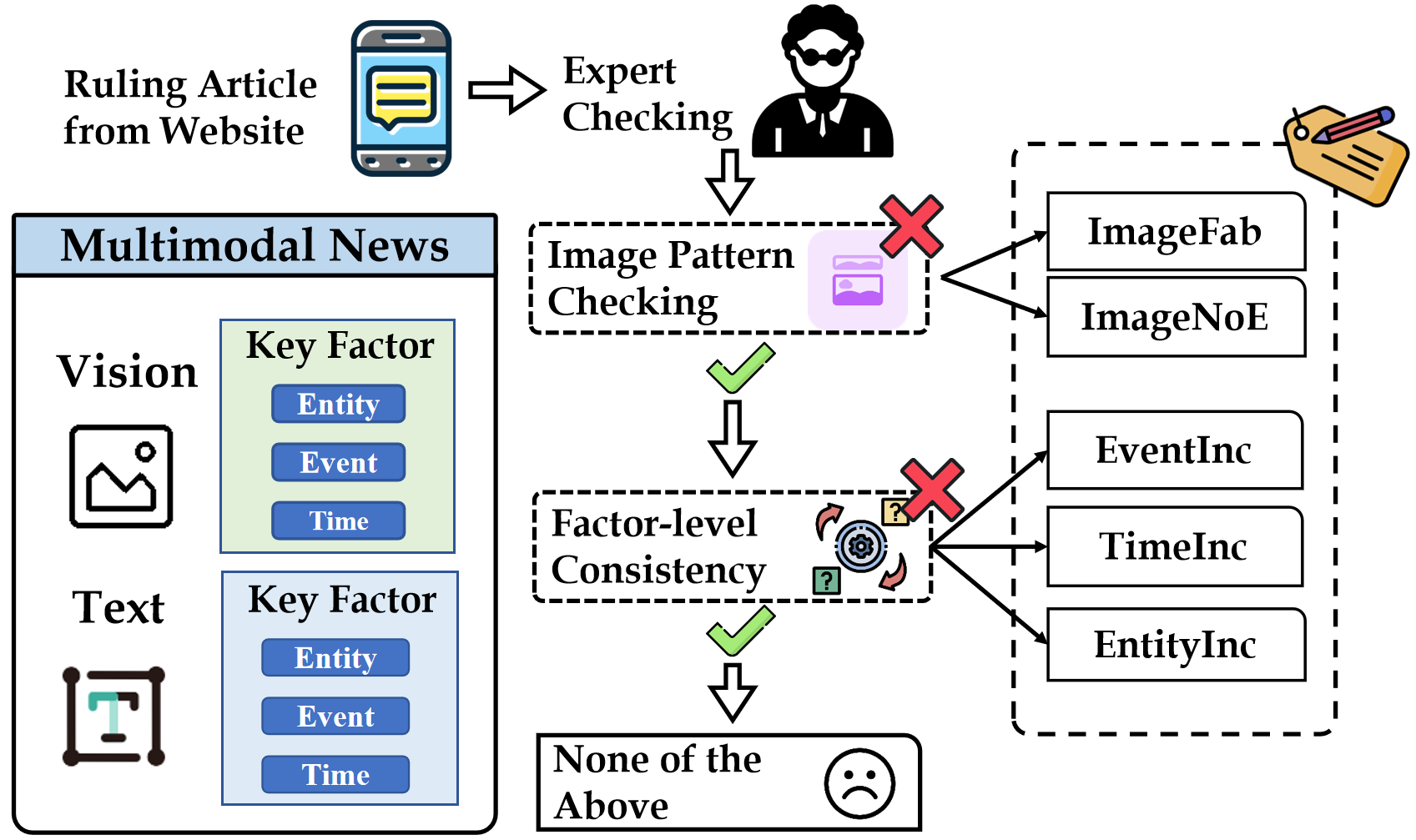
问题定义:现有的多模态假新闻检测数据集主要存在的问题是只提供真/假二元标签,忽略了不同类型假新闻之间存在的差异性。真实新闻往往具有相似的特征,而每条假新闻的造假方式各不相同。因此,简单地将假新闻视为一个整体进行训练,无法充分挖掘其内在的虚假模式,导致模型泛化能力不足。
核心思路:论文的核心思路是构建一个更细粒度的数据集,不仅标注新闻的真假,还标注其属于哪种类型的假新闻。同时,设计一个能够捕捉不同粒度线索的模型,从而更准确地识别和溯源假新闻。通过多粒度的属性标注,模型可以学习到不同类型假新闻的独特特征,从而提高检测的准确性和可解释性。
技术框架:论文提出的多粒度线索对齐模型(MGCM)主要包含以下几个模块:1) 特征提取模块:分别提取文本和图像的特征表示。2) 多粒度属性预测模块:预测新闻属于不同粒度属性的概率。3) 线索对齐模块:将文本、图像和属性特征进行对齐,学习它们之间的关联关系。4) 最终分类模块:基于对齐后的特征,预测新闻的真假。整个框架通过端到端的方式进行训练。
关键创新:论文的关键创新点在于:1) 构建了一个具有属性的多粒度多模态假新闻检测数据集AMG,该数据集不仅标注了新闻的真假,还标注了其属于哪种类型的假新闻。2) 提出了一个多粒度线索对齐模型MGCM,该模型能够捕捉不同粒度的线索,从而更准确地识别和溯源假新闻。与现有方法相比,MGCM能够更好地利用多模态信息和属性信息,从而提高检测的准确性和可解释性。
关键设计:在数据集构建方面,论文设计了多粒度的属性标注体系,包括细粒度的具体造假原因和粗粒度的造假类型。在模型设计方面,线索对齐模块采用了注意力机制,从而能够更好地捕捉不同模态和属性之间的关联关系。损失函数方面,采用了交叉熵损失函数来训练属性预测模块和最终分类模块。具体网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的AMG数据集具有挑战性,现有模型在该数据集上的表现还有很大的提升空间。MGCM模型在AMG数据集上取得了显著的性能提升,相较于基线模型,在假新闻检测和属性预测方面均有明显优势。这验证了多粒度属性标注和线索对齐方法的有效性。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻聚合网站等,用于自动检测和溯源虚假新闻,从而减少虚假信息传播带来的负面影响。通过识别假新闻的类型和原因,可以帮助用户更好地辨别信息的真伪,提高信息素养。此外,该研究还可以为相关监管部门提供技术支持,辅助其进行网络信息治理。
📄 摘要(原文)
Social platforms, while facilitating access to information, have also become saturated with a plethora of fake news, resulting in negative consequences. Automatic multimodal fake news detection is a worthwhile pursuit. Existing multimodal fake news datasets only provide binary labels of real or fake. However, real news is alike, while each fake news is fake in its own way. These datasets fail to reflect the mixed nature of various types of multimodal fake news. To bridge the gap, we construct an attributing multi-granularity multimodal fake news detection dataset \amg, revealing the inherent fake pattern. Furthermore, we propose a multi-granularity clue alignment model \our to achieve multimodal fake news detection and attribution. Experimental results demonstrate that \amg is a challenging dataset, and its attribution setting opens up new avenues for future research.