LDC: Learning to Generate Research Idea with Dynamic Control
作者: Ruochen Li, Liqiang Jing, Chi Han, Jiawei Zhou, Xinya Du
分类: cs.CL, cs.AI
发布日期: 2024-12-19 (更新: 2025-11-14)
💡 一句话要点
提出LDC框架,通过动态控制生成高质量科研想法,平衡新颖性、可行性和有效性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科研想法生成 大型语言模型 可控强化学习 监督微调 多维奖励模型 维度控制 新颖性 可行性
📋 核心要点
- 现有方法依赖提示工程,难以生成同时满足新颖性、可行性和有效性的高质量科研想法。
- LDC框架采用两阶段方法,结合监督微调和可控强化学习,动态平衡多个维度。
- 实验结果表明,LDC框架能够生成高质量的科研想法,并在新颖性、可行性和有效性之间取得平衡。
📝 摘要(中文)
大型语言模型(LLMs)在自动化科研想法生成方面展现出潜力。现有方法主要依赖提示工程,但生成的想法往往与专家标准不符,即缺乏新颖性、可行性和有效性,这三个维度被研究界广泛认为是高质量想法的关键子维度。此外,由于这些维度之间存在固有的权衡,平衡它们仍然具有挑战性。为了解决这些局限性,我们提出了第一个采用两阶段方法的框架,结合了监督微调(SFT)和可控强化学习(RL)来完成这项任务。在SFT阶段,模型从研究论文及其对应的后续想法对中学习基础模式。在RL阶段,由细粒度反馈引导的多维奖励模型评估和优化模型在关键维度上的表现。在推理过程中,由句子级解码器协调的维度控制器能够动态地、上下文感知地引导想法生成过程。我们的框架为科研想法生成提供了一种平衡的方法,通过动态地调整新颖性、可行性和有效性之间的权衡,在实验中实现了高质量的结果。
🔬 方法详解
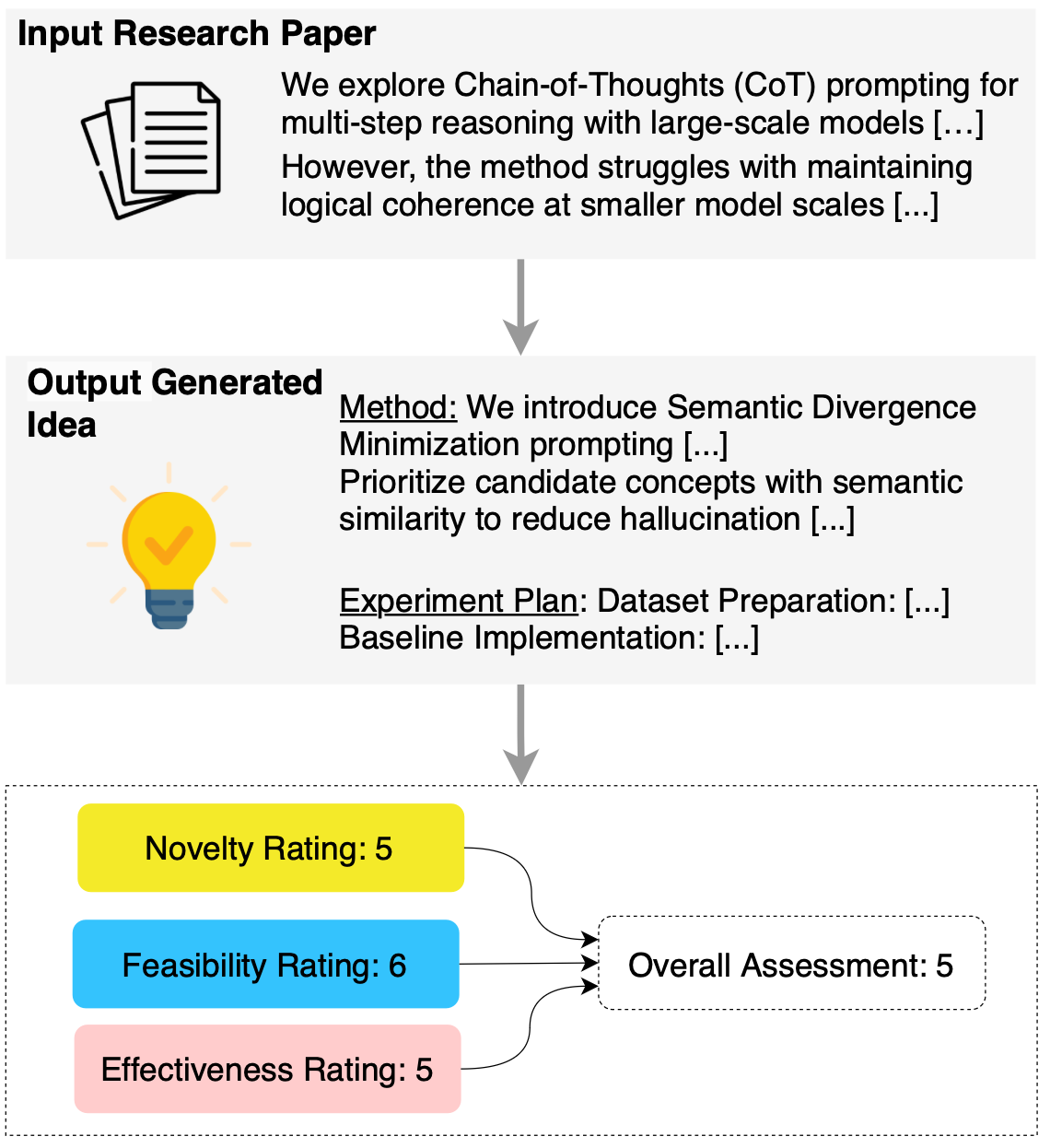
问题定义:现有方法在利用大型语言模型生成科研想法时,主要依赖于提示工程,但生成的想法往往难以达到专家标准,即在新颖性、可行性和有效性三个维度上表现不佳。这三个维度之间存在固有的权衡,如何平衡它们是一个挑战。因此,需要一种能够动态控制并优化这三个维度的科研想法生成方法。
核心思路:LDC框架的核心思路是将科研想法生成过程分解为两个阶段:首先通过监督微调(SFT)学习科研论文和后续想法之间的关联,然后利用可控强化学习(RL)根据多维奖励模型优化生成结果,从而在不同维度上取得平衡。通过维度控制器,在推理阶段可以动态地、上下文感知地引导想法生成过程。
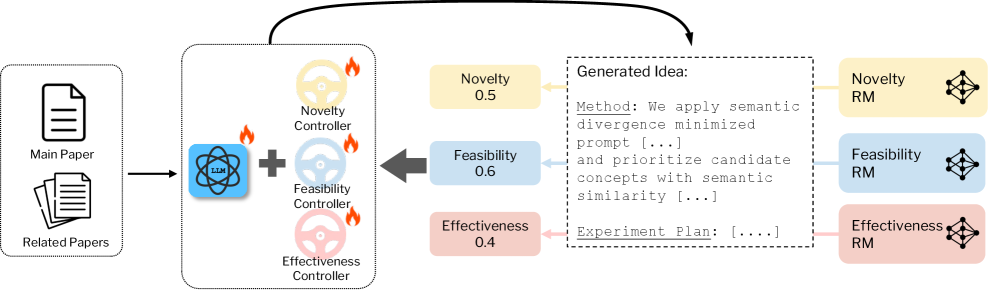
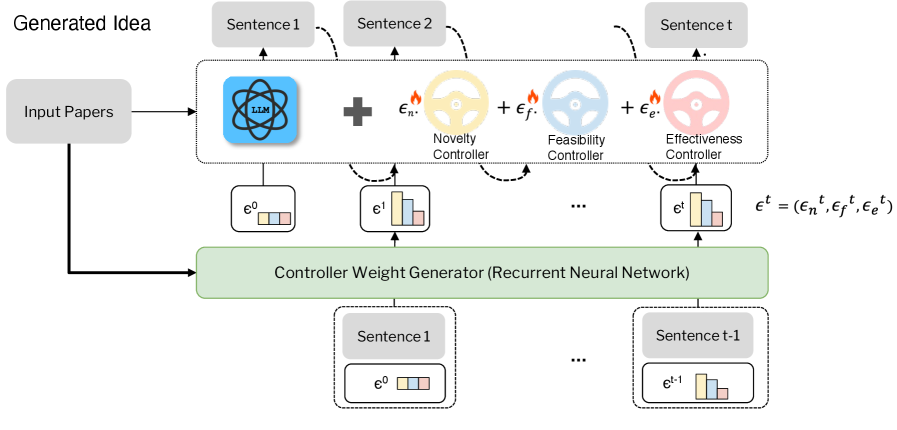
技术框架:LDC框架包含两个主要阶段:监督微调(SFT)和可控强化学习(RL)。在SFT阶段,模型学习研究论文及其对应后续想法之间的模式。在RL阶段,使用多维奖励模型,根据新颖性、可行性和有效性等维度对生成的想法进行评估,并利用强化学习算法优化模型。在推理阶段,维度控制器根据上下文动态调整各个维度的权重,引导想法生成。
关键创新:LDC框架的关键创新在于引入了可控强化学习,能够根据多维奖励模型优化科研想法生成过程,从而在不同维度上取得平衡。此外,维度控制器的设计使得模型能够动态地、上下文感知地调整各个维度的权重,从而生成更符合需求的科研想法。这是第一个针对科研想法生成任务,采用可控强化学习的框架。
关键设计:在SFT阶段,使用标准的序列到序列模型,并采用交叉熵损失函数进行训练。在RL阶段,设计了多维奖励模型,用于评估生成想法的新颖性、可行性和有效性。奖励模型可以使用现有的预训练模型进行微调,也可以从头开始训练。维度控制器使用句子级解码器,根据上下文动态调整各个维度的权重。具体的强化学习算法选择可以是PPO等。
🖼️ 关键图片
📊 实验亮点
LDC框架通过动态控制,在科研想法生成任务上取得了显著的性能提升。实验结果表明,LDC框架生成的想法在专家评估中表现出更高的质量,尤其是在新颖性、可行性和有效性三个维度上取得了更好的平衡。具体性能数据和对比基线在论文中详细给出。
🎯 应用场景
LDC框架可以应用于科研辅助、创新项目孵化等领域。它可以帮助研究人员快速生成新的研究想法,提高科研效率。此外,该框架还可以用于教育领域,帮助学生培养创新思维和科研能力。未来,该框架可以进一步扩展到其他创新领域,例如产品设计、商业模式创新等。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have demonstrated their potential in automating the scientific research ideation. Existing approaches primarily focus on prompting techniques, often producing ideas misaligned with expert standards - novelty, feasibility, and effectiveness, which are widely recognized by the research community as the three key subdimensions of high-quality ideas. Also, balancing these dimensions remains challenging due to their inherent trade-offs. To address these limitations, we propose the first framework that employs a two-stage approach combining Supervised Fine-Tuning (SFT) and controllable Reinforcement Learning (RL) for the task. In the SFT stage, the model learns foundational patterns from pairs of research papers and their corresponding follow-up ideas. In the RL stage, multi-dimensional reward models guided by fine-grained feedback evaluate and optimize the model across key dimensions. During inference, dimensional controllers coordinated by a sentence-level decoder enable dynamic context-aware steering of the idea generation process. Our framework provides a balanced approach to research idea generation, achieving high-quality outcomes in the experiment by dynamically navigating the trade-offs among novelty, feasibility, and effectiveness.