PA-RAG: RAG Alignment via Multi-Perspective Preference Optimization
作者: Jiayi Wu, Hengyi Cai, Lingyong Yan, Hao Sun, Xiang Li, Shuaiqiang Wang, Dawei Yin, Ming Gao
分类: cs.CL, cs.AI
发布日期: 2024-12-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出PA-RAG,通过多视角偏好优化对齐RAG生成器,提升信息性、鲁棒性和引用质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG对齐 多视角偏好优化 直接偏好优化 指令微调
📋 核心要点
- 现有RAG生成器存在信息量不足、鲁棒性差和引用质量低等问题,传统优化方法难以全面对齐RAG需求。
- PA-RAG通过构建高质量指令微调和多视角偏好数据,利用SFT和DPO优化RAG生成器,实现多维度对齐。
- 实验结果表明,PA-RAG在多个问答数据集上显著提升了RAG生成器的性能,验证了其有效性。
📝 摘要(中文)
检索增强生成(RAG)缓解了大语言模型(LLM)生成内容过时和幻觉的问题,但仍存在局限性。当通用LLM作为RAG生成器时,常面临信息量不足、鲁棒性差和引用质量低的问题。以往方法或在生成响应之外增加步骤,或通过监督微调(SFT)优化生成器,但未能完全对齐RAG的需求。因此,在保持端到端LLM形式的同时,从多个偏好角度优化RAG生成器仍然是一个挑战。为了弥合这一差距,我们提出了检索增强生成的多视角偏好对齐(PA-RAG),这是一种优化RAG系统生成器的方法,以全面对齐RAG需求。具体来说,我们通过在不同提示文档质量场景中对生成器采样不同质量的响应,构建高质量的指令微调数据和多视角偏好数据。随后,我们使用SFT和直接偏好优化(DPO)来优化生成器。在三个LLM上对四个问答数据集进行的大量实验表明,PA-RAG可以显著提高RAG生成器的性能。我们的代码和数据集可在https://github.com/wujwyi/PA-RAG获取。
🔬 方法详解
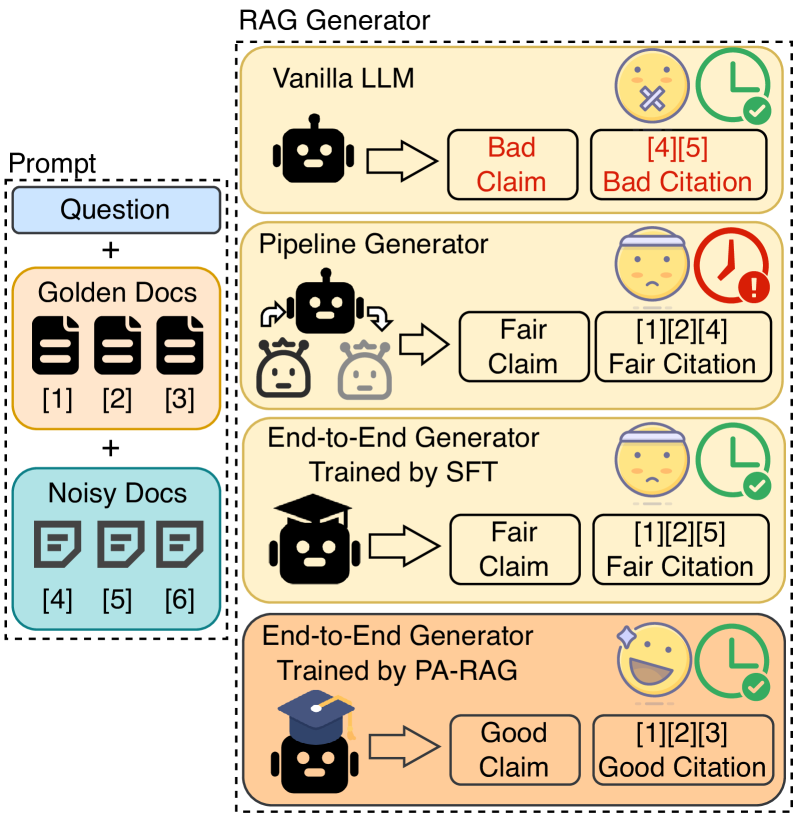
问题定义:论文旨在解决通用LLM作为RAG生成器时,生成的信息量不足、鲁棒性差以及引用质量低的问题。现有方法,如在生成后增加步骤或使用SFT,无法充分对齐RAG的需求,导致生成器在多个关键维度上表现不佳。
核心思路:论文的核心思路是通过多视角偏好优化来对齐RAG生成器。具体来说,就是构建高质量的指令微调数据和多视角偏好数据,然后利用SFT和DPO来优化生成器,使其在信息性、鲁棒性和引用质量等多个方面都得到提升。这种方法旨在使生成器更好地适应RAG系统的特定需求。
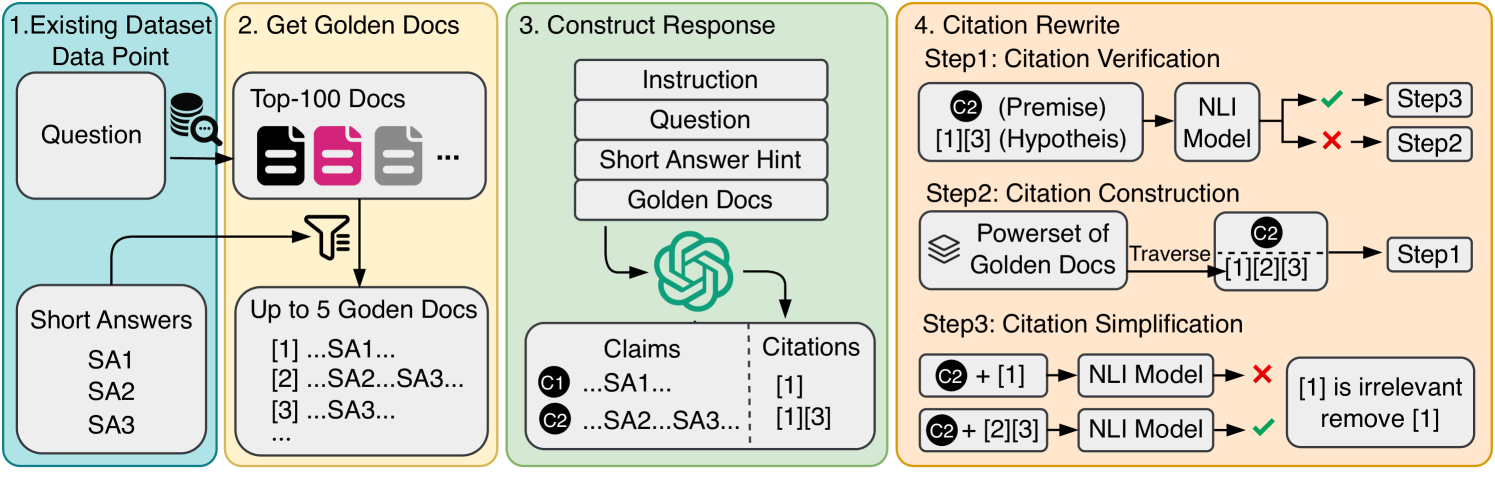
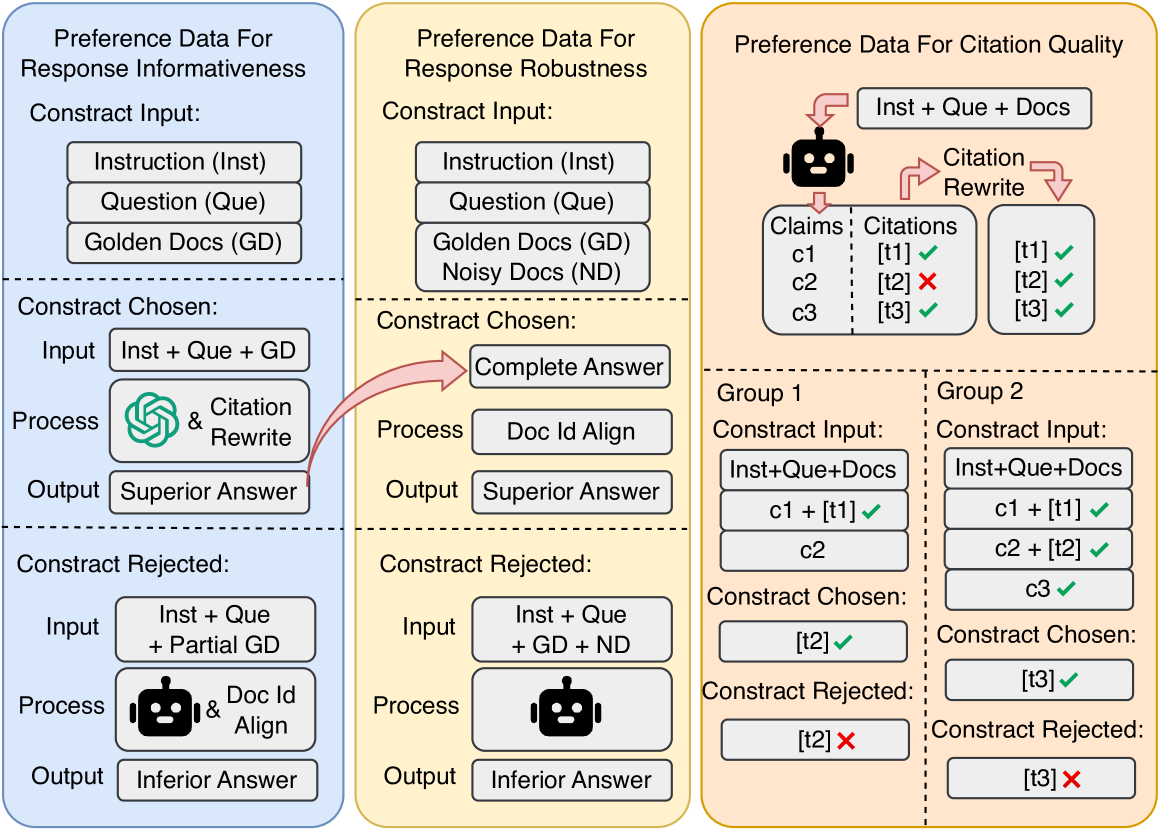
技术框架:PA-RAG的技术框架主要包含以下几个阶段:1) 数据构建阶段:通过在不同提示文档质量场景下对生成器进行采样,生成不同质量的响应,从而构建高质量的指令微调数据和多视角偏好数据。2) 模型优化阶段:使用SFT对生成器进行初步优化,然后使用DPO进一步优化生成器,使其更好地对齐RAG的需求。3) 评估阶段:在多个问答数据集上评估PA-RAG的性能,并与现有方法进行比较。
关键创新:PA-RAG的关键创新在于其多视角偏好优化方法。与以往方法只关注单一维度的优化不同,PA-RAG同时考虑了信息性、鲁棒性和引用质量等多个维度,从而更全面地对齐RAG的需求。此外,PA-RAG还采用了DPO算法,可以直接优化生成器的偏好,而无需像传统方法那样需要训练奖励模型。
关键设计:在数据构建阶段,论文设计了不同的提示文档质量场景,以生成不同质量的响应。在模型优化阶段,论文采用了SFT和DPO两种算法,其中SFT用于初步优化生成器,DPO用于进一步优化生成器的偏好。DPO算法的具体实现细节未知,需要参考DPO相关论文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PA-RAG在四个问答数据集上显著提升了RAG生成器的性能。具体来说,PA-RAG在信息性、鲁棒性和引用质量等多个指标上都优于现有方法。例如,在某些数据集上,PA-RAG的性能提升幅度超过10%。这些结果表明,PA-RAG是一种有效的RAG生成器优化方法。
🎯 应用场景
PA-RAG可应用于各种需要RAG的场景,例如智能客服、知识问答、文档摘要等。通过提升RAG生成器的信息性、鲁棒性和引用质量,可以提高用户满意度,减少错误信息的传播,并增强系统的可信度。未来,该方法可以进一步扩展到其他类型的生成任务中。
📄 摘要(原文)
The emergence of Retrieval-augmented generation (RAG) has alleviated the issues of outdated and hallucinatory content in the generation of large language models (LLMs), yet it still reveals numerous limitations. When a general-purpose LLM serves as the RAG generator, it often suffers from inadequate response informativeness, response robustness, and citation quality. Past approaches to tackle these limitations, either by incorporating additional steps beyond generating responses or optimizing the generator through supervised fine-tuning (SFT), still failed to align with the RAG requirement thoroughly. Consequently, optimizing the RAG generator from multiple preference perspectives while maintaining its end-to-end LLM form remains a challenge. To bridge this gap, we propose Multiple Perspective Preference Alignment for Retrieval-Augmented Generation (PA-RAG), a method for optimizing the generator of RAG systems to align with RAG requirements comprehensively. Specifically, we construct high-quality instruction fine-tuning data and multi-perspective preference data by sampling varied quality responses from the generator across different prompt documents quality scenarios. Subsequently, we optimize the generator using SFT and Direct Preference Optimization (DPO). Extensive experiments conducted on four question-answer datasets across three LLMs demonstrate that PA-RAG can significantly enhance the performance of RAG generators. Our code and datasets are available at https://github.com/wujwyi/PA-RAG.