Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
作者: Koshiro Saito, Sakae Mizuki, Masanari Ohi, Taishi Nakamura, Taihei Shiotani, Koki Maeda, Youmi Ma, Kakeru Hattori, Kazuki Fujii, Takumi Okamoto, Shigeki Ishida, Hiroya Takamura, Rio Yokota, Naoaki Okazaki
分类: cs.CL
发布日期: 2024-12-19 (更新: 2025-10-16)
备注: Accepted as a spotlight at the 1st workshop on Multilingual and Equitable Language Technologies (MELT), COLM 2025
💡 一句话要点
通过观察性分析,揭示了构建本地大型语言模型的必要性与策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 本地大型语言模型 多语种模型 能力迁移 观察性分析 主成分分析
📋 核心要点
- 现有本地LLM在特定语言能力方面存在不足,需要更深入地理解如何有效构建和训练。
- 采用观察性分析方法,通过评估和分析多种语言模型在不同任务上的表现,揭示语言能力迁移和特定语言训练的必要性。
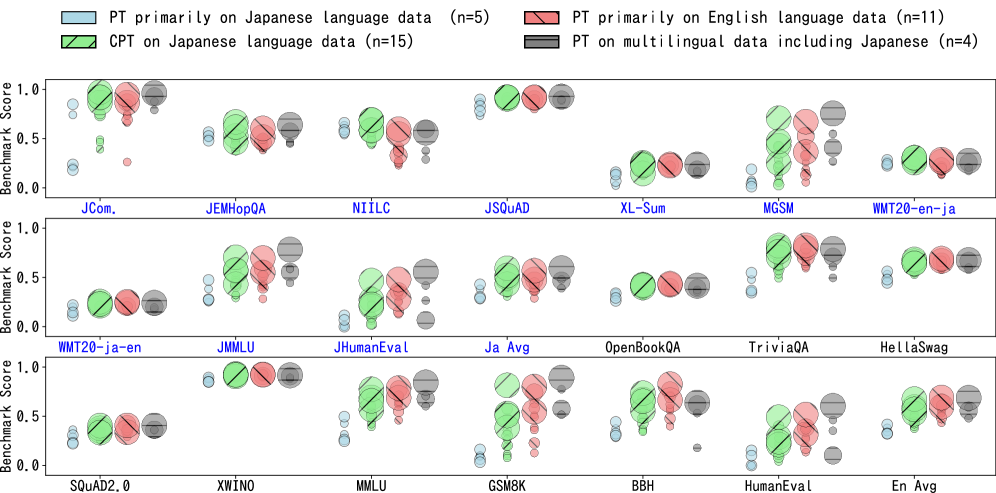
- 实验结果表明,英语训练能提升日语学术能力,而日语训练对日语知识问答和英日翻译至关重要,并验证了日语能力与计算预算的关联性。
📝 摘要(中文)
本文旨在探究构建本地大型语言模型(LLM)的原因,以及本地LLM应从目标语言中学习什么,哪些能力可以从其他语言迁移,以及是否存在特定于语言的缩放定律。为了研究这些问题,作者评估了35个日语、英语和多语种LLM在19个日语和英语评估基准上的表现,并将日语作为本地语言。通过观察性方法,分析了基准分数的关联性,并对分数进行了主成分分析(PCA),以推导出本地LLM的“能力因子”。研究发现,用英语文本进行训练可以提高日语学术科目(JMMLU)的分数。此外,无需专门用日语文本进行训练即可增强解决日语代码生成、算术推理、常识和阅读理解任务的能力。相反,用日语文本进行训练可以提高关于日语知识的问答任务和英日翻译的能力,这表明解决这两个任务的能力可以被认为是LLM的“日语能力”。此外,研究证实了日语能力随日语文本的计算预算而扩展。
🔬 方法详解
问题定义:论文旨在解决以下问题:为什么需要构建本地大型语言模型?本地LLM应该从目标语言中学习什么?哪些能力可以从其他语言迁移?是否存在特定于语言的缩放定律?现有方法缺乏对不同语言训练数据对LLM能力影响的细致分析,难以指导本地LLM的有效构建和训练。
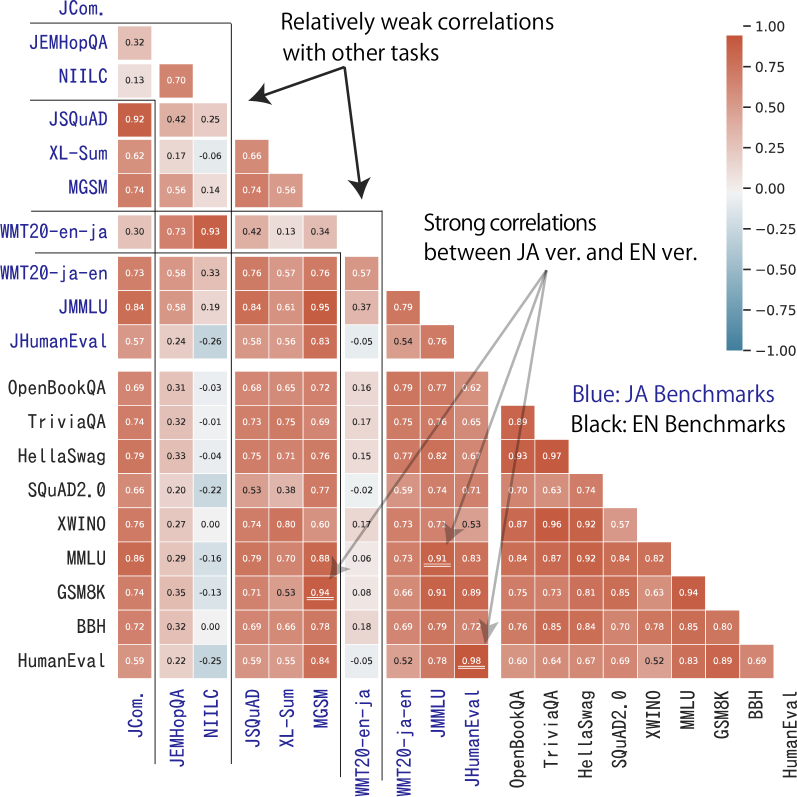
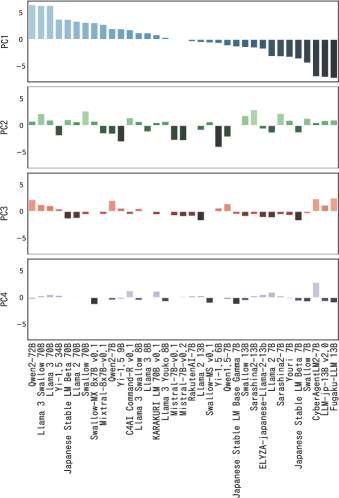
核心思路:论文的核心思路是通过观察性分析,研究不同语言训练数据对LLM在不同任务上的表现的影响。通过评估多个日语、英语和多语种LLM在各种基准测试上的性能,分析基准分数之间的相关性,并利用主成分分析(PCA)提取LLM的能力因子,从而揭示语言能力迁移和特定语言训练的必要性。
技术框架:论文采用的整体框架包括以下步骤:1) 选择35个日语、英语和多语种LLM;2) 在19个日语和英语评估基准上评估这些LLM的性能;3) 分析基准分数之间的相关性;4) 对分数进行主成分分析(PCA),以提取LLM的能力因子;5) 根据分析结果,得出关于本地LLM构建和训练的结论。
关键创新:论文的关键创新在于采用观察性分析方法,系统地研究了不同语言训练数据对LLM在不同任务上的表现的影响。通过主成分分析提取LLM的能力因子,能够更深入地理解LLM的语言能力,并为本地LLM的构建和训练提供指导。
关键设计:论文的关键设计包括:1) 选择具有代表性的日语、英语和多语种LLM;2) 选择涵盖各种语言能力(如学术知识、代码生成、算术推理、常识、阅读理解、问答、翻译等)的评估基准;3) 使用主成分分析(PCA)提取LLM的能力因子,并分析这些因子与不同语言训练数据之间的关系;4) 分析不同任务的性能与计算预算之间的关系,以验证特定语言能力的缩放定律。
🖼️ 关键图片
📊 实验亮点
研究发现,使用英语文本训练可以提高日语学术科目(JMMLU)的得分。同时,对于日语代码生成、算术推理、常识和阅读理解任务,无需专门使用日语文本进行训练。相反,日语文本训练能够显著提升日语知识问答和英日翻译能力。此外,研究还证实了日语能力与日语文本的计算预算之间存在正相关关系。
🎯 应用场景
该研究成果可应用于指导本地化大型语言模型的开发,尤其是在资源受限的语言环境中。通过了解哪些能力可以跨语言迁移,哪些能力需要特定语言的训练,可以更有效地利用训练资源,构建更具竞争力的本地LLM。此外,该研究还可以帮助教育领域,针对特定语言设计更有效的教学方法和资源。
📄 摘要(原文)
Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.