To Err Is Human; To Annotate, SILICON? Reducing Measurement Error in LLM Annotation
作者: Xiang Cheng, Raveesh Mayya, João Sedoc
分类: cs.CL
发布日期: 2024-12-19 (更新: 2025-10-16)
💡 一句话要点
提出SILICON方法,系统性降低LLM文本标注中的测量误差,提升管理研究的标注质量和可复现性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM标注 测量误差 文本标注 管理研究 可重复性 SILICON方法 提示工程
📋 核心要点
- 现有LLM标注方法存在测量误差,影响标注数据质量和研究结论的可靠性,缺乏系统性的误差分析和降低方法。
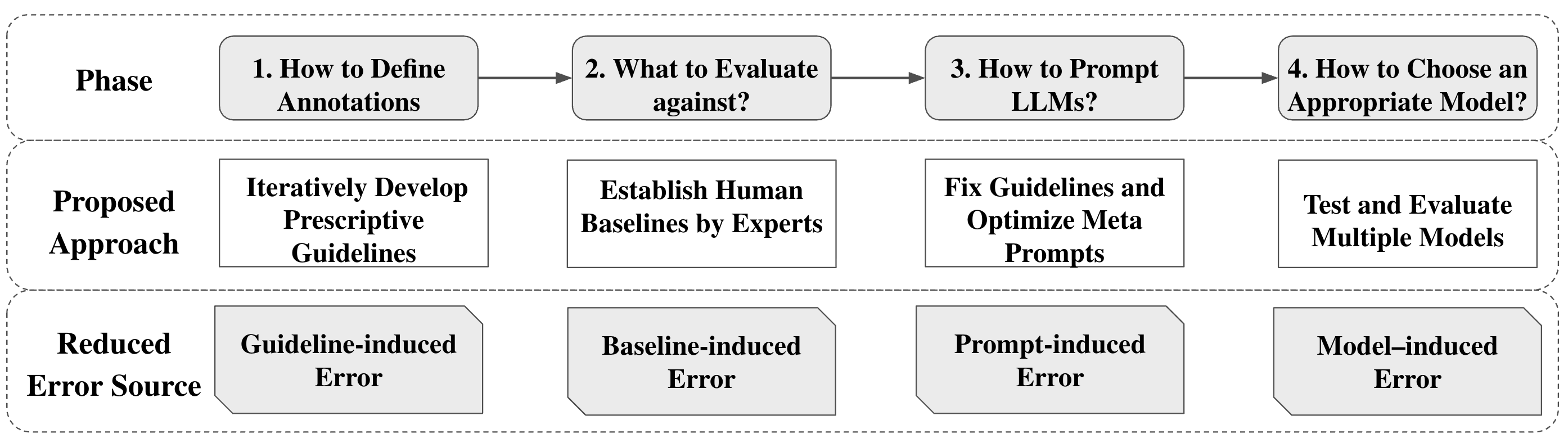
- SILICON方法从指南、基线、提示和模型四个方面分解LLM标注误差,并针对每个来源提出相应的误差降低策略。
- 实验表明,SILICON方法能有效提高LLM标注与人工标注的一致性,并提出模型迭代后的可重复性保证方法。
📝 摘要(中文)
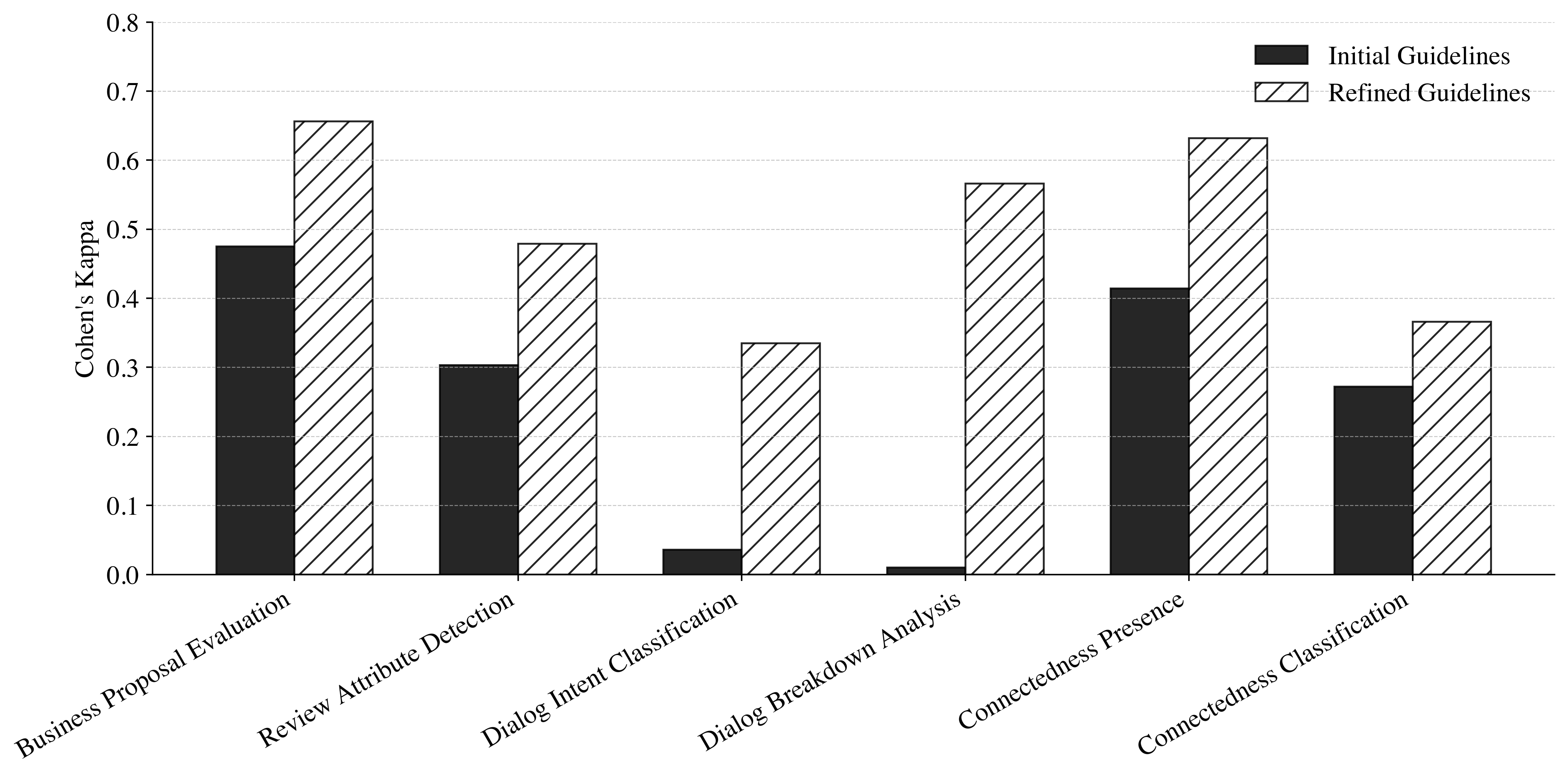
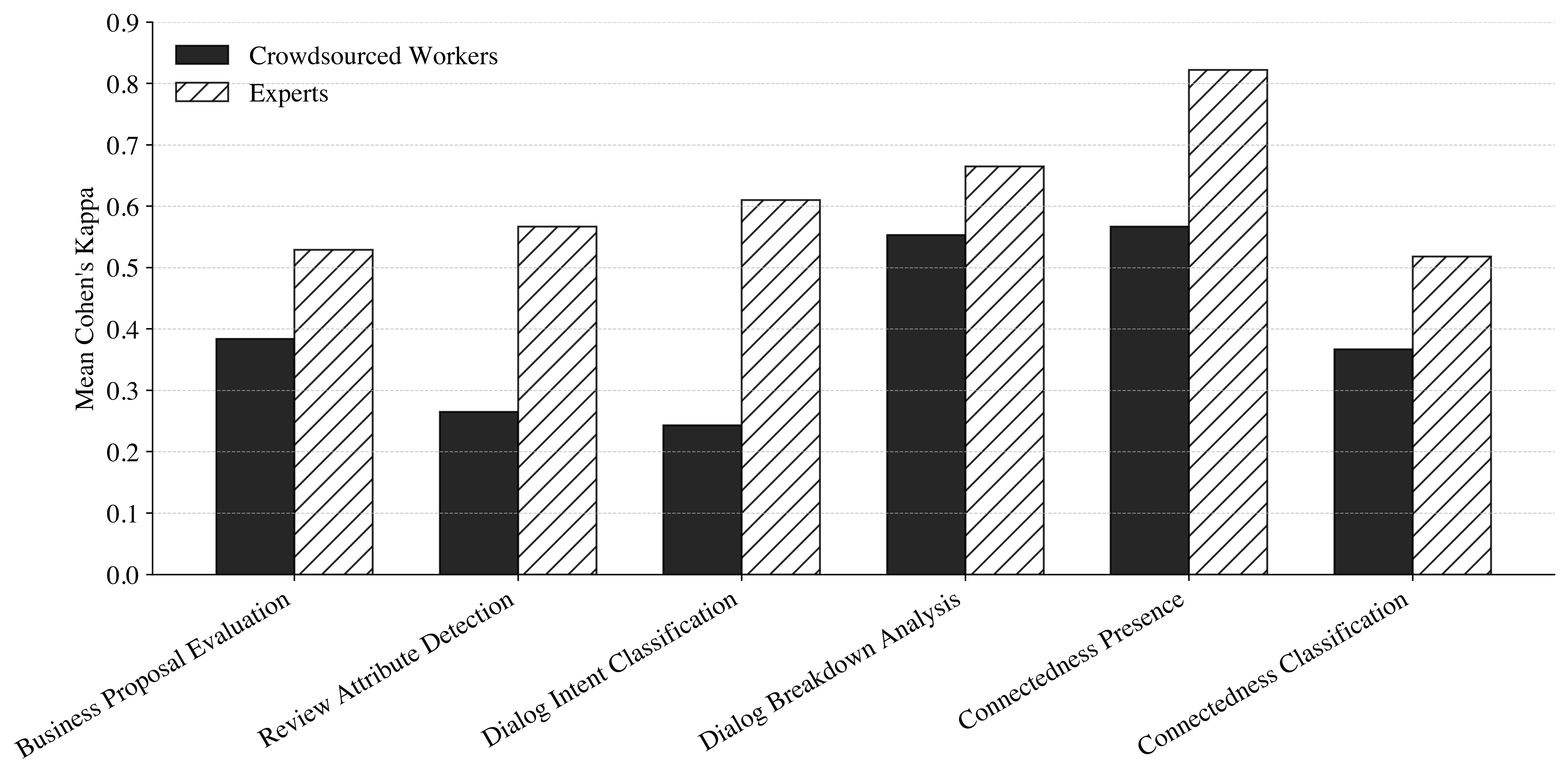
非结构化文本数据标注是管理研究的基础,大型语言模型(LLM)有望成为一种经济高效且可扩展的人工标注替代方案。从LLM标注数据中获得的见解的有效性,关键取决于最小化LLM分配的标签与未观察到的真实值之间的差异,并确保结果的长期可重复性。本文将LLM文本标注中的测量误差分解为四个不同的来源:(1)来自不一致标注标准的指南诱导误差;(2)来自不可靠的人工参考标准的基线诱导误差;(3)来自次优元指令格式的提示诱导误差;(4)来自LLM之间架构差异的模型诱导误差。我们开发了SILICON方法,以系统地减少上述所有四个来源的LLM标注中的测量误差。在七个管理研究案例中的实证验证表明,与一次性指南相比,迭代改进的指南显著提高了LLM-人工一致性;专家生成的基线表现出更高的人工标注者间一致性,并且与众包基线相比,不易产生误导性的LLM-人工一致性估计;将内容放置在系统提示中可以减少提示诱导的误差;并且模型性能在不同任务之间差异很大。为了进一步减少误差,我们引入了一种经济高效的多LLM标注方法,其中只有低置信度的项目会收到来自其他模型的额外标签。最后,为了解决闭源模型淘汰周期的问题,我们引入了一种直观的基于回归的方法来建立稳健的可重复性协议。我们的证据表明,减少每个误差来源都是必要的,并且SILICON支持管理研究中可重复、严谨的标注。
🔬 方法详解
问题定义:论文旨在解决LLM在文本标注任务中存在的测量误差问题。现有方法主要依赖于直接使用LLM进行标注,缺乏对误差来源的系统性分析和控制,导致标注结果与真实标签存在偏差,影响下游任务的性能和研究结论的可靠性。此外,闭源LLM的迭代更新也给标注结果的可重复性带来了挑战。
核心思路:论文的核心思路是将LLM标注过程中的测量误差分解为四个主要来源:指南诱导误差、基线诱导误差、提示诱导误差和模型诱导误差。针对每个误差来源,设计相应的策略来降低误差,从而提高LLM标注的准确性和可靠性。此外,论文还提出了多LLM标注方法和基于回归的可重复性协议,进一步提升标注质量和保证结果的可复现性。
技术框架:SILICON方法包含以下几个主要阶段: 1. 指南优化:通过迭代改进标注指南,减少标注标准的不一致性。 2. 基线选择:使用专家生成的基线,提高人工标注的可靠性。 3. 提示工程:优化提示格式,减少提示对LLM标注结果的影响。 4. 模型选择与集成:选择合适的LLM,并采用多LLM标注方法,降低模型差异带来的误差。 5. 可重复性保证:使用基于回归的方法,建立稳健的可重复性协议,应对闭源模型迭代更新带来的影响。
关键创新:论文最重要的技术创新点在于对LLM标注误差的系统性分解和针对性降低策略。与现有方法相比,SILICON方法不仅关注LLM本身的能力,还考虑了标注指南、人工基线和提示等因素对标注结果的影响,从而更全面地控制标注误差。此外,多LLM标注方法和基于回归的可重复性协议也为提高标注质量和保证结果的可复现性提供了新的思路。
关键设计: * 指南优化:采用迭代改进的方式,不断完善标注指南,减少歧义和不一致性。 * 基线选择:选择具有领域专业知识的专家进行标注,提高人工基线的可靠性。 * 提示工程:将内容放置在系统提示中,减少提示对LLM标注结果的影响。 * 多LLM标注:对低置信度的样本,使用多个LLM进行标注,并采用投票或集成的方式得到最终结果。 * 可重复性保证:使用回归模型,建立新旧模型标注结果之间的映射关系,保证结果的可重复性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SILICON方法能够显著提高LLM标注与人工标注的一致性。例如,迭代改进的指南显著提高了LLM-人工一致性。专家生成的基线表现出更高的人工标注者间一致性,并且与众包基线相比,不易产生误导性的LLM-人工一致性估计。将内容放置在系统提示中可以减少提示诱导的误差。多LLM标注方法能够进一步降低标注误差。基于回归的可重复性协议能够有效保证结果的可重复性。
🎯 应用场景
该研究成果可广泛应用于管理学、社会科学等领域,提升LLM在文本数据标注中的应用价值。通过SILICON方法,研究者可以更可靠地利用LLM进行大规模文本数据分析,从而加速相关领域的研究进展。此外,该方法提出的可重复性保证机制,有助于解决闭源模型更新带来的挑战,保证研究结果的长期有效性。
📄 摘要(原文)
Unstructured text data annotation is foundational to management research and Large Language Models (LLMs) promise a cost-effective and scalable alternative to human annotation. The validity of insights drawn from LLM annotated data critically depends on minimizing the discrepancy between LLM assigned labels and the unobserved ground truth, as well as ensuring long-term reproducibility of results. We address the gap in the literature on LLM annotation by decomposing measurement error in LLM-based text annotation into four distinct sources: (1) guideline-induced error from inconsistent annotation criteria, (2) baseline-induced error from unreliable human reference standards, (3) prompt-induced error from suboptimal meta-instruction formatting, and (4) model-induced error from architectural differences across LLMs. We develop the SILICON methodology to systematically reduce measurement error from LLM annotation in all four sources above. Empirical validation across seven management research cases shows iteratively refined guidelines substantially increases the LLM-human agreement compared to one-shot guidelines; expert-generated baselines exhibit higher inter-annotator agreement as well as are less prone to producing misleading LLM-human agreement estimates compared to crowdsourced baselines; placing content in the system prompt reduces prompt-induced error; and model performance varies substantially across tasks. To further reduce error, we introduce a cost-effective multi-LLM labeling method, where only low-confidence items receive additional labels from alternative models. Finally, in addressing closed source model retirement cycles, we introduce an intuitive regression-based methodology to establish robust reproducibility protocols. Our evidence indicates that reducing each error source is necessary, and that SILICON supports reproducible, rigorous annotation in management research.