ORBIT: Cost-Effective Dataset Curation for Large Language Model Domain Adaptation with an Astronomy Case Study
作者: Eric Modesitt, Ke Yang, Spencer Hulsey, Chengxiang Zhai, Volodymyr Kindratenko
分类: cs.CL, cs.AI
发布日期: 2024-12-19
🔗 代码/项目: GITHUB
💡 一句话要点
ORBIT:一种低成本的大语言模型领域自适应数据集构建方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域自适应 大语言模型 数据集构建 天文学 低成本 数据质量 数据过滤
📋 核心要点
- 通用大语言模型在专业领域知识方面存在不足,需要高质量的领域特定数据进行训练。
- ORBIT方法旨在从嘈杂的网络数据中高效地构建高质量的领域数据集,用于领域自适应训练。
- 实验表明,使用ORBIT方法构建的天文学数据集微调LLaMA-3-8B,在天文学基准测试中性能显著提升。
📝 摘要(中文)
本文提出了一种名为ORBIT的低成本方法,用于从嘈杂的网络资源中构建大规模、高质量的领域特定数据集,以训练专业的大语言模型。以天文学为主要案例,该方法将1.3T token的FineWeb-Edu数据集提炼成一个高质量的、10B token的天文学子集。在1B token的天文学子集上微调LLaMA-3-8B,在MMLU天文学基准测试中,性能从69%提高到76%,并在AstroBench(一个天文学专用基准测试)上取得了最佳结果。此外,在1000个天文学特定问题中,GPT-4o评估表明,ORBIT微调后的模型(Orbit-LLaMA)在73%的情况下优于LLaMA-3-8B-base。该方法还验证了ORBIT在法律和医学领域的通用性,与未经过滤的基线相比,数据质量得到了显著提高。ORBIT方法,包括整理的数据集、代码库和生成的模型,均已开源。
🔬 方法详解
问题定义:现有通用大语言模型在特定领域(如天文学、法律、医学)表现不佳,原因是训练数据中领域知识不足。直接使用网络数据进行训练,数据噪声大,质量难以保证,成本高昂。因此,需要一种高效、低成本的方法来构建高质量的领域特定数据集。
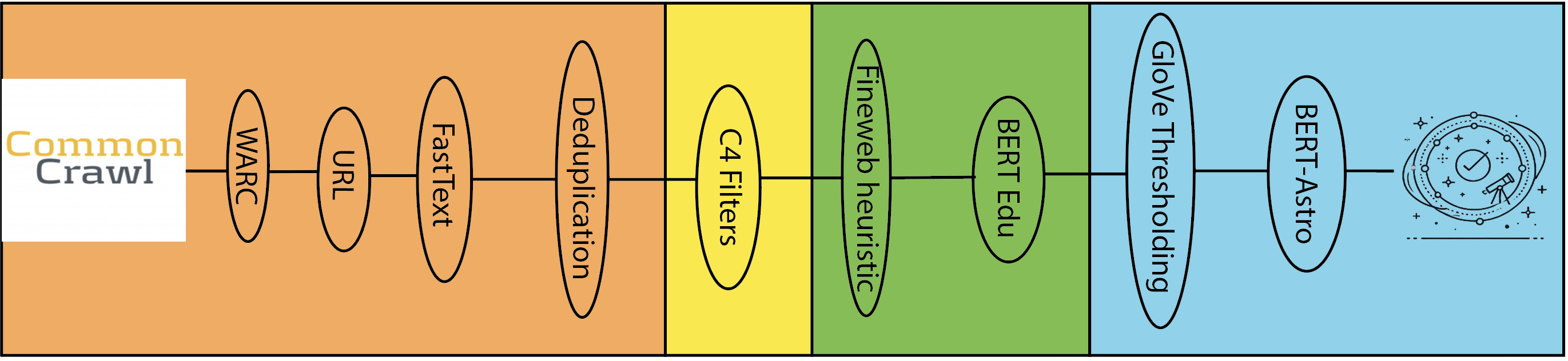
核心思路:ORBIT的核心思路是从大规模的通用网络数据集中,通过一系列过滤和筛选步骤,提取出高质量的领域相关数据。这种方法避免了从头开始收集和标注数据的成本,并能够有效去除噪声,提高数据质量。
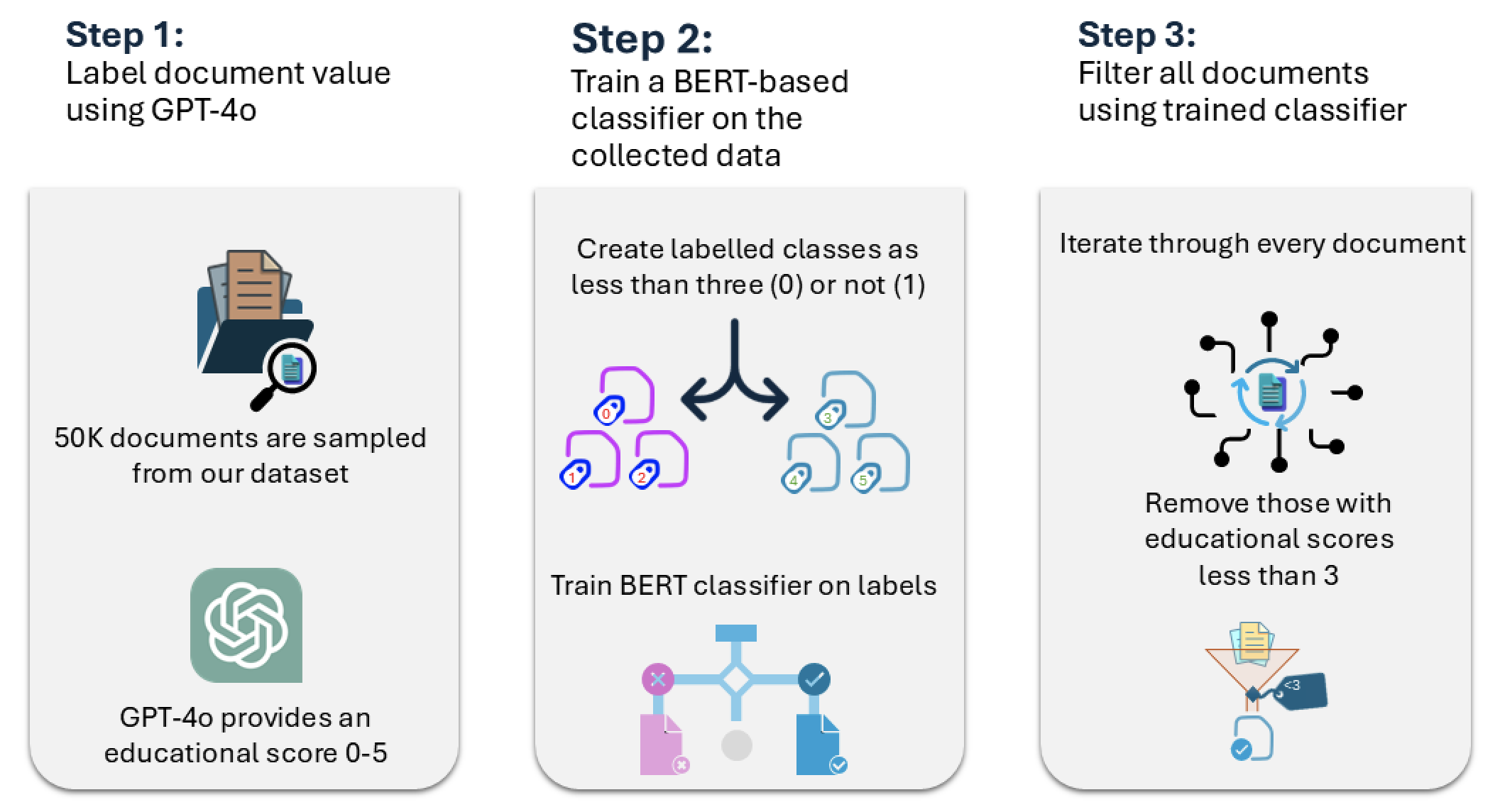
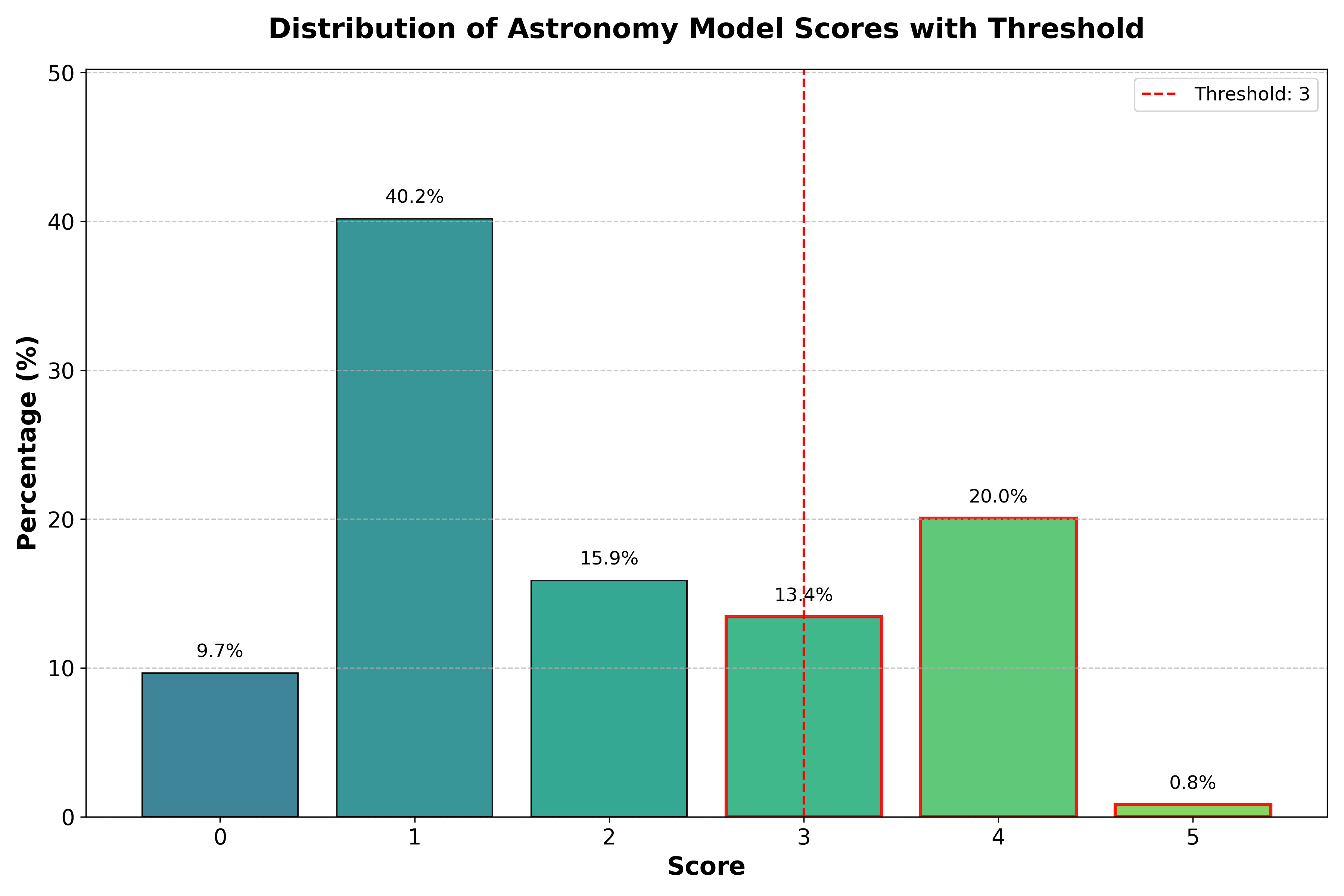
技术框架:ORBIT方法包含以下主要阶段:1) 数据源选择:选择包含大量领域相关信息的网络数据集(如FineWeb-Edu)。2) 领域关键词提取:根据领域知识,提取出一系列关键词。3) 数据过滤:使用关键词对原始数据集进行过滤,初步筛选出可能相关的文本。4) 数据质量评估:使用一系列指标(如困惑度、信息密度)评估过滤后的数据质量。5) 数据精炼:根据评估结果,进一步调整过滤策略或使用其他技术(如数据增强)来提高数据质量。
关键创新:ORBIT的关键创新在于其低成本和高效性。它利用现有的网络数据集,通过智能的过滤和评估策略,快速构建高质量的领域特定数据集。与传统的数据收集和标注方法相比,ORBIT大大降低了成本和时间。
关键设计:ORBIT的关键设计包括:1) 关键词的选择:关键词的选择直接影响过滤效果,需要根据领域知识进行精心设计。2) 数据质量评估指标:选择合适的评估指标能够有效识别高质量的数据。3) 迭代优化:ORBIT是一个迭代的过程,需要根据评估结果不断调整过滤策略和参数,以达到最佳效果。
🖼️ 关键图片
📊 实验亮点
在天文学领域,使用ORBIT方法构建的数据集微调LLaMA-3-8B后,在MMLU天文学基准测试中,性能从69%提高到76%,并在AstroBench上取得了最佳结果。GPT-4o评估表明,微调后的模型(Orbit-LLaMA)在73%的情况下优于LLaMA-3-8B-base,证明了ORBIT方法的有效性。
🎯 应用场景
ORBIT方法可广泛应用于各种专业领域的大语言模型训练,例如医学、法律、金融、工程等。通过构建高质量的领域数据集,可以显著提升大语言模型在这些领域的专业能力,从而应用于智能问答、文档生成、知识检索等任务,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Recent advances in language modeling demonstrate the need for high-quality domain-specific training data, especially for tasks that require specialized knowledge. General-purpose models, while versatile, often lack the depth needed for expert-level tasks because of limited domain-specific information. Domain adaptation training can enhance these models, but it demands substantial, high-quality data. To address this, we propose ORBIT, a cost-efficient methodology for curating massive, high-quality domain-specific datasets from noisy web sources, tailored for training specialist large language models. Using astronomy as a primary case study, we refined the 1.3T-token FineWeb-Edu dataset into a high-quality, 10B-token subset focused on astronomy. Fine-tuning \textsc{LLaMA-3-8B} on a 1B-token astronomy subset improved performance on the MMLU astronomy benchmark from 69\% to 76\% and achieved top results on AstroBench, an astronomy-specific benchmark. Moreover, our model (Orbit-LLaMA) outperformed \textsc{LLaMA-3-8B-base}, with GPT-4o evaluations preferring it in 73\% of cases across 1000 astronomy-specific questions. Additionally, we validated ORBIT's generalizability by applying it to law and medicine, achieving a significant improvement of data quality compared to an unfiltered baseline. We open-source the ORBIT methodology, including the curated datasets, the codebase, and the resulting model at \href{https://github.com/ModeEric/ORBIT-Llama}{https://github.com/ModeEric/ORBIT-Llama}.