Enhancing Knowledge Distillation for LLMs with Response-Priming Prompting
作者: Vijay Goyal, Mustafa Khan, Aprameya Tirupati, Harveer Saini, Michael Lam, Kevin Zhu
分类: cs.CL
发布日期: 2024-12-18
备注: Accepted to SoCal NLP Symposium 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出响应启动提示的知识蒸馏方法,提升LLM在资源受限环境下的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 响应启动提示 模型压缩 LoRA优化 GSM8K 推理引导 自注意力机制
📋 核心要点
- 大型语言模型部署困难,因其计算需求高昂。知识蒸馏是有效方法,但传统方法忽略了提示的作用。
- 论文提出响应启动提示策略,在知识蒸馏过程中提升学生模型性能,关注推理引导。
- 实验表明,该方法显著提升学生模型在GSM8K上的性能,Ground Truth提示下性能提升55%。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中表现出卓越的性能。然而,由于其巨大的计算需求和资源限制,这些模型通常难以部署。知识蒸馏(KD)是一种有效的技术,可以将大型LLM的性能转移到较小的模型。传统的KD方法主要关注教师模型的直接输出,很少强调提示在知识转移过程中的作用。本文提出了一组新颖的响应启动提示策略,应用于知识蒸馏流程中,以提高学生模型的性能。我们的方法通过从量化的Llama 3.1 405B Instruct教师模型中提取知识,来微调较小的Llama 3.1 8B Instruct模型。我们应用LoRA优化,并在GSM8K基准上进行评估。实验结果表明,将推理引导提示集成到所提出的KD流程中,可以显著提高学生模型的性能,从而提供一种在资源受限环境中部署强大模型的有效方法。我们发现,与没有提示的蒸馏模型相比,Ground Truth提示使蒸馏的Llama 3.1 8B Instruct在GSM8K上的性能提高了55%。对学生模型自注意力层的深入研究表明,更成功的提示模型倾向于在其注意力头中表现出某些积极的行为,这可以与其准确性的提高联系起来。我们的实现可在https://github.com/alonso130r/knowledge-distillation找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型因计算资源需求高而难以部署的问题。现有知识蒸馏方法主要关注教师模型的输出,忽略了提示在知识迁移中的作用,导致学生模型性能提升有限。
核心思路:论文的核心思路是在知识蒸馏过程中,通过引入响应启动提示策略,引导学生模型学习教师模型的推理过程,从而提升学生模型的性能。这种方法强调了提示在知识迁移中的重要性,并设计了相应的提示策略。
技术框架:整体框架包括教师模型(Llama 3.1 405B Instruct)、学生模型(Llama 3.1 8B Instruct)和知识蒸馏流程。首先,使用不同的响应启动提示策略生成教师模型的输出。然后,利用这些输出来训练学生模型。最后,在GSM8K基准上评估学生模型的性能。LoRA优化被应用于学生模型的微调过程中。
关键创新:最重要的创新点在于提出了响应启动提示策略,并将其应用于知识蒸馏流程中。与传统的知识蒸馏方法相比,该方法更加关注提示在知识迁移中的作用,通过引导学生模型学习教师模型的推理过程,从而提升学生模型的性能。
关键设计:论文中使用了多种响应启动提示策略,包括Ground Truth prompting。此外,论文还对学生模型的自注意力层进行了深入研究,发现更成功的提示模型倾向于在其注意力头中表现出某些积极的行为。LoRA被用于优化学生模型,减少训练参数。
🖼️ 关键图片
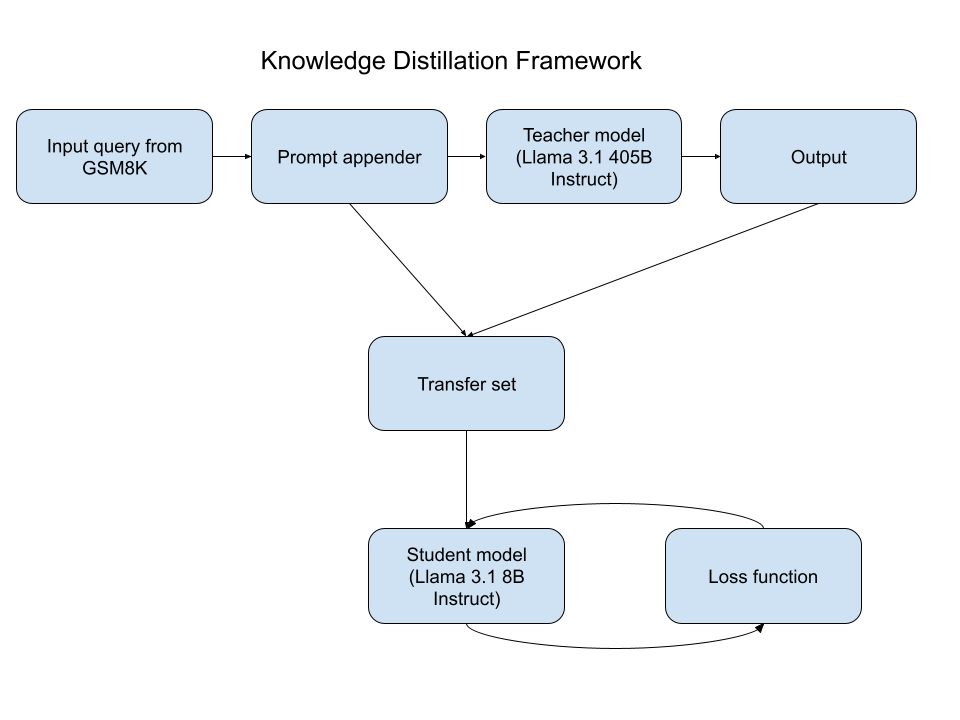


📊 实验亮点
实验结果表明,提出的响应启动提示策略可以显著提升学生模型的性能。在GSM8K基准上,使用Ground Truth提示的蒸馏Llama 3.1 8B Instruct模型相比于没有提示的模型,性能提升了55%。此外,对学生模型自注意力层的分析表明,更成功的提示模型在其注意力头中表现出与准确性提升相关的特定行为。
🎯 应用场景
该研究成果可应用于各种资源受限的场景,例如移动设备、嵌入式系统等。通过知识蒸馏和响应启动提示,可以将大型语言模型的强大能力迁移到小型模型上,从而在资源有限的环境中实现高性能的自然语言处理应用。这对于推动人工智能在边缘计算领域的应用具有重要意义。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing (NLP) tasks. However, these models are often difficult to deploy due to significant computational requirements and resource constraints. Knowledge distillation (KD) is an effective technique for transferring the performance of larger LLMs to smaller models. Traditional KD methods primarily focus on the direct output of the teacher model, with little emphasis on the role of prompting during knowledge transfer. In this paper, we propose a set of novel response-priming prompting strategies applied in the knowledge distillation pipeline to enhance the performance of student models. Our approach fine-tunes a smaller Llama 3.1 8B Instruct model by distilling knowledge from a quantized Llama 3.1 405B Instruct teacher model. We apply LoRA optimization and evaluate on the GSM8K benchmark. Experimental results demonstrate that integrating reasoning-eliciting prompting into the proposed KD pipeline significantly improves student model performance, offering an efficient way to deploy powerful models in resource-constrained environments. We find that Ground Truth prompting results in a 55\% performance increase on GSM8K for a distilled Llama 3.1 8B Instruct compared to the same model distilled without prompting. A thorough investigation into the self-attention layers of the student models indicates that the more successful prompted models tend to exhibit certain positive behaviors inside their attention heads which can be tied to their increased accuracy. Our implementation can be found at https://github.com/alonso130r/knowledge-distillation.