Maximize Your Data's Potential: Enhancing LLM Accuracy with Two-Phase Pretraining
作者: Steven Feng, Shrimai Prabhumoye, Kezhi Kong, Dan Su, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-18
💡 一句话要点
提出两阶段预训练方法,优化数据选择与混合策略,提升LLM准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 预训练 数据混合 两阶段训练 模型优化
📋 核心要点
- 现有LLM预训练在数据混合策略上缺乏深入研究,尤其是在长序列和大型模型上的可扩展性。
- 论文提出两阶段预训练框架,通过优化数据选择和混合,提升模型准确率。
- 实验表明,该方法优于随机数据排序和自然分布,平均准确率提升显著。
📝 摘要(中文)
大规模语言模型的有效预训练需要策略性的数据选择、混合和排序。然而,关于数据混合的关键细节,特别是它们在更长token序列和更大模型尺寸上的可扩展性,由于模型开发者披露有限而未被充分探索。为了解决这个问题,我们形式化了两阶段预训练的概念,并对如何选择和混合数据以最大化两个阶段的模型准确率进行了广泛的系统研究。我们的研究结果表明,两阶段预训练方法在平均准确率上优于随机数据排序和token的自然分布,分别提升了3.4%和17%。我们提供了关于基于数据源质量和训练轮数来制定最佳混合策略的深入指导。我们建议在较小的1T token规模上使用降采样数据来设计混合策略,并证明了我们的方法可以有效地扩展到更大的15T token序列和更大的25B模型尺寸。这些见解为从业者提供了一系列步骤,可以用来设计和扩展他们的数据混合策略。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型预训练过程中,数据选择和混合策略不明确,导致模型性能受限的问题。现有方法,如随机数据排序或依赖数据自然分布,无法充分利用数据的潜力,尤其是在处理长序列和训练大型模型时,效率和效果都难以保证。
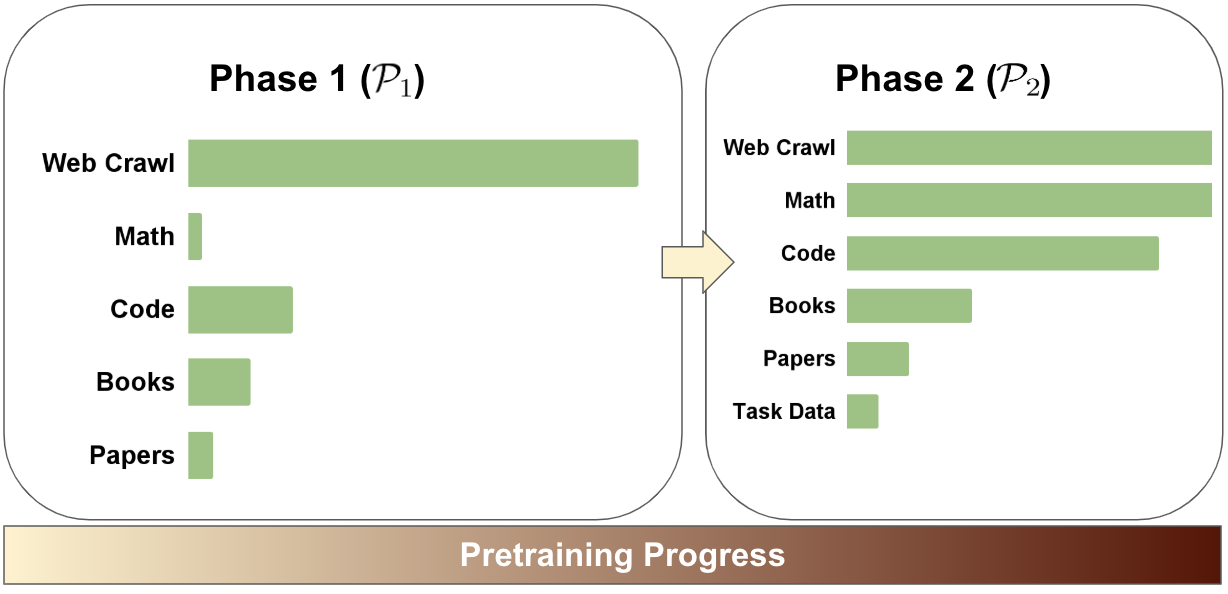
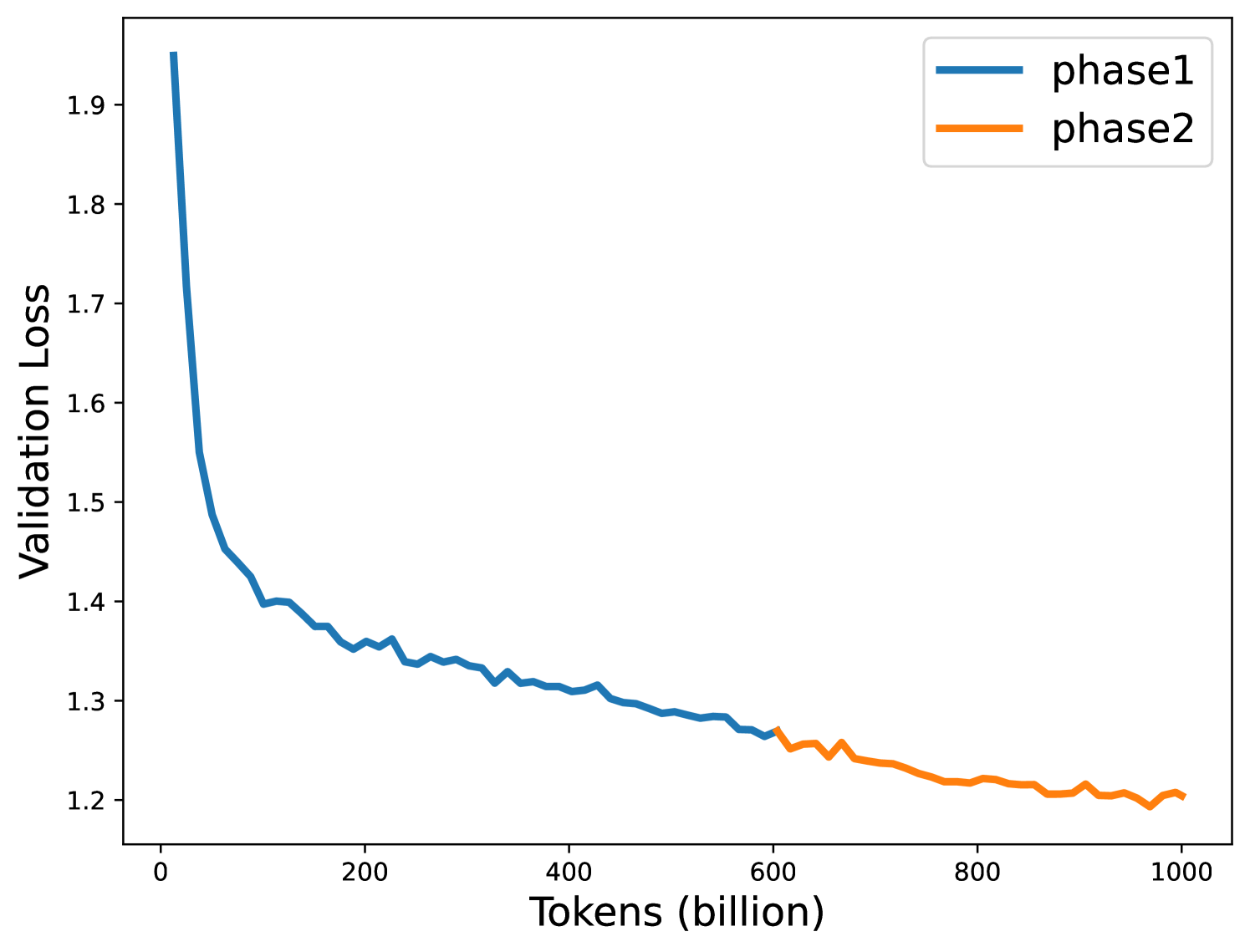
核心思路:论文的核心思路是将预训练过程分为两个阶段,并针对每个阶段设计特定的数据混合策略。第一阶段侧重于快速学习通用知识,第二阶段侧重于提升模型在特定任务或领域上的性能。通过精细化地控制每个阶段的数据组成,可以更有效地训练模型。
技术框架:论文提出的两阶段预训练框架包含以下主要步骤:1) 数据收集与清洗:收集各种来源的文本数据,并进行清洗和预处理。2) 数据分析与评估:分析数据的质量、多样性和领域分布。3) 混合策略设计:根据数据分析结果,为每个阶段设计特定的数据混合比例。4) 模型训练:使用设计好的数据混合策略,分阶段训练语言模型。5) 性能评估:评估模型在各种任务上的性能,并根据结果调整数据混合策略。
关键创新:论文的关键创新在于形式化了两阶段预训练的概念,并系统地研究了不同数据混合策略对模型性能的影响。通过实验,论文揭示了不同数据源的质量和训练轮数对模型性能的影响规律,并提出了基于这些规律来设计最佳数据混合策略的方法。
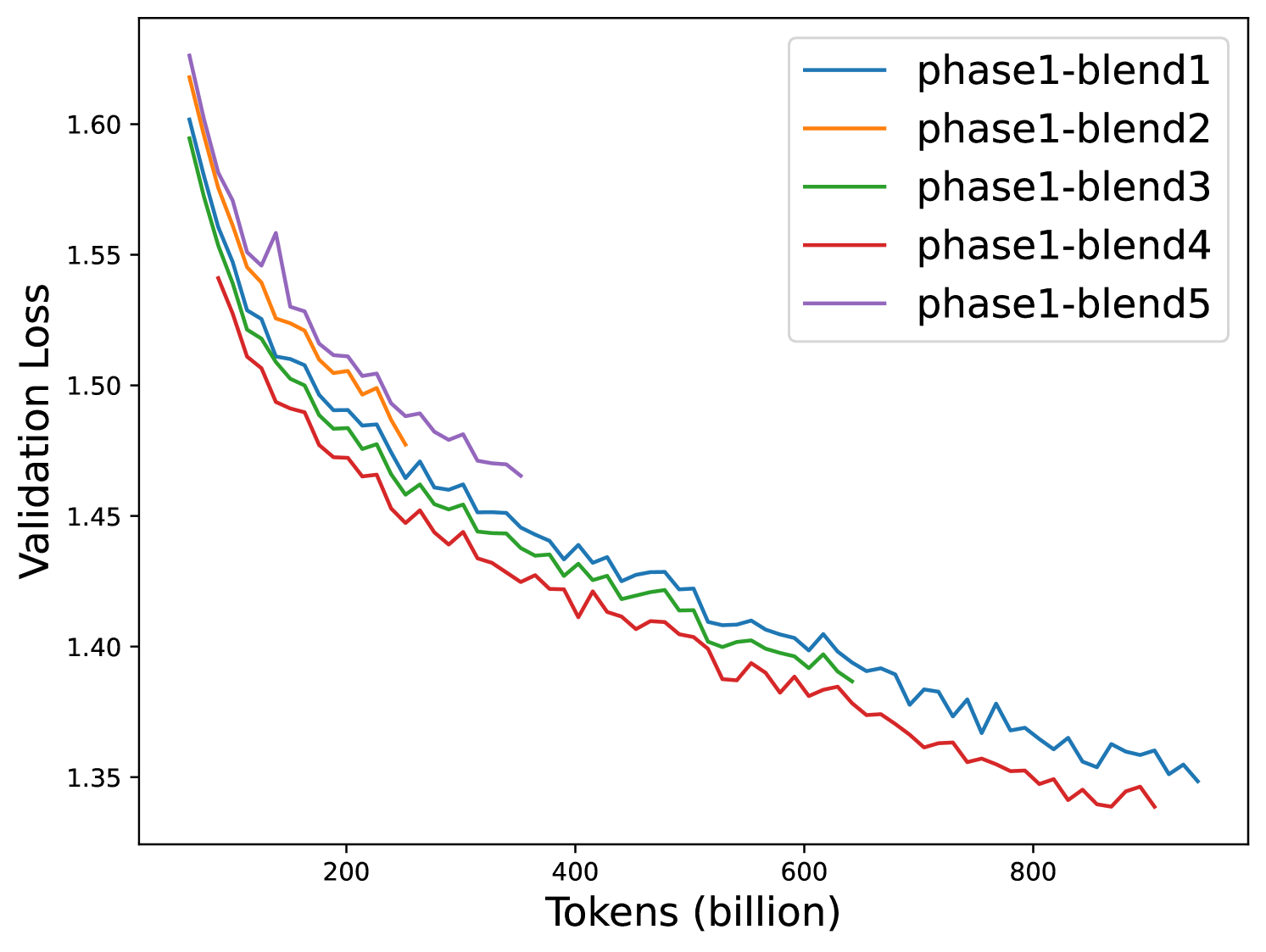
关键设计:论文建议在较小的规模(1T tokens)上使用降采样数据来设计数据混合策略,然后将该策略扩展到更大的规模(15T tokens)和更大的模型尺寸(25B)。这种方法可以降低实验成本,并提高效率。此外,论文还提供了关于如何选择数据源、如何确定数据混合比例以及如何调整训练轮数的具体指导。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的两阶段预训练方法在平均准确率上优于随机数据排序和token的自然分布,分别提升了3.4%和17%。此外,该方法可以有效地扩展到更大的token序列(15T tokens)和更大的模型尺寸(25B),证明了其良好的可扩展性和实用性。
🎯 应用场景
该研究成果可广泛应用于各种需要大规模语言模型的场景,例如智能客服、机器翻译、文本生成、代码生成等。通过优化预训练数据,可以显著提升模型的性能和效率,降低训练成本,从而加速LLM在各行业的落地和应用。该研究也为后续LLM预训练方法的研究提供了有价值的参考。
📄 摘要(原文)
Pretraining large language models effectively requires strategic data selection, blending and ordering. However, key details about data mixtures especially their scalability to longer token horizons and larger model sizes remain underexplored due to limited disclosure by model developers. To address this, we formalize the concept of two-phase pretraining and conduct an extensive systematic study on how to select and mix data to maximize model accuracies for the two phases. Our findings illustrate that a two-phase approach for pretraining outperforms random data ordering and natural distribution of tokens by 3.4% and 17% on average accuracies. We provide in-depth guidance on crafting optimal blends based on quality of the data source and the number of epochs to be seen. We propose to design blends using downsampled data at a smaller scale of 1T tokens and then demonstrate effective scaling of our approach to larger token horizon of 15T tokens and larger model size of 25B model size. These insights provide a series of steps practitioners can follow to design and scale their data blends.