Channel Merging: Preserving Specialization for Merged Experts
作者: Mingyang Zhang, Jing Liu, Ganggui Ding, Xinyi Yu, Linlin Ou, Bohan Zhuang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-18
备注: accepted by AAAI 2025
💡 一句话要点
提出通道合并方法,在合并专家模型时保持专业化知识并提升存储效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型合并 通道合并 大型语言模型 参数效率 知识保留
📋 核心要点
- 现有模型合并方法在专家数量增加时,容易出现参数冲突和性能下降,且后剪枝和部分合并方法存在性能和存储效率的局限性。
- 通道合并方法通过离线聚类和合并相似的通道参数,减少参数冲突,并在推理时快速查找专家参数,从而保留专业知识。
- 实验结果表明,通道合并在多种任务上实现了与未合并模型相当的性能,并且在使用任务特定路由时,仅需53%的参数即可达到模型集成的效果。
📝 摘要(中文)
为了提升大型语言模型(LLM)在后续任务中的性能,通常采用任务特定的微调方法。集成不同的LLM可以显著增强LLM的整体能力。然而,传统的集成方法需要同时将所有专门的模型加载到GPU内存中,导致内存开销巨大。为了解决这个问题,模型合并策略应运而生,它将所有LLM合并为一个模型,以减少推理期间的内存占用。尽管取得了这些进展,但随着专家数量的增加,模型合并常常导致参数冲突和性能下降。为了应对这些挑战,我们引入了通道合并,这是一种旨在最小化参数冲突并提高存储效率的新策略。该方法离线地基于通道参数的相似性对其进行聚类和合并,形成若干组。通过确保仅在每个组内合并高度相似的参数,显著减少了参数冲突。在推理期间,我们可以立即从合并的组中查找专家参数,从而保留专门的知识。实验表明,通道合并始终提供高性能,在英语和中文推理、数学推理和代码生成等任务中与未合并的模型相匹配。此外,当与任务特定的路由器一起使用时,它仅使用53%的参数即可获得与模型集成相当的结果。
🔬 方法详解
问题定义:论文旨在解决模型合并过程中,由于参数冲突导致的性能下降问题,尤其是在合并大量专家模型时。现有方法,如后剪枝和部分合并,在性能和存储效率方面存在不足,无法有效应对大量专家模型合并带来的挑战。
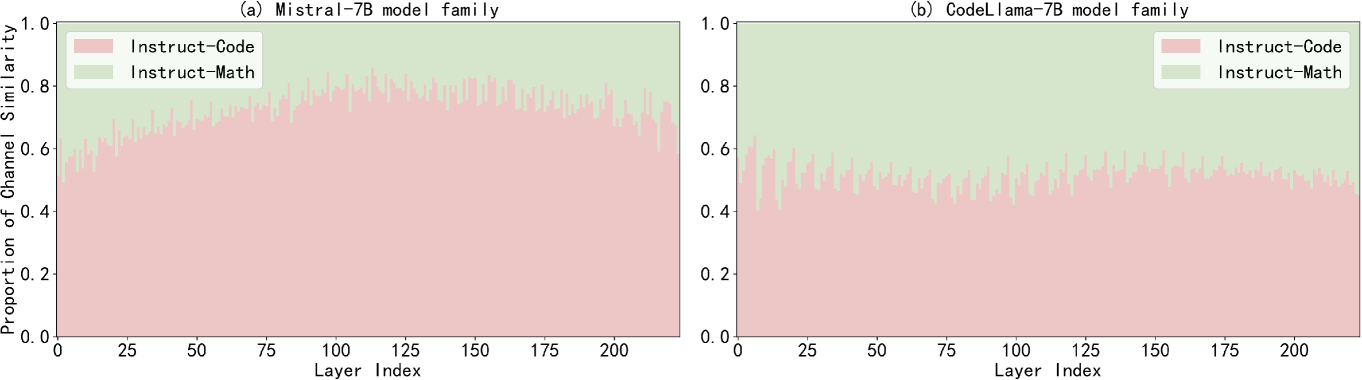
核心思路:论文的核心思路是基于通道参数的相似性进行聚类和合并。通过将相似的通道参数合并到同一组,可以减少不同专家模型参数之间的冲突,从而在合并模型的同时保留各个专家的专业知识。这种方法旨在提高存储效率,同时保持或提升模型性能。
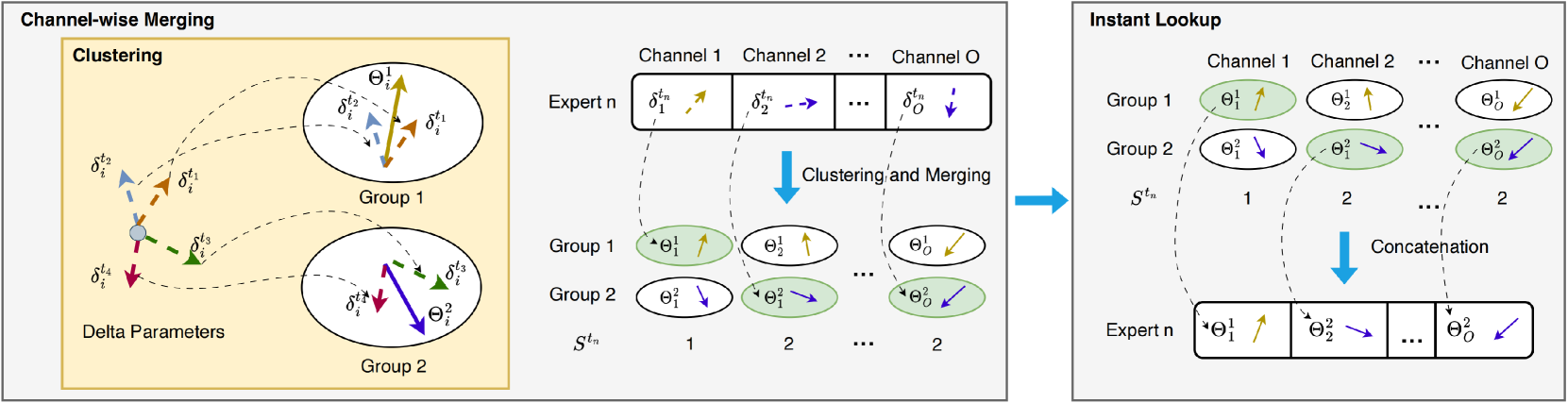
技术框架:通道合并方法主要包含以下几个阶段:1) 离线聚类:计算各个专家模型通道参数之间的相似度,并根据相似度将通道参数聚类成若干组。2) 通道合并:在每个组内,将相似的通道参数进行合并,生成合并后的参数。3) 推理阶段:在推理时,根据输入选择相应的通道组,并使用合并后的参数进行计算。如果使用了任务特定的路由,则可以根据路由器的输出选择相应的通道组。
关键创新:该方法最重要的创新点在于其通道级别的合并策略。与传统的模型合并方法直接合并整个模型参数不同,通道合并方法只合并相似的通道参数,从而减少了参数冲突,并保留了各个专家模型的专业知识。此外,离线聚类和在线快速查找的机制也提高了推理效率。
关键设计:在离线聚类阶段,可以使用不同的相似度度量方法,如余弦相似度或欧氏距离。聚类算法可以选择K-means等。合并策略可以选择简单的平均或加权平均。在推理阶段,需要设计高效的查找算法,以便快速定位到相应的通道组。任务特定路由器的设计也需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通道合并方法在英语和中文推理、数学推理和代码生成等任务中,性能与未合并的模型相当。更重要的是,当与任务特定的路由器结合使用时,该方法仅使用53%的参数,就能达到与模型集成相当的性能。这些结果表明,通道合并方法在提高存储效率的同时,能够有效保持模型性能。
🎯 应用场景
该研究成果可应用于需要集成多个专业领域知识的大型语言模型,例如智能客服、多语言翻译、专业领域问答等。通过通道合并,可以在保证模型性能的同时,显著降低模型存储和计算成本,使得在资源受限的设备上部署大型语言模型成为可能。未来,该技术有望推动AI在各个领域的广泛应用。
📄 摘要(原文)
Lately, the practice of utilizing task-specific fine-tuning has been implemented to improve the performance of large language models (LLM) in subsequent tasks. Through the integration of diverse LLMs, the overall competency of LLMs is significantly boosted. Nevertheless, traditional ensemble methods are notably memory-intensive, necessitating the simultaneous loading of all specialized models into GPU memory. To address the inefficiency, model merging strategies have emerged, merging all LLMs into one model to reduce the memory footprint during inference. Despite these advances, model merging often leads to parameter conflicts and performance decline as the number of experts increases. Previous methods to mitigate these conflicts include post-pruning and partial merging. However, both approaches have limitations, particularly in terms of performance and storage efficiency when merged experts increase. To address these challenges, we introduce Channel Merging, a novel strategy designed to minimize parameter conflicts while enhancing storage efficiency. This method clusters and merges channel parameters based on their similarity to form several groups offline. By ensuring that only highly similar parameters are merged within each group, it significantly reduces parameter conflicts. During inference, we can instantly look up the expert parameters from the merged groups, preserving specialized knowledge. Our experiments demonstrate that Channel Merging consistently delivers high performance, matching unmerged models in tasks like English and Chinese reasoning, mathematical reasoning, and code generation. Moreover, it obtains results comparable to model ensemble with just 53% parameters when used with a task-specific router.