PLPP: Prompt Learning with Perplexity Is Self-Distillation for Vision-Language Models
作者: Biao Liu, Wenyi Fang, Xiaoyu Wu, Yang Zheng, Zheng Hu, Bo Yuan
分类: cs.CL, cs.AI
发布日期: 2024-12-18
💡 一句话要点
PLPP:基于困惑度的Prompt学习,实现视觉-语言模型的自蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉-语言模型 Prompt学习 困惑度 自蒸馏 正则化 过拟合 互自蒸馏
📋 核心要点
- 现有方法如CoOp仅依赖CLIP损失微调Prompt,易导致视觉-语言模型在下游任务上过拟合。
- PLPP利用困惑度损失正则化Prompt学习,本质上是一种自蒸馏,可有效防止过拟合。
- 实验表明,PLPP在多个分类任务上优于现有方法,验证了其有效性和优越性。
📝 摘要(中文)
预训练视觉-语言(VL)模型,如CLIP,已在众多下游任务中展现出卓越性能。Context Optimization (CoOp)通过引入prompt学习进一步提升了VL模型在下游任务上的性能。CoOp优化一组可学习的向量(即prompt),并冻结整个CLIP模型。然而,仅依赖CLIP损失来微调prompt可能导致模型在下游任务上过拟合。为了解决这个问题,我们提出了一种即插即用的prompt正则化方法,称为PLPP(Prompt Learning with PerPlexity),它使用困惑度损失来正则化prompt学习。PLPP设计了一个两步操作来计算prompt的困惑度:(a)计算嵌入层权重和prompt之间的余弦相似度以获得标签,(b)在文本编码器后引入一个无需训练的语言模型(LM)头来输出单词概率分布。同时,我们揭示了PLPP的本质是一种自蒸馏形式。为了进一步防止过拟合以及减少PLPP引入的额外计算,我们将硬标签转换为软标签,并选择top-$k$值来计算困惑度损失。为了加速模型收敛,我们引入了互自蒸馏学习,即困惑度和反向困惑度损失。在四个分类任务上进行的实验表明,PLPP相比现有方法表现出更优越的性能。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(如CLIP)在下游任务中使用Prompt Learning时容易过拟合的问题。现有方法,例如CoOp,主要依赖CLIP损失来优化Prompt,缺乏对Prompt本身的约束,导致模型泛化能力不足。
核心思路:论文的核心思路是利用困惑度(Perplexity)作为Prompt学习的正则化项,通过约束Prompt的语义一致性和多样性,从而防止过拟合。作者认为,这种基于困惑度的Prompt学习本质上是一种自蒸馏,即模型自身指导自身的学习过程。
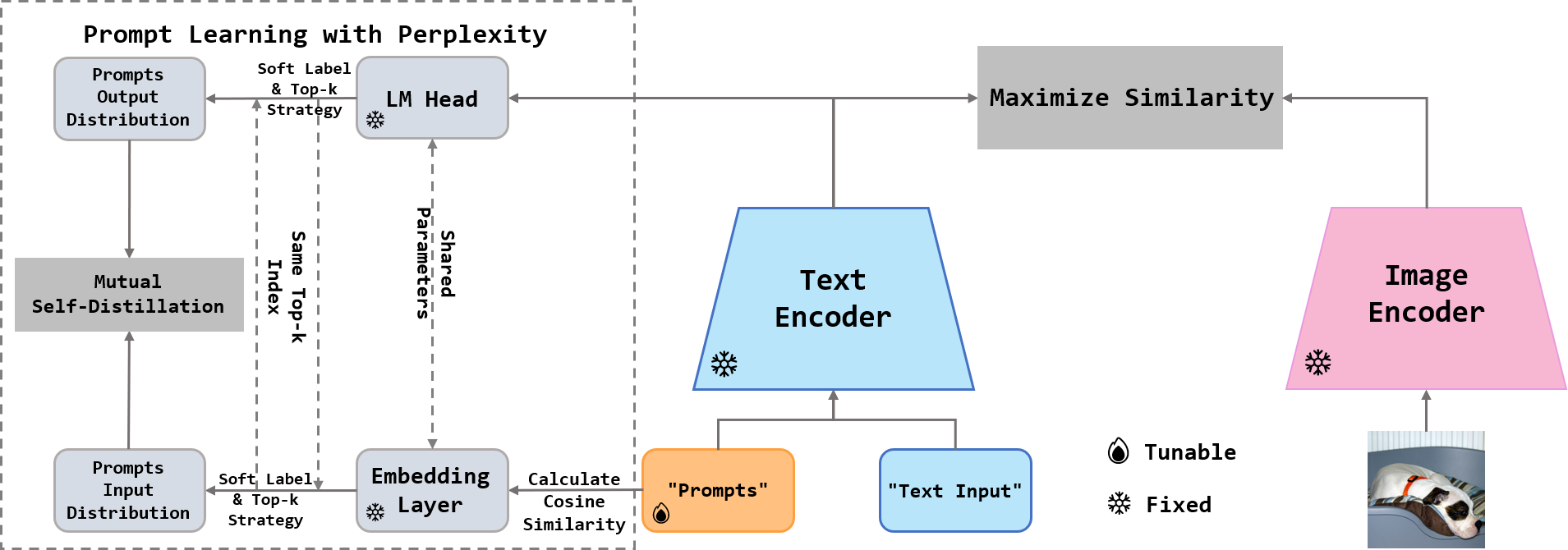
技术框架:PLPP方法主要包含以下几个模块:1) Prompt嵌入模块:使用可学习的向量作为Prompt,与文本输入一起输入到文本编码器中。2) 困惑度计算模块:首先计算嵌入层权重和Prompt之间的余弦相似度,得到硬标签;然后,通过一个无需训练的语言模型头,输出单词概率分布。3) 损失函数模块:使用困惑度损失(Perplexity Loss)正则化Prompt学习,同时引入互自蒸馏学习,即困惑度和反向困惑度损失。
关键创新:该论文的关键创新在于:1) 提出使用困惑度来正则化Prompt学习,有效防止过拟合。2) 揭示了PLPP的本质是一种自蒸馏,为Prompt Learning提供了新的视角。3) 引入互自蒸馏学习,加速模型收敛。
关键设计:1) 困惑度计算:使用余弦相似度计算Prompt与嵌入层权重的相似度,得到标签。2) 软标签:将硬标签转换为软标签,并选择top-$k$值来计算困惑度损失,减少计算量。3) 互自蒸馏:同时使用困惑度和反向困惑度损失,加速模型收敛。4) 语言模型头:使用一个无需训练的语言模型头,避免引入额外的训练参数。
🖼️ 关键图片
📊 实验亮点
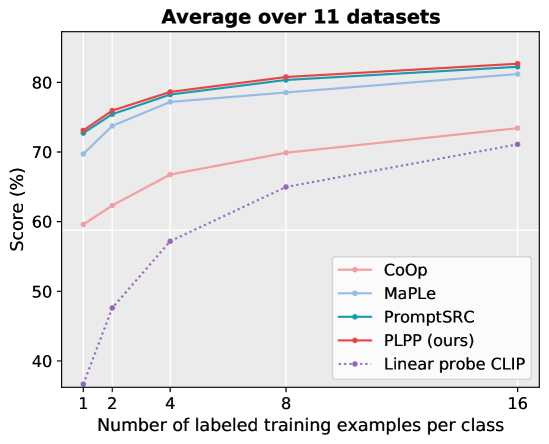
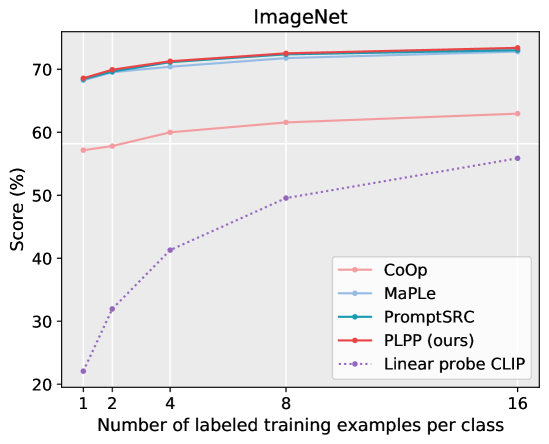
实验结果表明,PLPP在四个分类任务上均优于现有方法。例如,在某个数据集上,PLPP相比CoOp取得了显著的性能提升(具体数值未知,原文未提供)。此外,PLPP通过引入互自蒸馏学习,加速了模型收敛,提高了训练效率。
🎯 应用场景
PLPP方法可应用于各种视觉-语言任务,例如图像分类、图像检索、视觉问答等。通过提高模型的泛化能力和鲁棒性,PLPP可以提升这些任务的性能,并降低模型对特定数据集的依赖。该研究对于开发更通用、更可靠的视觉-语言模型具有重要意义。
📄 摘要(原文)
Pre-trained Vision-Language (VL) models such as CLIP have demonstrated their excellent performance across numerous downstream tasks. A recent method, Context Optimization (CoOp), further improves the performance of VL models on downstream tasks by introducing prompt learning. CoOp optimizes a set of learnable vectors, aka prompt, and freezes the whole CLIP model. However, relying solely on CLIP loss to fine-tune prompts can lead to models that are prone to overfitting on downstream task. To address this issue, we propose a plug-in prompt-regularization method called PLPP (Prompt Learning with PerPlexity), which use perplexity loss to regularize prompt learning. PLPP designs a two-step operation to compute the perplexity for prompts: (a) calculating cosine similarity between the weight of the embedding layer and prompts to get labels, (b) introducing a language model (LM) head that requires no training behind text encoder to output word probability distribution. Meanwhile, we unveil that the essence of PLPP is inherently a form of self-distillation. To further prevent overfitting as well as to reduce the additional computation introduced by PLPP, we turn the hard label to soft label and choose top-$k$ values for calculating the perplexity loss. For accelerating model convergence, we introduce mutual self-distillation learning, that is perplexity and inverted perplexity loss. The experiments conducted on four classification tasks indicate that PLPP exhibits superior performance compared to existing methods.