Memorization Over Reasoning? Exposing and Mitigating Verbatim Memorization in Large Language Models' Character Understanding Evaluation
作者: Yuxuan Jiang, Francis Ferraro
分类: cs.CL
发布日期: 2024-12-18 (更新: 2025-08-13)
💡 一句话要点
提出一种缓解LLM在角色理解评估中死记硬背的方法,揭示并减轻逐字记忆的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色理解 逐字记忆 要旨记忆 数据污染 评估方法 自然语言理解
📋 核心要点
- 大型语言模型在角色理解方面表现出色,但可能过度依赖记忆而非推理。
- 提出一种方法,通过干扰文本中的逐字记忆,迫使模型依赖要旨理解。
- 实验表明,该方法能有效降低模型对流行作品的记忆依赖,并揭示现有基准测试的数据污染问题。
📝 摘要(中文)
大型语言模型(LLM)在角色理解任务中表现出色,例如分析虚构角色的角色、个性和关系。然而,LLM使用的大规模预训练语料库引发了担忧,它们可能依赖于记忆流行的虚构作品,而不是真正理解和推理它们。本文认为,'要旨记忆'——捕捉基本含义——应该是角色理解任务的主要机制,而不是'逐字记忆'——字符串的精确匹配。我们提出了一种简单而有效的方法,以减轻角色理解评估中机械化的记忆,同时保留理解和推理所需的基本隐含线索。我们的方法将流行虚构作品中记忆驱动的性能从96%的准确率降低到72%,并导致各种角色理解任务的准确率下降高达18%。这些发现强调了现有基准测试中数据污染的问题,这些基准测试通常衡量的是记忆,而不是真正的角色理解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在角色理解评估中过度依赖“逐字记忆”的问题。现有方法在评估LLM的角色理解能力时,容易受到模型记忆训练数据集中流行作品的影响,导致评估结果无法真实反映模型的推理能力。现有方法的痛点在于无法区分模型是真正理解了角色,还是仅仅记住了相关文本片段。
核心思路:论文的核心思路是,通过一种简单有效的方法,在评估数据中干扰LLM的“逐字记忆”,迫使模型更多地依赖“要旨记忆”进行角色理解。这种方法旨在降低模型对训练数据集中精确匹配文本的依赖,从而更准确地评估模型的推理能力。
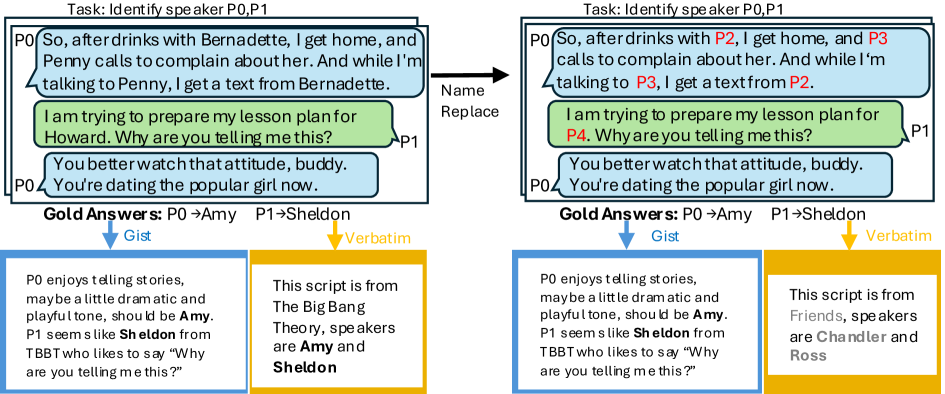
技术框架:论文提出的方法主要包含以下几个阶段:1) 识别评估数据集中可能被LLM记忆的文本片段;2) 对这些文本片段进行轻微的修改,例如替换词语、调整语序等,以破坏“逐字记忆”;3) 使用修改后的评估数据集评估LLM的角色理解能力;4) 分析评估结果,比较模型在原始数据集和修改后数据集上的表现差异,从而评估“逐字记忆”对模型性能的影响。
关键创新:论文的关键创新在于提出了一种简单有效的评估方法,能够揭示LLM在角色理解任务中对“逐字记忆”的依赖程度。与现有方法相比,该方法不需要复杂的模型训练或数据增强,而是通过对评估数据进行轻微的修改,即可有效降低模型对记忆的依赖,从而更准确地评估模型的推理能力。
关键设计:论文的关键设计在于如何修改评估数据集中的文本片段,以破坏“逐字记忆”的同时,保持文本的语义信息不变。具体的修改策略包括:1) 替换文本中的部分词语,例如使用同义词或近义词;2) 调整文本的语序,例如改变句子中词语的排列顺序;3) 对文本进行轻微的 paraphrasing,例如使用不同的表达方式描述相同的内容。这些修改策略旨在破坏模型对精确匹配文本的依赖,同时保持文本的整体语义信息不变,从而确保评估结果能够反映模型的推理能力。
🖼️ 关键图片
📊 实验亮点
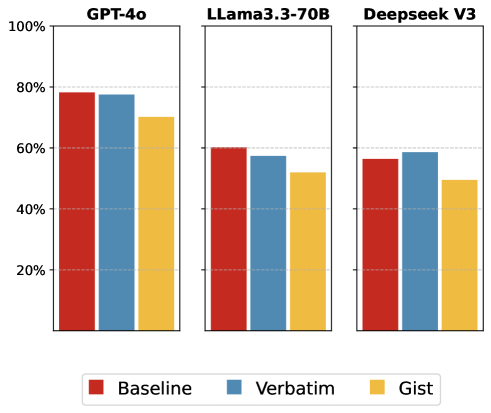
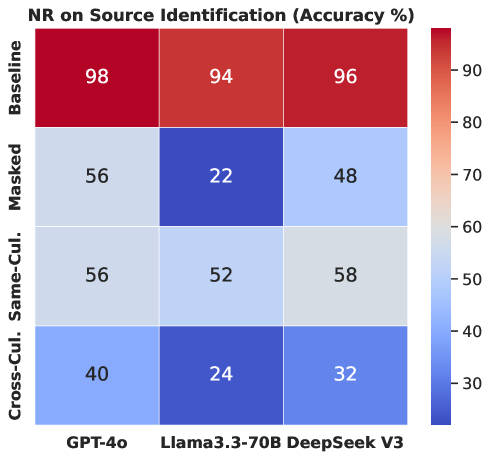
实验结果表明,该方法能够有效降低LLM对流行虚构作品的记忆依赖,将准确率从96%降低到72%。同时,在各种角色理解任务中,准确率下降高达18%。这些结果表明,现有基准测试可能高估了LLM的真实推理能力,并强调了数据污染对评估结果的影响。
🎯 应用场景
该研究成果可应用于更可靠地评估大型语言模型在各种自然语言理解任务中的推理能力,尤其是在涉及知识密集型或领域特定信息的任务中。通过减少模型对记忆的依赖,可以提高模型在实际应用中的泛化能力和鲁棒性,例如在智能客服、内容生成和知识问答等领域。
📄 摘要(原文)
Recently, Large Language Models (LLMs) have shown impressive performance in character understanding tasks, such as analyzing the roles, personalities, and relationships of fictional characters. However, the extensive pre-training corpora used by LLMs raise concerns that they may rely on memorizing popular fictional works rather than genuinely understanding and reasoning about them. In this work, we argue that 'gist memory'-capturing essential meaning - should be the primary mechanism for character understanding tasks, as opposed to 'verbatim memory' - exact match of a string. We introduce a simple yet effective method to mitigate mechanized memorization in character understanding evaluations while preserving the essential implicit cues needed for comprehension and reasoning. Our approach reduces memorization-driven performance on popular fictional works from 96% accuracy to 72% and results in up to an 18% drop in accuracy across various character understanding tasks. These findings underscore the issue of data contamination in existing benchmarks, which often measure memorization rather than true character understanding.