State Space Models are Strong Text Rerankers
作者: Zhichao Xu, Jinghua Yan, Ashim Gupta, Vivek Srikumar
分类: cs.CL, cs.IR
发布日期: 2024-12-18 (更新: 2025-04-22)
备注: Accepted to RepL4NLP 2025. The first two authors contributed equally, order decided randomly
💡 一句话要点
探索状态空间模型在文本重排序中的潜力,性能媲美Transformer。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 文本重排序 Mamba Transformer 信息检索
📋 核心要点
- Transformer模型在长文本处理中面临效率瓶颈,限制了其在信息检索等领域的应用。
- 该论文探索了状态空间模型(SSM)在文本重排序任务中的应用,旨在寻找Transformer的替代方案。
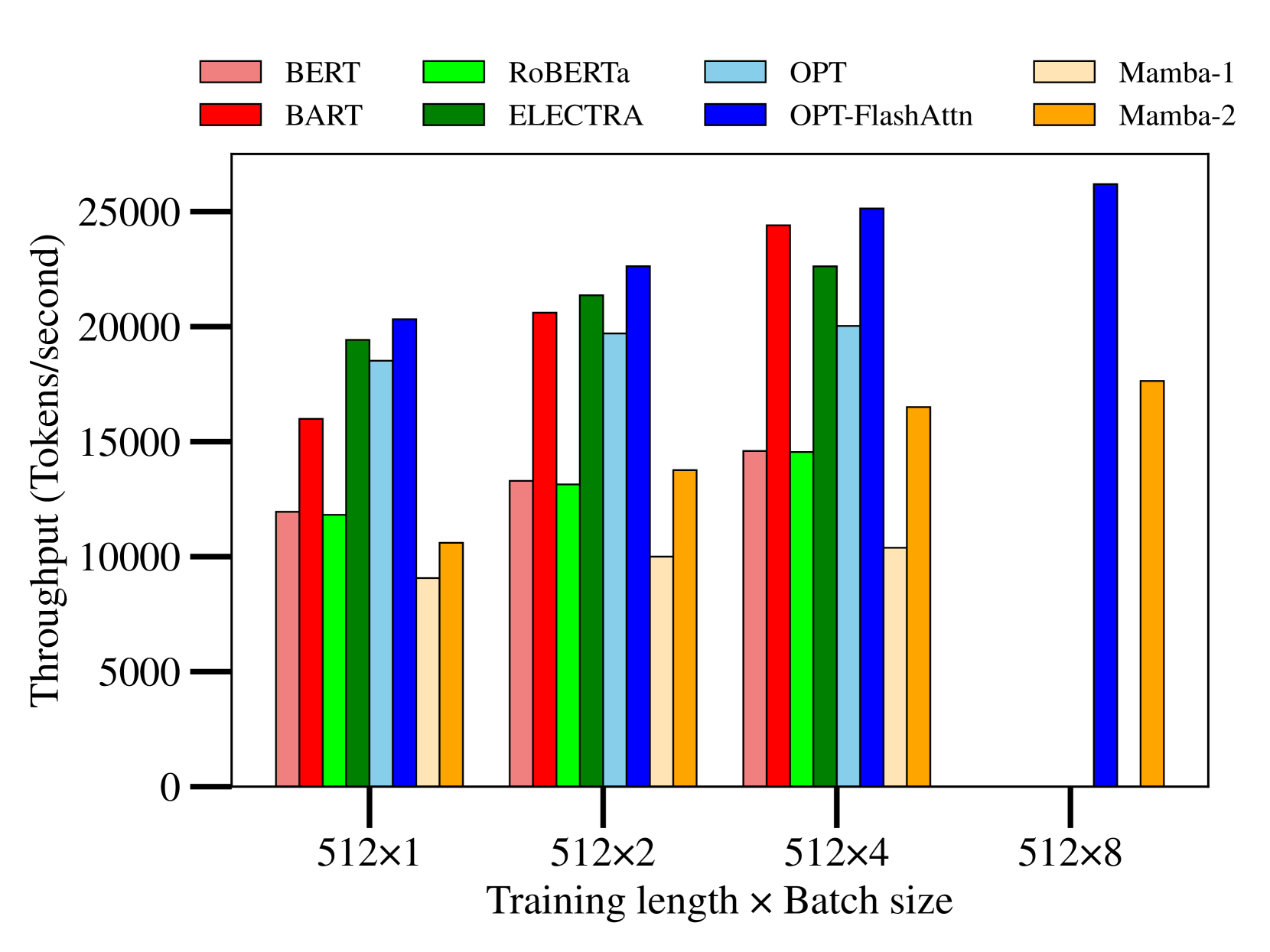
- 实验结果表明,Mamba等SSM模型在文本重排序任务中表现出与Transformer相当的性能。
📝 摘要(中文)
Transformer模型在自然语言处理和信息检索领域占据主导地位,但其推理效率低下以及难以推广到更长上下文的挑战,激发了人们对替代模型架构的兴趣。其中,像Mamba这样的状态空间模型(SSM)具有显著优势,尤其是在推理中具有O(1)的时间复杂度。尽管SSM具有潜力,但其在文本重排序方面的有效性——这是一项需要细粒度的查询-文档交互和长上下文理解的任务——仍未得到充分探索。本研究针对各种规模、架构和预训练目标的基于SSM的架构(特别是Mamba-1和Mamba-2)与基于Transformer的模型进行了基准测试,重点关注文本重排序任务中的性能和效率。我们发现:(1)Mamba架构实现了具有竞争力的文本排序性能,与类似大小的基于Transformer的模型相当;(2)与具有flash attention的Transformer相比,它们在训练和推理方面的效率较低;(3)Mamba-2在性能和效率方面均优于Mamba-1。这些结果强调了状态空间模型作为Transformer替代方案的潜力,并突出了未来IR应用中需要改进的领域。
🔬 方法详解
问题定义:论文旨在探索状态空间模型(SSM)在文本重排序任务中的有效性。现有Transformer模型虽然性能强大,但在处理长文本时面临推理效率低下的问题,并且难以推广到更长的上下文。这限制了它们在需要处理大量文本的IR任务中的应用。
核心思路:论文的核心思路是利用SSM,特别是Mamba架构,来替代Transformer进行文本重排序。Mamba具有O(1)的推理时间复杂度,理论上可以更高效地处理长文本。通过实验对比Mamba和Transformer在文本重排序任务中的性能和效率,评估SSM作为Transformer替代方案的潜力。
技术框架:该研究采用基准测试的方法,比较了不同规模、架构和预训练目标的基于SSM的架构(Mamba-1和Mamba-2)与基于Transformer的模型。实验流程包括:选择合适的文本重排序数据集,训练和评估不同模型,并分析它们的性能(如排序准确率)和效率(如训练和推理时间)。
关键创新:该研究的关键创新在于首次系统性地评估了Mamba等SSM模型在文本重排序任务中的性能。之前的研究较少关注SSM在IR任务中的应用,特别是文本重排序这种需要细粒度交互和长上下文理解的任务。该研究填补了这一空白,为SSM在IR领域的应用提供了新的视角。
关键设计:实验中,研究人员使用了不同规模的Mamba-1和Mamba-2模型,并与相同规模的Transformer模型进行了对比。他们可能使用了标准的文本重排序损失函数,如pairwise ranking loss或listwise ranking loss。具体的网络结构细节可能参考了Mamba论文中的描述,并根据文本重排序任务进行了调整。关键参数设置可能包括学习率、batch size、训练epochs等,这些参数需要根据具体数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Mamba架构在文本重排序任务中取得了与Transformer模型相当的性能。Mamba-2在性能和效率上均优于Mamba-1。然而,与使用flash attention的Transformer相比,Mamba在训练和推理效率方面仍有差距。这些结果为SSM在IR领域的应用提供了有价值的参考。
🎯 应用场景
该研究成果可应用于搜索引擎、推荐系统、问答系统等信息检索领域。通过使用更高效的SSM模型,可以提升长文本处理能力,改善用户体验,并降低计算成本。未来的研究可以进一步优化SSM模型,使其在IR任务中发挥更大的潜力。
📄 摘要(原文)
Transformers dominate NLP and IR; but their inference inefficiencies and challenges in extrapolating to longer contexts have sparked interest in alternative model architectures. Among these, state space models (SSMs) like Mamba offer promising advantages, particularly $O(1)$ time complexity in inference. Despite their potential, SSMs' effectiveness at text reranking -- a task requiring fine-grained query-document interaction and long-context understanding -- remains underexplored. This study benchmarks SSM-based architectures (specifically, Mamba-1 and Mamba-2) against transformer-based models across various scales, architectures, and pre-training objectives, focusing on performance and efficiency in text reranking tasks. We find that (1) Mamba architectures achieve competitive text ranking performance, comparable to transformer-based models of similar size; (2) they are less efficient in training and inference compared to transformers with flash attention; and (3) Mamba-2 outperforms Mamba-1 in both performance and efficiency. These results underscore the potential of state space models as a transformer alternative and highlight areas for improvement in future IR applications.