Multi-OphthaLingua: A Multilingual Benchmark for Assessing and Debiasing LLM Ophthalmological QA in LMICs
作者: David Restrepo, Chenwei Wu, Zhengxu Tang, Zitao Shuai, Thao Nguyen Minh Phan, Jun-En Ding, Cong-Tinh Dao, Jack Gallifant, Robyn Gayle Dychiao, Jose Carlo Artiaga, André Hiroshi Bando, Carolina Pelegrini Barbosa Gracitelli, Vincenz Ferrer, Leo Anthony Celi, Danielle Bitterman, Michael G Morley, Luis Filipe Nakayama
分类: cs.CL, cs.AI
发布日期: 2024-12-18
备注: Accepted at the AAAI 2025 Artificial Intelligence for Social Impact Track (AAAI-AISI 2025)
💡 一句话要点
提出Multi-OphthaLingua多语言眼科QA基准,并设计CLARA方法缓解LLM在低收入国家应用的偏见问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言 眼科 问答系统 大型语言模型 语言偏见 检索增强生成 自我验证
📋 核心要点
- 现有眼科临床流程效率低,LLM虽有潜力,但在多语言环境下存在显著性能差异,可能加剧医疗不平等。
- 论文提出CLARA,一种基于检索增强生成和自我验证的跨语言反思代理系统,用于推理时消除LLM的语言偏见。
- 实验表明,CLARA不仅提升了所有目标语言的性能,还显著缩小了多语言偏差差距,促进了LLM的公平应用。
📝 摘要(中文)
当前眼科临床工作流程面临转诊过多、等待时间过长以及医疗记录复杂且异构等问题。大型语言模型(LLM)为自动化分诊、视力评估等初步测试以及报告总结等流程提供了有希望的解决方案。然而,LLM在不同语言的自然语言问答任务中表现出显著差异,可能加剧低收入和中等收入国家(LMIC)的医疗保健差距。本研究引入了首个多语言眼科问答基准,其中包含手动策划的跨语言平行问题,从而可以进行直接的跨语言比较。我们对7种不同语言的6个流行LLM的评估揭示了不同语言之间的巨大偏差,突显了LLM在LMIC临床部署的风险。现有的去偏方法,如翻译链式思维或检索增强生成(RAG)本身无法弥合这一性能差距,通常无法提高所有语言的性能,并且缺乏针对医学领域的特异性。为了解决这个问题,我们提出了一种新颖的推理时去偏方法CLARA(跨语言反思代理系统),该方法利用检索增强生成和自我验证。我们的方法不仅提高了所有语言的性能,而且显著缩小了多语言偏差差距,从而促进了LLM在全球范围内的公平应用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多语言眼科问答任务中存在的语言偏见问题,尤其是在低收入和中等收入国家(LMIC)的应用场景下。现有方法,如直接翻译或简单的检索增强生成,无法有效消除这种偏见,导致不同语言之间的性能差异显著,从而可能加剧医疗不平等。
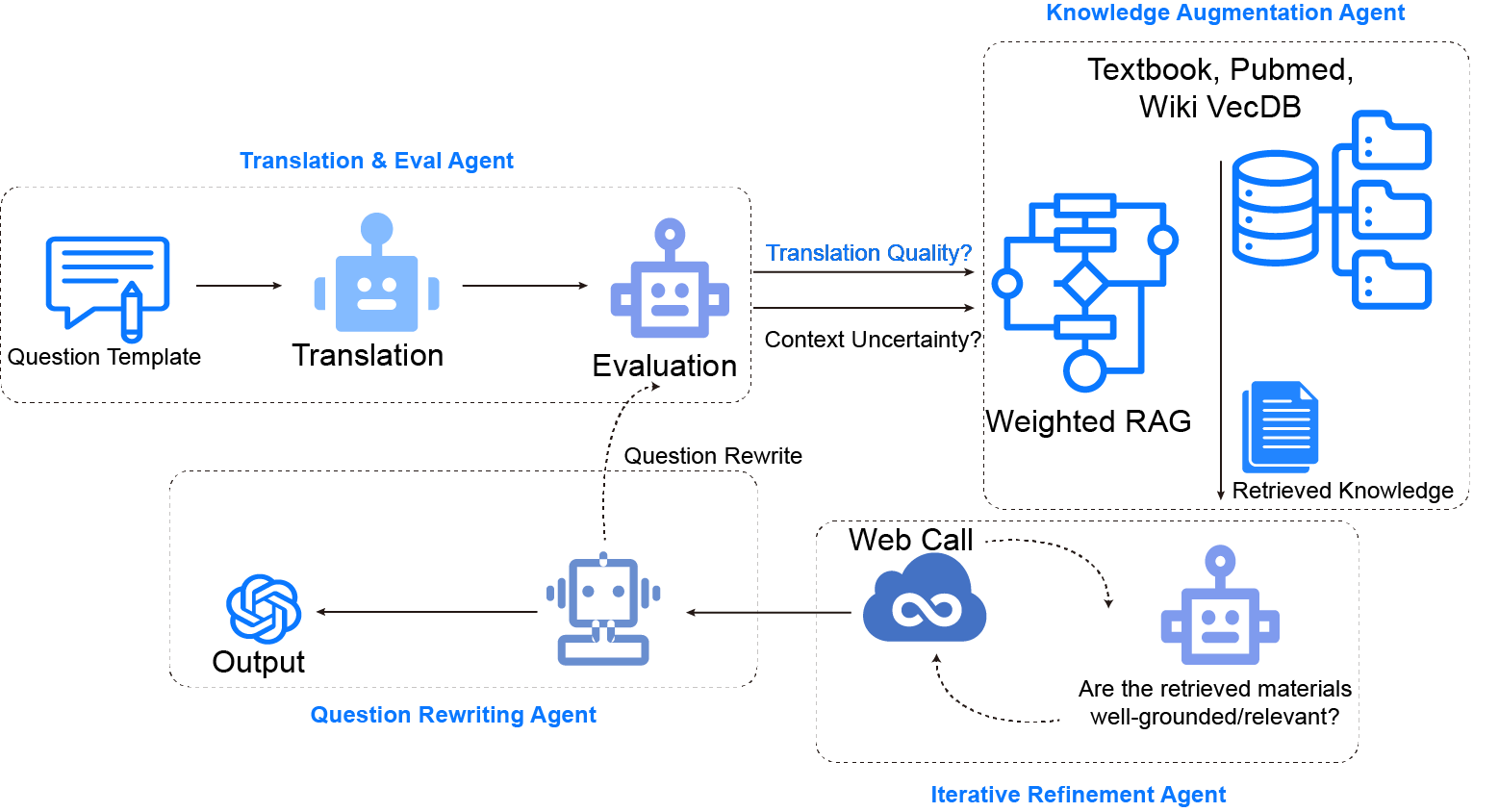
核心思路:论文的核心思路是利用检索增强生成(RAG)和自我验证机制,构建一个跨语言反思代理系统(CLARA)。通过RAG,模型可以获取更丰富的上下文信息,减少对特定语言训练数据的依赖。自我验证则允许模型评估其答案的质量,并进行迭代改进,从而减少偏见。
技术框架:CLARA的技术框架主要包含以下几个阶段:1) 问题编码:将输入问题编码为向量表示。2) 检索增强:使用编码后的问题向量从外部知识库中检索相关信息。3) 答案生成:利用检索到的信息和原始问题生成初步答案。4) 自我验证:模型评估初步答案的质量,并决定是否需要进行迭代改进。如果需要改进,则重复检索增强和答案生成步骤。
关键创新:CLARA的关键创新在于其跨语言反思代理机制。传统的RAG方法通常只关注检索相关信息,而忽略了答案的质量。CLARA通过自我验证机制,使模型能够主动评估和改进其答案,从而减少偏见。此外,CLARA的设计使其能够处理多种语言,而无需针对每种语言进行单独训练。
关键设计:CLARA的关键设计包括:1) 使用跨语言嵌入模型进行问题编码,以确保不同语言的问题具有相似的向量表示。2) 构建一个多语言眼科知识库,用于检索相关信息。3) 设计一个自我验证模块,该模块可以评估答案的准确性、完整性和一致性。4) 使用强化学习或监督学习方法训练自我验证模块,使其能够有效地识别和纠正错误答案。
🖼️ 关键图片

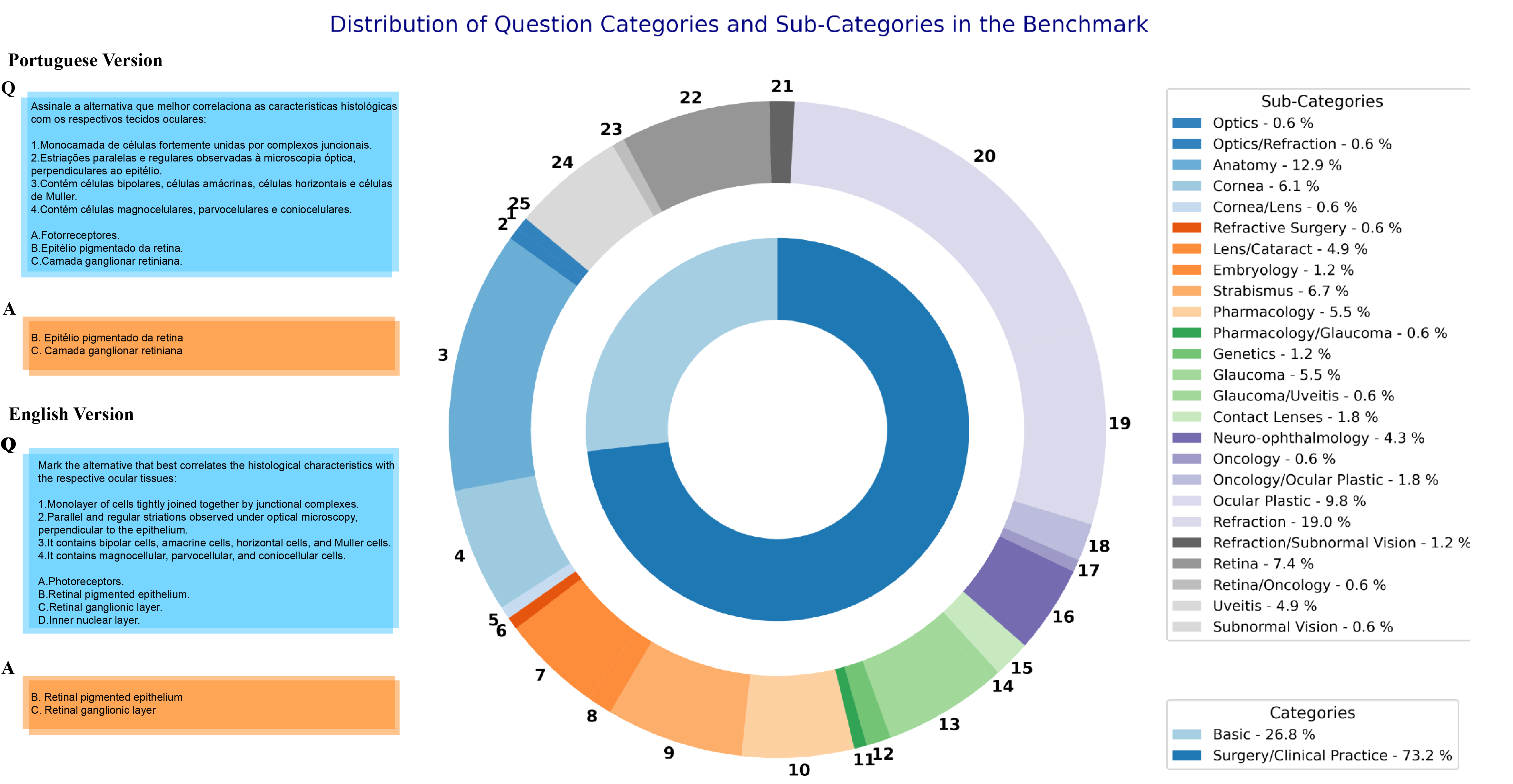
📊 实验亮点
实验结果表明,CLARA在多语言眼科问答任务中显著优于现有的基线方法,包括直接翻译和简单的RAG。CLARA不仅提高了所有目标语言的性能,还显著缩小了多语言偏差差距。例如,在某些语言上,CLARA的性能提升超过10%,并且在所有语言上的性能差异降低了5%以上。
🎯 应用场景
该研究成果可应用于多语言环境下的眼科疾病诊断和治疗,尤其是在医疗资源匮乏的低收入和中等收入国家。通过消除LLM的语言偏见,可以为不同语言背景的患者提供更公平、更准确的医疗服务,提高诊断效率,降低医疗成本,并最终改善患者的健康状况。
📄 摘要(原文)
Current ophthalmology clinical workflows are plagued by over-referrals, long waits, and complex and heterogeneous medical records. Large language models (LLMs) present a promising solution to automate various procedures such as triaging, preliminary tests like visual acuity assessment, and report summaries. However, LLMs have demonstrated significantly varied performance across different languages in natural language question-answering tasks, potentially exacerbating healthcare disparities in Low and Middle-Income Countries (LMICs). This study introduces the first multilingual ophthalmological question-answering benchmark with manually curated questions parallel across languages, allowing for direct cross-lingual comparisons. Our evaluation of 6 popular LLMs across 7 different languages reveals substantial bias across different languages, highlighting risks for clinical deployment of LLMs in LMICs. Existing debiasing methods such as Translation Chain-of-Thought or Retrieval-augmented generation (RAG) by themselves fall short of closing this performance gap, often failing to improve performance across all languages and lacking specificity for the medical domain. To address this issue, We propose CLARA (Cross-Lingual Reflective Agentic system), a novel inference time de-biasing method leveraging retrieval augmented generation and self-verification. Our approach not only improves performance across all languages but also significantly reduces the multilingual bias gap, facilitating equitable LLM application across the globe.