Fake News Detection: Comparative Evaluation of BERT-like Models and Large Language Models with Generative AI-Annotated Data
作者: Shaina Raza, Drai Paulen-Patterson, Chen Ding
分类: cs.CL, cs.AI
发布日期: 2024-12-18 (更新: 2024-12-20)
备注: Accepted in Knowledge and Information Systems Journal
💡 一句话要点
利用生成式AI标注数据,对比BERT类模型与大语言模型在假新闻检测中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 假新闻检测 大语言模型 BERT GPT-4 人工智能标注
📋 核心要点
- 假新闻对社会稳定构成威胁,现有方法难以兼顾准确性和鲁棒性。
- 利用GPT-4辅助标注并人工验证,构建高质量数据集,并探索指令调优LLM方法。
- 实验表明,BERT类模型分类性能更优,LLMs对文本扰动更鲁棒,AI标注结合人工监督效果最佳。
📝 摘要(中文)
本研究对比了BERT类编码器模型和自回归解码器大语言模型(LLMs)在假新闻检测中的性能。我们引入了一个由GPT-4辅助标注并经人工专家验证的新闻文章数据集,以确保其可靠性。BERT类模型和LLMs都在此数据集上进行了微调。此外,我们还开发了一种指令调优的LLM方法,在推理过程中采用多数投票进行标签生成。分析表明,BERT类模型在分类任务中通常优于LLMs,而LLMs在文本扰动方面表现出更强的鲁棒性。与弱标签(远监督)数据相比,结果表明,人工智能标签与人工监督相结合可以获得更好的分类结果。这项研究强调了将基于人工智能的标注与人工监督相结合的有效性,并展示了不同机器学习模型族在假新闻检测中的性能。
🔬 方法详解
问题定义:论文旨在解决假新闻检测问题。现有方法,如基于弱标签的远监督学习,标注质量不高,影响模型性能。同时,模型在面对文本扰动时,鲁棒性较差。
核心思路:论文的核心思路是结合生成式AI(GPT-4)的标注能力和人工专家的验证,构建高质量的标注数据集。同时,对比BERT类模型和LLMs在假新闻检测任务上的性能,并探索指令调优LLM方法,以提高模型的鲁棒性和泛化能力。
技术框架:整体框架包括数据标注阶段、模型训练阶段和模型评估阶段。数据标注阶段使用GPT-4对新闻文章进行标注,然后由人工专家进行验证和修正。模型训练阶段分别对BERT类模型和LLMs进行微调。模型评估阶段对比不同模型在分类准确率和鲁棒性方面的表现。
关键创新:论文的关键创新在于结合生成式AI和人工监督的数据标注方法,以及对BERT类模型和LLMs在假新闻检测任务上的全面对比分析。此外,指令调优的LLM方法也是一个创新点,旨在提高LLMs在特定任务上的性能。
关键设计:在数据标注方面,采用了GPT-4进行初步标注,然后由人工专家进行验证和修正,以确保标注质量。在模型训练方面,使用了标准的微调方法,并针对LLMs采用了指令调优策略。在模型评估方面,使用了准确率、召回率、F1值等指标来评估模型的性能,并设计了文本扰动实验来评估模型的鲁棒性。指令调优LLM时,采用了多数投票的方式进行标签生成。
🖼️ 关键图片
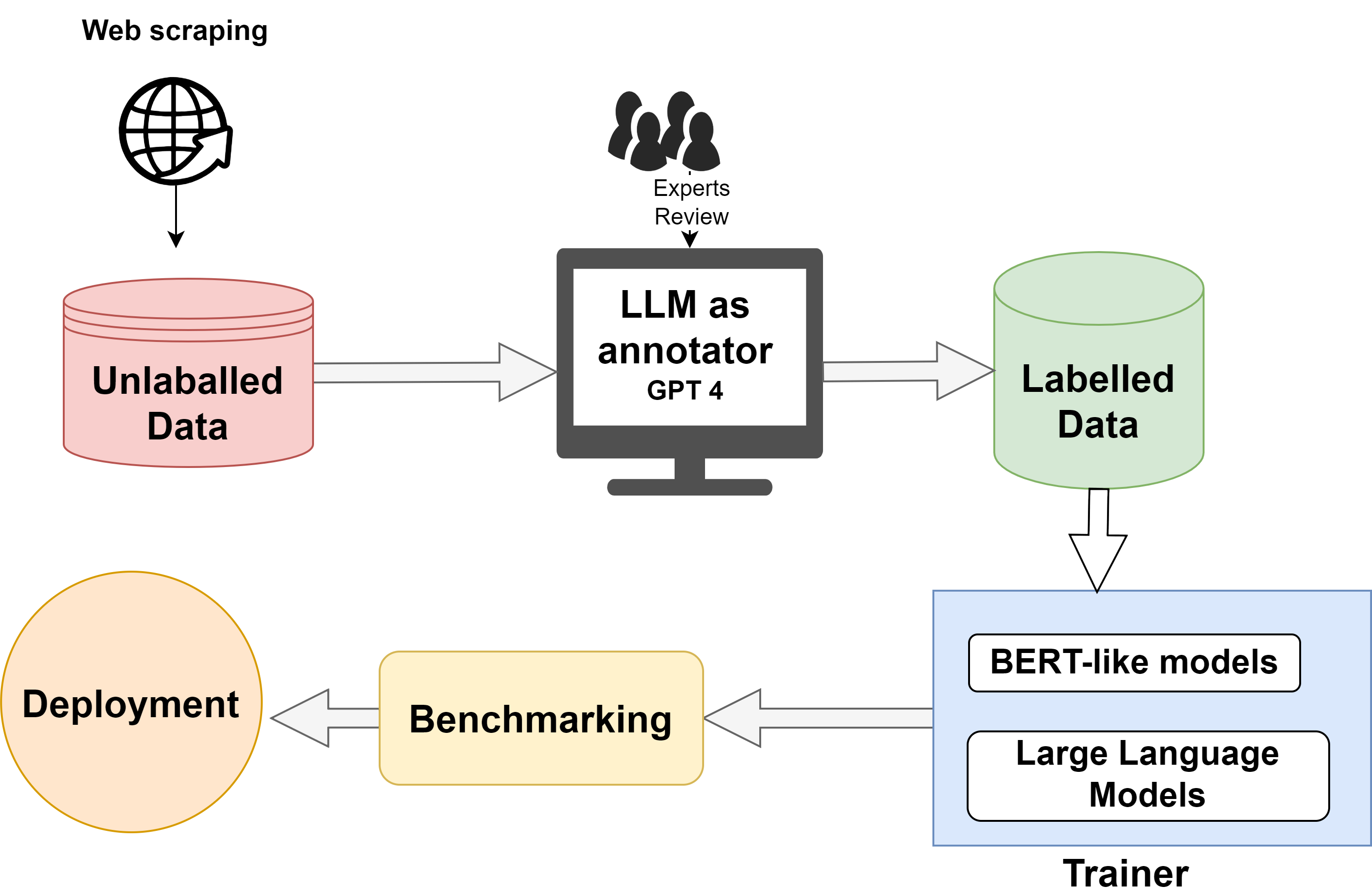

📊 实验亮点
实验结果表明,BERT类模型在分类准确率上优于LLMs,但LLMs在文本扰动方面表现出更强的鲁棒性。AI标注结合人工监督的数据集比弱标签数据集取得了更好的分类效果,验证了高质量数据的重要性。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,用于自动检测和过滤虚假新闻,减少虚假信息传播,维护社会稳定。高质量标注数据集的构建方法也为其他自然语言处理任务提供了借鉴。
📄 摘要(原文)
Fake news poses a significant threat to public opinion and social stability in modern society. This study presents a comparative evaluation of BERT-like encoder-only models and autoregressive decoder-only large language models (LLMs) for fake news detection. We introduce a dataset of news articles labeled with GPT-4 assistance (an AI-labeling method) and verified by human experts to ensure reliability. Both BERT-like encoder-only models and LLMs were fine-tuned on this dataset. Additionally, we developed an instruction-tuned LLM approach with majority voting during inference for label generation. Our analysis reveals that BERT-like models generally outperform LLMs in classification tasks, while LLMs demonstrate superior robustness against text perturbations. Compared to weak labels (distant supervision) data, the results show that AI labels with human supervision achieve better classification results. This study highlights the effectiveness of combining AI-based annotation with human oversight and demonstrates the performance of different families of machine learning models for fake news detection