TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
作者: Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, Graham Neubig
分类: cs.CL
发布日期: 2024-12-18 (更新: 2025-09-10)
备注: Preprint
💡 一句话要点
TheAgentCompany:构建基准测试,评估LLM智能体在真实世界任务中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 基准测试 真实世界任务 自动化办公 软件公司环境
📋 核心要点
- 现有AI智能体在自主执行工作相关任务方面的能力尚不明确,这对于行业采用AI以及经济政策理解AI对劳动力市场的影响至关重要。
- TheAgentCompany基准测试通过模拟小型软件公司环境,评估AI智能体在浏览网页、编写代码和沟通协作等真实工作场景中的表现。
- 实验结果表明,当前最佳的LLM智能体可以自主完成30%的任务,表明其在简单任务上具备潜力,但在复杂任务上仍有局限性。
📝 摘要(中文)
本文介绍了TheAgentCompany,一个可扩展的基准测试,用于评估AI智能体在执行真实世界专业任务时的性能。这些智能体通过浏览网页、编写代码、运行程序以及与其他同事交流等方式与世界互动,类似于数字化员工。该基准测试构建了一个自包含的环境,包含内部网站和数据,模拟小型软件公司环境,并创建了各种可由公司员工执行的任务。论文测试了由闭源API和开源语言模型驱动的基线智能体,发现最具竞争力的智能体可以自主完成30%的任务。这表明,在模拟真实工作场所的环境中,LM智能体可以在一定程度上自主解决较简单的任务,但更困难的长期任务仍然超出当前系统的能力范围。代码、数据、环境和实验已在https://the-agent-company.com上发布。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)驱动的智能体在模拟真实世界工作环境中的表现。现有方法缺乏一个综合性的基准测试,难以准确衡量这些智能体在复杂、长期任务中的能力,尤其是在涉及多步骤操作、工具使用和人机交互的场景下。
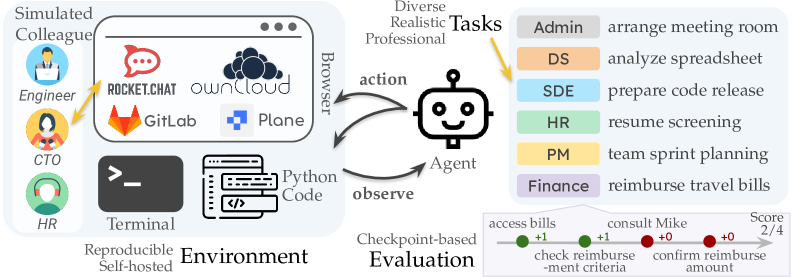
核心思路:论文的核心思路是构建一个自包含的、可扩展的模拟软件公司环境,TheAgentCompany。该环境模拟了真实公司内部的网站、数据和协作流程,并设计了一系列具有实际意义的工作任务,例如网页浏览、代码编写、程序运行和同事沟通。通过让LLM智能体在这一环境中执行这些任务,可以更全面地评估其在真实工作场景中的能力。
技术框架:TheAgentCompany环境包含以下主要组成部分:1) 模拟的软件公司环境,包括内部网站、数据库和API;2) 一系列预定义的任务,涵盖软件开发、数据分析、客户支持等多个领域;3) 一套评估指标,用于衡量智能体完成任务的成功率、效率和质量;4) 基于LLM的智能体,通过与环境交互来完成任务。智能体可以使用各种工具,例如浏览器、代码编辑器和命令行界面。
关键创新:该论文的关键创新在于构建了一个高度仿真的工作环境,能够更真实地反映LLM智能体在实际应用中的表现。与以往的基准测试相比,TheAgentCompany更加注重任务的复杂性、长期性和交互性,从而能够更全面地评估智能体的能力。此外,该基准测试具有良好的可扩展性,可以方便地添加新的任务和工具,以适应不断发展的AI技术。
关键设计:TheAgentCompany环境的设计考虑了以下关键因素:1) 任务的多样性,涵盖了不同难度和类型的任务,以全面评估智能体的能力;2) 环境的真实性,尽可能模拟真实的工作场景,例如内部网站的设计和数据的生成;3) 评估指标的客观性,采用清晰明确的指标来衡量智能体的表现,例如任务完成率、执行时间和资源消耗;4) 智能体的可配置性,允许用户自定义智能体的行为和参数,以便进行更深入的研究。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于LLM的智能体在TheAgentCompany环境中可以自主完成30%的任务。这表明,在模拟真实工作场所的环境中,LM智能体可以在一定程度上自主解决较简单的任务,但更困难的长期任务仍然超出当前系统的能力范围。该基准测试为评估和改进LLM智能体在真实世界任务中的表现提供了一个有价值的平台。
🎯 应用场景
该研究成果可应用于评估和改进LLM智能体在自动化办公、软件开发、客户服务等领域的应用。通过TheAgentCompany基准测试,可以更好地了解当前AI智能体的能力边界,并指导未来的研究方向,加速AI技术在实际工作场景中的落地,最终提升工作效率和生产力。
📄 摘要(原文)
We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at accelerating or even autonomously performing work-related tasks? The answer to this question has important implications both for industry looking to adopt AI into their workflows and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that the most competitive agent can complete 30% of tasks autonomously. This paints a nuanced picture on task automation with LM agents--in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems. We release code, data, environment, and experiments on https://the-agent-company.com.