Prompting Strategies for Enabling Large Language Models to Infer Causation from Correlation
作者: Eleni Sgouritsa, Virginia Aglietti, Yee Whye Teh, Arnaud Doucet, Arthur Gretton, Silvia Chiappa
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-18
💡 一句话要点
提出PC-SubQ提示策略,提升大语言模型基于相关性推断因果关系的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 因果推理 提示工程 PC算法 相关性分析
📋 核心要点
- 现有大语言模型在基于相关性推断因果关系的任务中表现不佳,面临着推理能力的挑战。
- 论文提出PC-SubQ提示策略,将因果发现任务分解为PC算法的子问题,引导LLM逐步推理。
- 实验表明,PC-SubQ策略在多个LLM上优于基线方法,且对查询扰动具有鲁棒性。
📝 摘要(中文)
本文关注大语言模型(LLM)的推理能力,特别是基于相关性信息建立因果关系这一极具挑战性的任务,现有LLM在此任务上表现不佳。为此,我们提出了一种提示策略,将原始任务分解为一系列固定的子问题,每个子问题对应于形式化因果发现算法(PC算法)的一个步骤。该策略名为PC-SubQ,通过依次提示LLM回答每个子问题,并将先前答案添加到后续提示中,引导LLM遵循算法步骤。我们在现有的因果基准Corr2Cause上评估了该方法,实验表明,与基线提示策略相比,PC-SubQ在五个LLM上均实现了性能提升。结果表明,该方法对因果查询扰动具有鲁棒性,即使修改变量名或释义表达式,性能依然稳定。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)难以从相关性数据中准确推断因果关系的问题。现有方法,例如直接提示LLM进行因果推断,效果不佳,因为LLM缺乏系统性的因果推理能力,容易受到数据中的噪声和混淆因素的影响。
核心思路:论文的核心思路是将复杂的因果推断任务分解为一系列更小、更易于处理的子问题,每个子问题对应于PC算法的一个步骤。通过逐步引导LLM完成这些子问题,可以模拟PC算法的推理过程,从而提高因果推断的准确性。这种分解策略借鉴了算法的结构化推理方式,降低了LLM直接处理复杂问题的难度。
技术框架:PC-SubQ提示策略的核心在于将PC算法的步骤转化为一系列提示。整体流程如下: 1. 初始化:向LLM提供背景信息和初始问题。 2. 子问题提示:根据PC算法的步骤,依次向LLM提出子问题,例如“变量A和B是否条件独立?”。 3. 答案收集:收集LLM对每个子问题的回答。 4. 提示增强:将先前子问题的答案添加到后续子问题的提示中,形成上下文信息。 5. 因果图构建:根据LLM对所有子问题的回答,构建因果图。
关键创新:该方法最重要的创新在于将形式化的因果发现算法(PC算法)与大语言模型的提示工程相结合。与直接提示LLM进行因果推断相比,PC-SubQ策略通过分解任务,引导LLM逐步推理,从而提高了因果推断的准确性和可靠性。这种方法充分利用了LLM的语言理解和生成能力,同时借鉴了因果发现算法的结构化推理框架。
关键设计:PC-SubQ策略的关键设计在于子问题的划分和提示的构建。子问题的划分需要精确对应PC算法的步骤,确保每个子问题都能够有效地引导LLM进行推理。提示的构建需要清晰简洁,避免引入歧义或噪声。论文中没有提及具体的参数设置或损失函数,因为该方法主要关注提示策略的设计,而非模型训练。
🖼️ 关键图片


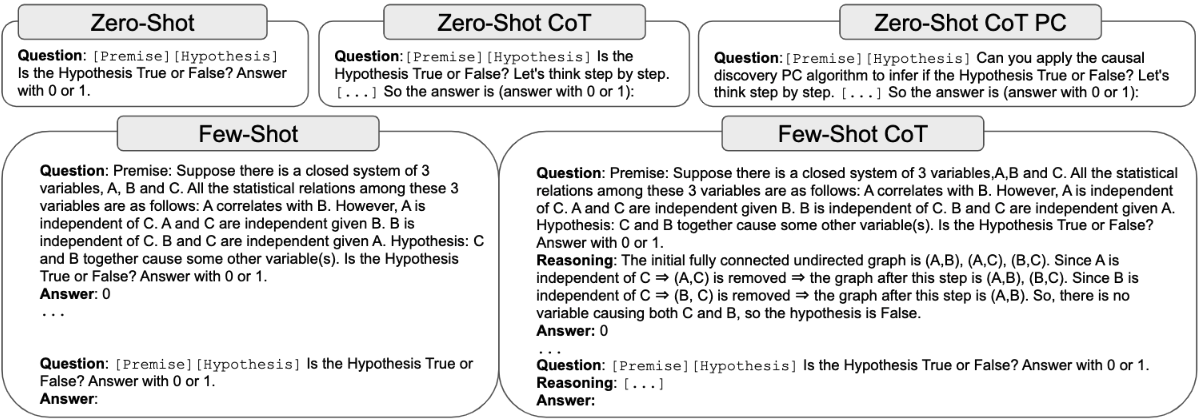
📊 实验亮点
实验结果表明,PC-SubQ提示策略在Corr2Cause基准测试中,显著提升了五个不同LLM的因果推理性能。与基线提示策略相比,PC-SubQ在准确率方面取得了显著提升,并且对变量名称修改和表达式释义等扰动具有较强的鲁棒性。这些结果验证了PC-SubQ策略的有效性和通用性。
🎯 应用场景
该研究成果可应用于多个领域,例如医疗诊断、金融风险评估、市场营销等。通过利用大语言模型从相关性数据中推断因果关系,可以帮助决策者更好地理解复杂系统,制定更有效的策略。未来,该方法可以与其他因果发现算法相结合,进一步提高因果推断的准确性和效率。
📄 摘要(原文)
The reasoning abilities of Large Language Models (LLMs) are attracting increasing attention. In this work, we focus on causal reasoning and address the task of establishing causal relationships based on correlation information, a highly challenging problem on which several LLMs have shown poor performance. We introduce a prompting strategy for this problem that breaks the original task into fixed subquestions, with each subquestion corresponding to one step of a formal causal discovery algorithm, the PC algorithm. The proposed prompting strategy, PC-SubQ, guides the LLM to follow these algorithmic steps, by sequentially prompting it with one subquestion at a time, augmenting the next subquestion's prompt with the answer to the previous one(s). We evaluate our approach on an existing causal benchmark, Corr2Cause: our experiments indicate a performance improvement across five LLMs when comparing PC-SubQ to baseline prompting strategies. Results are robust to causal query perturbations, when modifying the variable names or paraphrasing the expressions.