A Rose by Any Other Name: LLM-Generated Explanations Are Good Proxies for Human Explanations to Collect Label Distributions on NLI
作者: Beiduo Chen, Siyao Peng, Anna Korhonen, Barbara Plank
分类: cs.CL
发布日期: 2024-12-18 (更新: 2025-05-30)
备注: Accepted by ACL 2025 Findings, 25 pages, 21 figures
💡 一句话要点
利用LLM生成解释作为人类解释的替代,用于自然语言推理中标签分布的收集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言推理 大型语言模型 人类判断分布 标签解释 标注变异
📋 核心要点
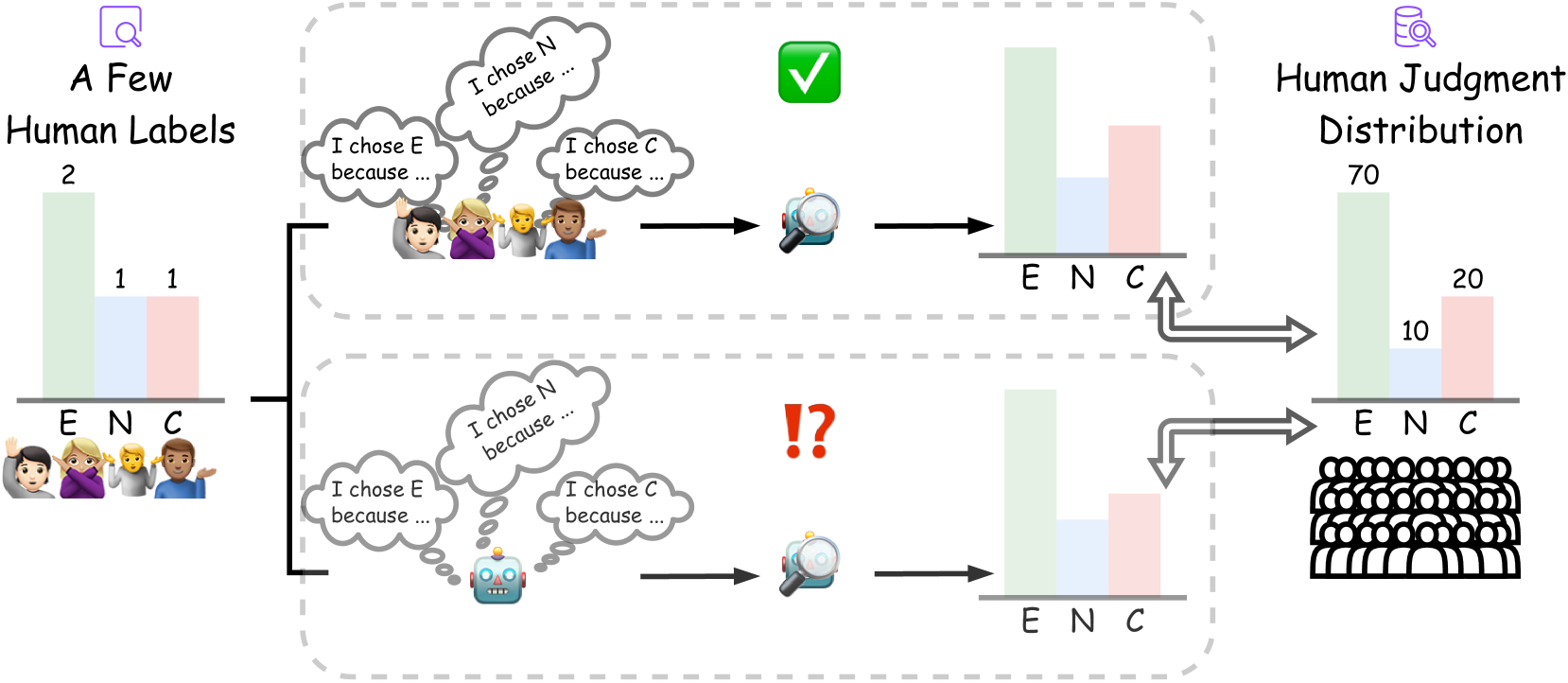
- 人类标注存在不一致性,理解这种变异需要耗时的人工解释,现有方法难以高效获取。
- 利用LLM生成标签解释,并将其作为人类解释的替代,以近似人类判断分布(HJD)。
- 实验表明,LLM生成的解释在NLI任务中,能够以与人类解释相当的性能估计HJD,并具有良好的泛化能力。
📝 摘要(中文)
人类标注中存在广泛的不一致性,这种不一致性可以通过人类判断分布(HJD)来捕捉。最近的研究表明,解释为理解人类标签变异(HLV)提供了有价值的信息,并且大型语言模型(LLM)可以从少量人工提供的标签-解释对中近似HJD。然而,为每个标签收集解释仍然非常耗时。本文探讨了是否可以使用LLM来代替人类生成解释,从而近似HJD。具体来说,我们使用LLM作为标注者,为少量给定的人工标签生成模型解释。我们测试了获取和组合这些标签-解释的方法,目标是近似人类判断分布。我们进一步比较了由此产生的人工解释和模型生成的解释,并测试了自动和人工解释选择。实验表明,LLM解释在NLI任务中很有前景:在提供人工标签的情况下,生成的解释在估计HJD方面产生了与人工解释相当的结果。重要的是,我们的结果可以从具有人工解释的数据集推广到i)没有人工解释的数据集和ii)具有挑战性的分布外测试集。
🔬 方法详解
问题定义:论文旨在解决自然语言推理(NLI)任务中,由于人类标注存在不一致性,导致难以准确获取标签分布的问题。现有方法依赖于耗时的人工解释来理解这种变异,成本高昂且效率低下。因此,如何利用更高效的方法来近似人类判断分布(HJD)成为一个关键挑战。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成标签解释,并将其作为人类解释的替代品。通过让LLM为给定的少量人工标签生成解释,并结合这些标签-解释对来近似HJD。这种方法旨在降低对大量人工解释的依赖,从而提高效率并降低成本。
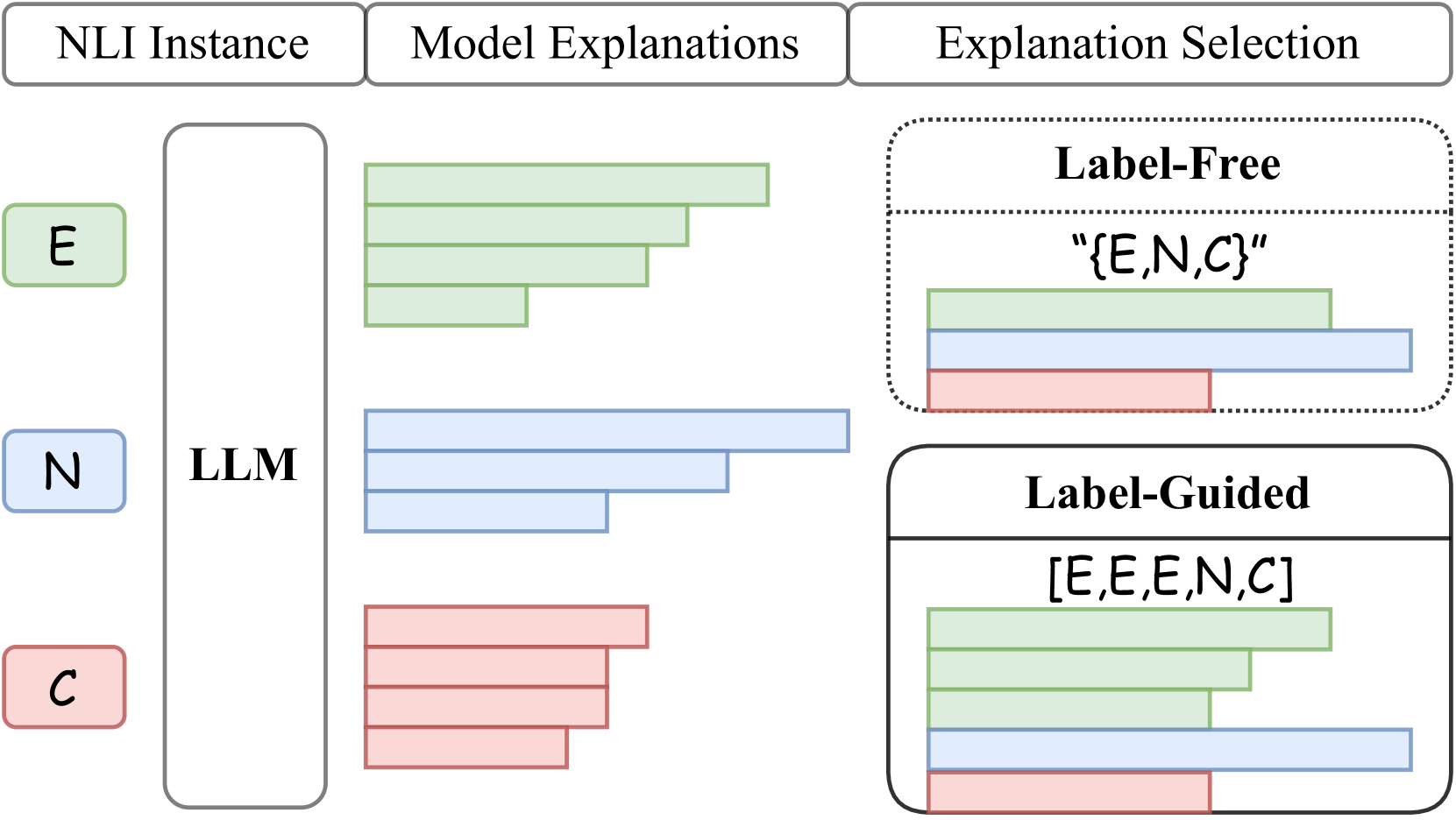
技术框架:整体流程包括以下几个主要阶段:1) 人工提供少量标签;2) 使用LLM为这些标签生成对应的解释;3) 设计方法来获取和组合这些标签-解释对;4) 使用这些组合后的标签-解释对来近似人类判断分布(HJD);5) 评估近似HJD的性能,并与使用人工解释的结果进行比较。
关键创新:最重要的技术创新点在于,证明了LLM生成的解释可以作为人类解释的有效替代品,用于近似人类判断分布。这为在缺乏大量人工解释的情况下,理解和建模人类标注变异提供了一种新的途径。与现有方法相比,该方法显著降低了对人工标注的依赖,提高了效率。
关键设计:论文测试了多种获取和组合LLM生成的标签-解释的方法,以优化HJD的近似效果。具体的技术细节包括:如何提示LLM生成高质量的解释,如何选择和组合不同的解释,以及如何评估生成的解释的质量。此外,论文还比较了自动和人工解释选择方法,以进一步提高HJD的近似精度。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在NLI任务中,使用LLM生成的解释来估计HJD,可以获得与使用人工解释相当的性能。更重要的是,该方法具有良好的泛化能力,可以从具有人工解释的数据集推广到没有人工解释的数据集和具有挑战性的分布外测试集。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于自然语言处理的多个领域,例如情感分析、文本分类、问答系统等。通过利用LLM生成的解释来理解和建模人类标注变异,可以提高模型的鲁棒性和泛化能力,尤其是在标注数据质量不高或存在偏差的情况下。此外,该方法还可以用于构建更可靠的众包标注平台,降低标注成本。
📄 摘要(原文)
Disagreement in human labeling is ubiquitous, and can be captured in human judgment distributions (HJDs). Recent research has shown that explanations provide valuable information for understanding human label variation (HLV) and large language models (LLMs) can approximate HJD from a few human-provided label-explanation pairs. However, collecting explanations for every label is still time-consuming. This paper examines whether LLMs can be used to replace humans in generating explanations for approximating HJD. Specifically, we use LLMs as annotators to generate model explanations for a few given human labels. We test ways to obtain and combine these label-explanations with the goal to approximate human judgment distributions. We further compare the resulting human with model-generated explanations, and test automatic and human explanation selection. Our experiments show that LLM explanations are promising for NLI: to estimate HJDs, generated explanations yield comparable results to human's when provided with human labels. Importantly, our results generalize from datasets with human explanations to i) datasets where they are not available and ii) challenging out-of-distribution test sets.