Pipeline Analysis for Developing Instruct LLMs in Low-Resource Languages: A Case Study on Basque
作者: Ander Corral, Ixak Sarasua, Xabier Saralegi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-18
💡 一句话要点
针对低资源语言巴斯克语,提出Instruct LLM开发流程分析与优化方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 大型语言模型 指令调优 人类偏好对齐 巴斯克语 持续预训练 自然语言理解
📋 核心要点
- 现有LLM对高资源语言优化,低资源语言面临性能挑战,存在显著差距。
- 通过持续预训练、指令调优和人类偏好对齐,提升低资源语言LLM性能。
- 实验表明,该方法在巴斯克语上显著提升NLU和指令遵循能力,达到SOTA。
📝 摘要(中文)
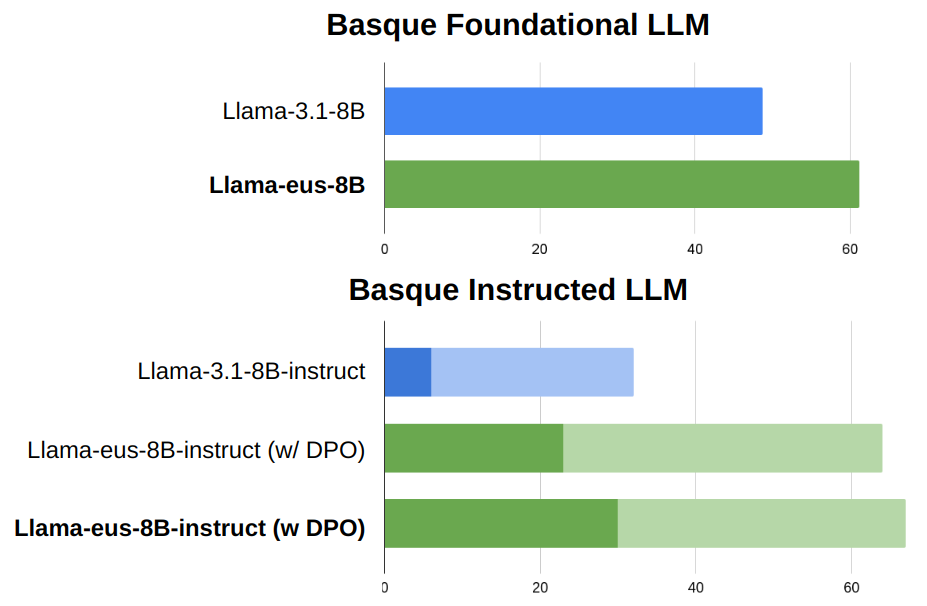
大型语言模型(LLMs)通常针对英语等资源丰富的语言进行优化,加剧了高资源语言和代表性不足的语言之间的差距。本文针对低资源语言,特别是巴斯克语,提出了一个详细的策略分析,旨在开发一个能够遵循指令的模型。该分析侧重于三个关键阶段:预训练、指令调优以及与人类偏好对齐。研究结果表明,使用约6亿词的高质量巴斯克语语料库进行持续预训练,可将基础模型的自然语言理解(NLU)能力提高12个百分点以上。此外,使用自动翻译的数据集进行指令调优和人类偏好对齐非常有效,从而使指令遵循性能提高了24个百分点。由此产生的模型Llama-eus-8B和Llama-eus-8B-instruct,在小于100亿参数的类别中,为巴斯克语建立了新的技术水平。
🔬 方法详解
问题定义:论文旨在解决低资源语言(如巴斯克语)的大型语言模型(LLM)开发问题。现有LLM主要针对高资源语言优化,直接应用于低资源语言时性能不佳,无法有效理解和生成符合人类指令的文本。现有方法缺乏针对低资源语言的有效训练策略,导致模型性能受限。
核心思路:论文的核心思路是通过三个关键阶段的优化,提升低资源语言LLM的性能:首先,使用高质量的低资源语言语料库进行持续预训练,增强模型对该语言的理解能力;其次,利用自动翻译技术生成指令调优数据集,使模型能够更好地遵循指令;最后,通过人类偏好对齐,进一步提升模型的生成质量和用户满意度。
技术框架:整体框架包含三个主要阶段:1) 持续预训练:使用巴斯克语语料库对预训练模型进行进一步训练,提升其对巴斯克语的理解能力。2) 指令调优:使用自动翻译的指令数据集对模型进行微调,使其能够更好地遵循指令。3) 人类偏好对齐:使用自动翻译的数据集进行奖励模型训练,然后使用强化学习对模型进行微调,使其更好地符合人类偏好。
关键创新:论文的关键创新在于针对低资源语言,提出了一个完整的LLM开发流程,并验证了该流程的有效性。具体包括:1) 强调了持续预训练的重要性,证明了使用高质量低资源语料库可以显著提升模型性能。2) 提出了使用自动翻译数据进行指令调优和人类偏好对齐的方法,有效解决了低资源语言数据稀缺的问题。
关键设计:在持续预训练阶段,使用了约6亿词的巴斯克语语料库。在指令调优阶段,使用了自动翻译的指令数据集,并进行了超参数优化。在人类偏好对齐阶段,使用了自动翻译的数据集训练奖励模型,并使用强化学习算法(未知)对模型进行微调。具体的损失函数和网络结构细节未在摘要中详细说明。
🖼️ 关键图片
📊 实验亮点
实验结果表明,持续预训练使基础模型的自然语言理解(NLU)能力提高了12个百分点以上。指令调优和人类偏好对齐使指令遵循性能提高了24个百分点。最终得到的Llama-eus-8B和Llama-eus-8B-instruct模型,在小于100亿参数的类别中,为巴斯克语建立了新的技术水平,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种低资源语言的LLM开发,例如机器翻译、文本摘要、问答系统等。通过提升低资源语言的LLM性能,可以促进这些语言的数字化发展,并为使用这些语言的人们提供更好的信息服务。该方法具有很高的实际价值,有助于弥合数字鸿沟,促进语言多样性。
📄 摘要(原文)
Large language models (LLMs) are typically optimized for resource-rich languages like English, exacerbating the gap between high-resource and underrepresented languages. This work presents a detailed analysis of strategies for developing a model capable of following instructions in a low-resource language, specifically Basque, by focusing on three key stages: pre-training, instruction tuning, and alignment with human preferences. Our findings demonstrate that continual pre-training with a high-quality Basque corpus of around 600 million words improves natural language understanding (NLU) of the foundational model by over 12 points. Moreover, instruction tuning and human preference alignment using automatically translated datasets proved highly effective, resulting in a 24-point improvement in instruction-following performance. The resulting models, Llama-eus-8B and Llama-eus-8B-instruct, establish a new state-of-the-art for Basque in the sub-10B parameter category.