Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models
作者: Kunat Pipatanakul, Potsawee Manakul, Natapong Nitarach, Warit Sirichotedumrong, Surapon Nonesung, Teetouch Jaknamon, Parinthapat Pengpun, Pittawat Taveekitworachai, Adisai Na-Thalang, Sittipong Sripaisarnmongkol, Krisanapong Jirayoot, Kasima Tharnpipitchai
分类: cs.CL, cs.AI
发布日期: 2024-12-18 (更新: 2024-12-19)
备注: technical report, 55 pages
💡 一句话要点
Typhoon 2:一系列面向泰语的开源文本和多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 泰语大语言模型 多模态学习 持续预训练 指令调优 安全分类器 语音到语音 文档理解
📋 核心要点
- 现有泰语大语言模型在特定任务上表现不足,且缺乏针对泰语文化和语言的安全保障。
- Typhoon 2系列模型通过持续预训练、后训练和安全分类器,提升泰语处理能力和安全性。
- 该系列模型涵盖文本、视觉和音频,并在不同参数规模上提供,满足多样化应用需求。
📝 摘要(中文)
本文介绍了Typhoon 2,一系列针对泰语优化的文本和多模态大型语言模型。该系列包括文本、视觉和音频模型。Typhoon2-Text构建在最先进的开源模型(如Llama 3和Qwen2)之上,并对英语和泰语数据的混合进行持续预训练。我们采用后训练技术来增强泰语语言性能,同时保留基础模型的原始能力。我们发布了从10亿到700亿参数范围内的文本模型,提供基础版本和指令调优版本。为了保护文本生成,我们发布了Typhoon2-Safety,一个针对泰国文化和语言增强的分类器。Typhoon2-Vision改进了泰语文档理解,同时保留了一般的视觉能力,例如图像字幕。Typhoon2-Audio引入了一种端到端的语音到语音模型架构,能够处理音频、语音和文本输入,并生成文本和语音输出。
🔬 方法详解
问题定义:现有的大型语言模型在处理泰语时,性能往往不如英语等主流语言。此外,针对泰语文化和语言特点的安全保障机制也相对缺乏,容易产生不当或有害的输出。因此,需要专门针对泰语进行优化的大语言模型,并确保其安全性。
核心思路:Typhoon 2系列模型的核心思路是,在先进的开源大语言模型(如Llama 3和Qwen2)的基础上,通过持续预训练和后训练等技术,使其更好地适应泰语的特点。同时,引入安全分类器,过滤掉不安全或不适当的输出,从而提高模型的整体性能和安全性。
技术框架:Typhoon 2系列模型包含三个主要部分:Typhoon2-Text、Typhoon2-Vision和Typhoon2-Audio。Typhoon2-Text基于Llama 3和Qwen2等模型,通过持续预训练和后训练进行优化。Typhoon2-Vision专注于泰语文档理解,同时保留通用视觉能力。Typhoon2-Audio是一个端到端的语音到语音模型,可以处理音频、语音和文本输入,并生成文本和语音输出。此外,Typhoon2-Safety是一个安全分类器,用于过滤不安全的文本输出。
关键创新:该论文的关键创新在于,它提供了一整套针对泰语优化的开源大语言模型,涵盖文本、视觉和音频三个方面。此外,Typhoon2-Safety安全分类器的引入,也提高了模型的安全性和可靠性,使其更适合在实际应用中使用。
关键设计:Typhoon2-Text采用了持续预训练的方法,在英语和泰语数据的混合上进行训练,以提高模型对泰语的理解能力。后训练技术用于进一步增强泰语语言性能,同时保留基础模型的原始能力。Typhoon2-Audio采用了端到端的语音到语音模型架构,可以处理多种类型的输入和输出。Typhoon2-Safety分类器针对泰国文化和语言进行了增强,以提高其准确性和有效性。
🖼️ 关键图片

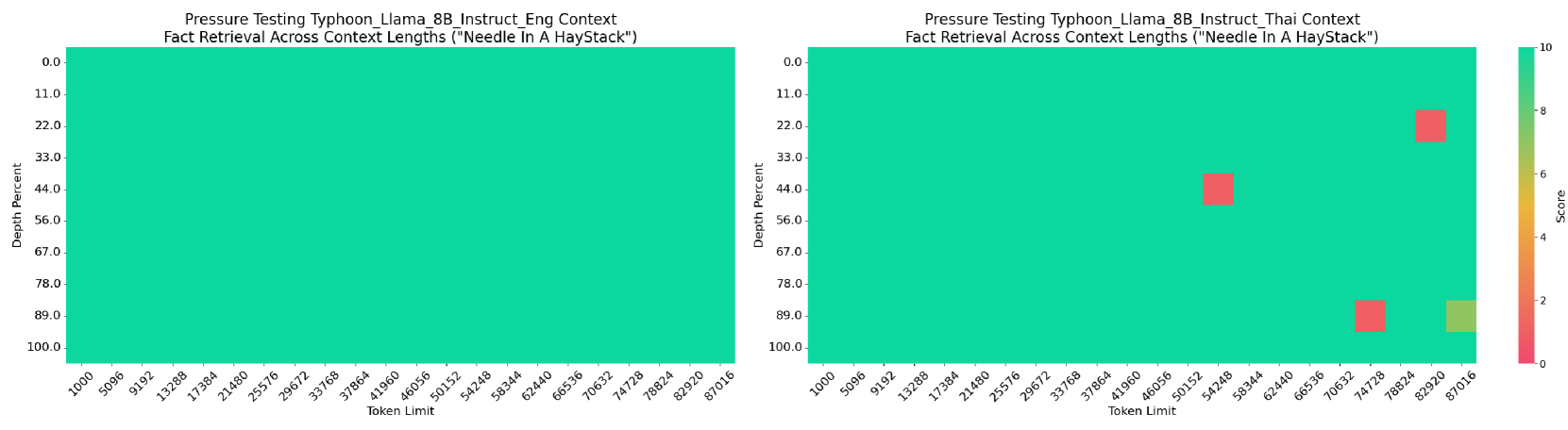

📊 实验亮点
Typhoon 2系列模型在泰语处理任务上取得了显著进展,通过持续预训练和后训练,有效提升了模型在泰语环境下的性能。Typhoon2-Safety安全分类器能够有效过滤不安全的文本输出,保障了模型使用的安全性。该系列模型涵盖文本、视觉和音频,为多模态泰语应用提供了有力支持。
🎯 应用场景
Typhoon 2系列模型可广泛应用于泰语相关的自然语言处理任务,如机器翻译、文本摘要、问答系统、语音识别与合成等。其开源特性和针对泰语的优化,降低了泰语NLP应用开发的门槛,促进了泰语信息技术的发展。同时,安全分类器的引入,使其在内容审核、舆情分析等敏感领域具有应用潜力。
📄 摘要(原文)
This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ post-training techniques to enhance Thai language performance while preserving the base models' original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. To guardrail text generation, we release Typhoon2-Safety, a classifier enhanced for Thai cultures and language. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs.