Towards Efficient and Explainable Hate Speech Detection via Model Distillation
作者: Paloma Piot, Javier Parapar
分类: cs.CL
发布日期: 2024-12-18
期刊: Advances in Information Retrieval. ECIR 2025. Lecture Notes in Computer Science, vol 15573
DOI: 10.1007/978-3-031-88711-6_24
💡 一句话要点
提出基于模型蒸馏的高效且可解释的仇恨言论检测方法,提升性能并降低计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 仇恨言论检测 模型蒸馏 可解释性 大型语言模型 思维链 自然语言处理 知识迁移
📋 核心要点
- 现有仇恨言论检测模型通常是黑盒,缺乏可解释性,难以让用户理解判断依据。
- 利用思维链(Chain-of-Thought)方法,从大型语言模型中提取解释,并将其用于蒸馏小型模型。
- 实验表明,蒸馏模型在提供高质量解释的同时,分类性能优于大型模型,降低了计算成本。
📝 摘要(中文)
自动检测仇恨和辱骂性语言对于打击其在线传播至关重要。识别和解释仇恨言论有助于提高人们对其负面影响的认识。然而,目前大多数检测模型都是黑盒,缺乏可解释性。大型语言模型(LLM)已被证明在仇恨言论检测和提高可解释性方面有效,但计算成本高昂。本文提出通过使用思维链(Chain-of-Thought)提取解释来支持仇恨言论分类任务,从而蒸馏大型语言模型。用于这些任务的小型语言模型将有助于它们在实际环境中的应用。本文证明,蒸馏模型能够提供与大型模型质量相同的解释,同时在分类性能上超过它们。这种分类和解释的双重能力,使仇恨言论检测更经济、更易理解和更具可操作性。
🔬 方法详解
问题定义:现有仇恨言论检测模型缺乏可解释性,难以理解其判断依据,并且大型语言模型虽然性能好,但计算成本高昂,难以部署。因此,需要一种既高效又可解释的仇恨言论检测方法。
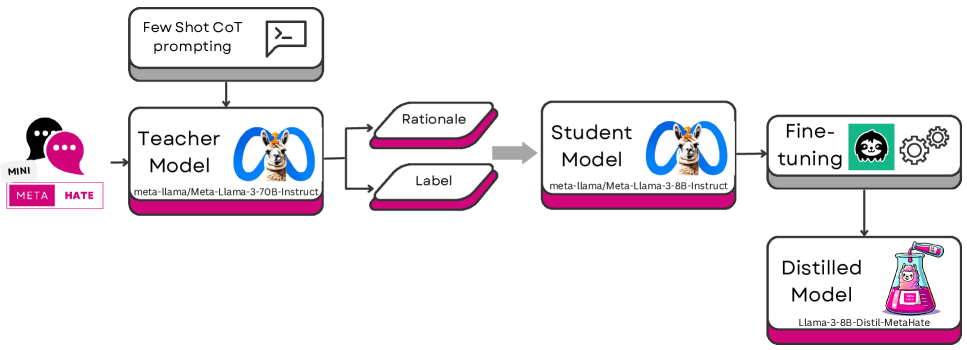
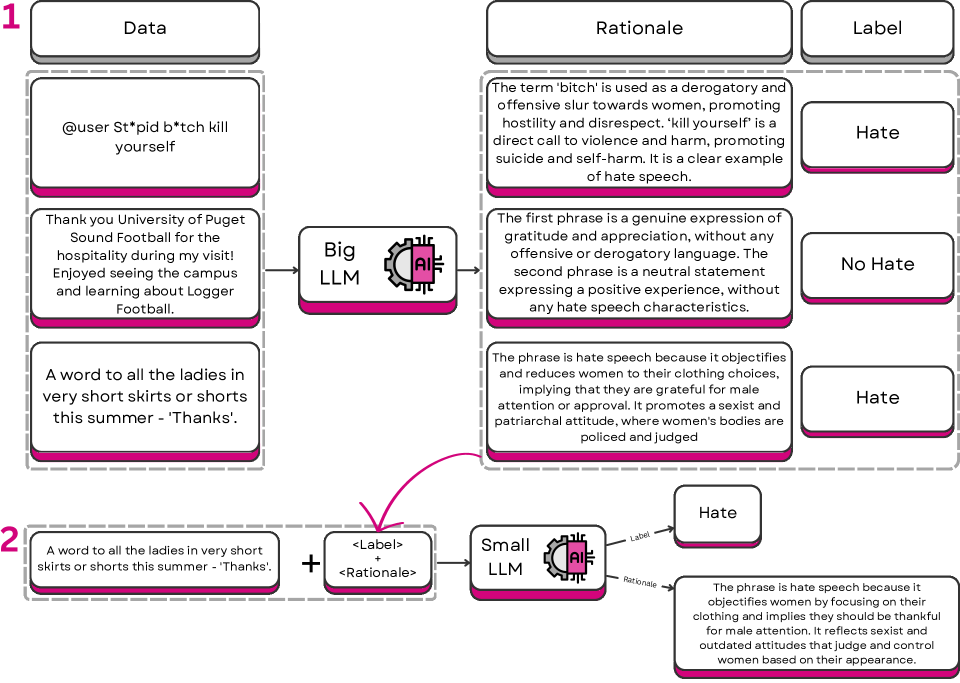
核心思路:利用模型蒸馏技术,将大型语言模型(LLM)的知识迁移到小型语言模型(SLM)。通过思维链(Chain-of-Thought)方法,让LLM生成解释,作为SLM学习的目标,从而使SLM不仅能进行分类,还能提供可解释的理由。
技术框架:该方法主要包含两个阶段:1) 使用大型语言模型生成解释:利用Chain-of-Thought提示LLM对仇恨言论进行分类,并生成相应的解释。2) 蒸馏小型语言模型:使用LLM生成的解释作为监督信号,训练小型语言模型,使其能够同时进行分类和提供解释。
关键创新:该方法的核心创新在于利用Chain-of-Thought和模型蒸馏相结合,在保证分类性能的同时,显著提高了模型的可解释性,并降低了计算成本。与传统的蒸馏方法不同,该方法不仅蒸馏了分类能力,还蒸馏了LLM的推理能力。
关键设计:具体的技术细节包括:选择合适的LLM作为教师模型,设计有效的Chain-of-Thought提示,选择合适的SLM作为学生模型,以及设计合适的损失函数来指导SLM的学习。损失函数可能包括分类损失和解释一致性损失,以确保SLM不仅能正确分类,还能生成与LLM一致的解释。具体的参数设置和网络结构的选择可能需要根据具体的数据集和任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过蒸馏的小型模型在分类性能上超越了大型模型,同时能够提供与大型模型质量相当的解释。这意味着该方法在保证性能的同时,显著降低了计算成本,使其更易于部署和应用。具体的性能提升数据未知,但摘要中明确指出“surpassing them in classification performance”。
🎯 应用场景
该研究成果可应用于各种在线平台,例如社交媒体、论坛和评论区,以自动检测和解释仇恨言论。通过提供可解释的判断依据,可以帮助用户更好地理解仇恨言论的危害,并提高平台的内容审核效率。此外,该方法还可以推广到其他自然语言处理任务中,例如情感分析、文本摘要等。
📄 摘要(原文)
Automatic detection of hate and abusive language is essential to combat its online spread. Moreover, recognising and explaining hate speech serves to educate people about its negative effects. However, most current detection models operate as black boxes, lacking interpretability and explainability. In this context, Large Language Models (LLMs) have proven effective for hate speech detection and to promote interpretability. Nevertheless, they are computationally costly to run. In this work, we propose distilling big language models by using Chain-of-Thought to extract explanations that support the hate speech classification task. Having small language models for these tasks will contribute to their use in operational settings. In this paper, we demonstrate that distilled models deliver explanations of the same quality as larger models while surpassing them in classification performance. This dual capability, classifying and explaining, advances hate speech detection making it more affordable, understandable and actionable.