EvoWiki: Evaluating LLMs on Evolving Knowledge
作者: Wei Tang, Yixin Cao, Yang Deng, Jiahao Ying, Bo Wang, Yizhe Yang, Yuyue Zhao, Qi Zhang, Xuanjing Huang, Yugang Jiang, Yong Liao
分类: cs.CL
发布日期: 2024-12-18
💡 一句话要点
EvoWiki:一个用于评估LLM在演化知识上表现的自动更新数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识演化 自动更新数据集 检索增强生成 持续学习 知识库 评估基准
📋 核心要点
- 现有LLM评估基准缺乏对知识演化的考虑,导致评估结果不准确,且存在数据污染的风险。
- EvoWiki通过将知识分为稳定、演化和未探索状态,并实现自动更新,模拟知识的演化过程。
- 实验表明,现有LLM在处理演化知识时存在困难,而RAG和CL的结合可以有效提升LLM对演化知识的适应能力。
📝 摘要(中文)
本文提出了EvoWiki,一个用于反映知识演化过程的数据集,旨在解决现有基准测试静态化的问题,从而更准确地评估LLM对知识演化的适应能力。EvoWiki将信息分为稳定、演化和未探索三种状态,并具备完全自动更新的能力,可以精确评估LLM在持续变化的知识和新模型上的表现。通过检索增强生成(RAG)和持续学习(CL)的实验,评估了LLM适应演化知识的有效性。结果表明,当前模型在处理演化知识时表现不佳,经常提供过时或不正确的答案。此外,该数据集还突出了RAG和CL之间的协同效应,证明了它们在更好地适应演化知识方面的潜力。EvoWiki为推进未来对大型语言模型知识演化能力的研究提供了一个可靠的基准。
🔬 方法详解
问题定义:现有的大语言模型(LLM)评估基准大多是静态的,无法反映真实世界中知识不断演化的特性。这导致了两个主要问题:一是无法准确评估LLM对新知识的掌握程度和对旧知识的更新能力;二是容易受到数据污染的影响,即模型在训练过程中已经接触到测试数据,从而导致评估结果虚高。因此,如何构建一个能够动态反映知识演化过程的评估基准,并有效评估LLM在演化知识上的表现,是一个亟待解决的问题。
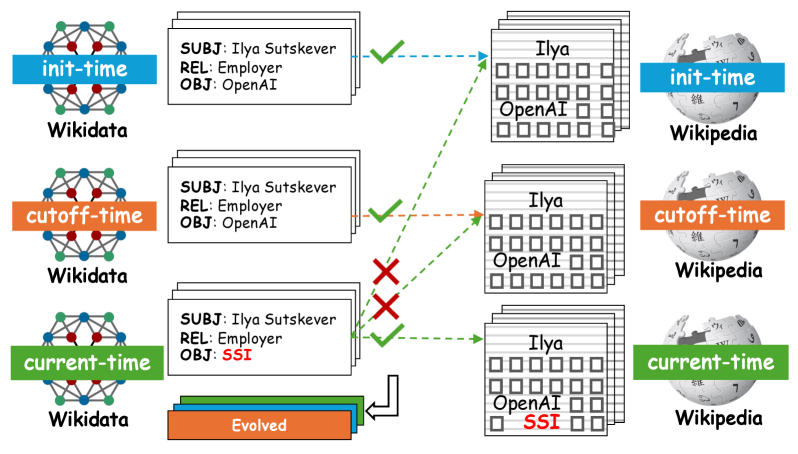
核心思路:EvoWiki的核心思路是构建一个能够自动更新的知识库,并根据知识的演化状态将其分为稳定、演化和未探索三种类型。稳定知识是指长期不变的知识,演化知识是指发生变化的知识,未探索知识是指LLM尚未接触到的新知识。通过这种分类,可以更精确地评估LLM对不同类型知识的处理能力。同时,EvoWiki的自动更新机制保证了知识库的实时性,避免了数据污染的问题。
技术框架:EvoWiki的整体框架主要包括以下几个模块:1) 数据收集模块:负责从Wikipedia等来源收集知识;2) 知识分类模块:根据知识的演化状态将其分为稳定、演化和未探索三种类型;3) 数据更新模块:负责定期更新知识库,保持知识的实时性;4) 评估模块:负责根据知识库生成评估数据集,并评估LLM在演化知识上的表现。在评估过程中,可以使用检索增强生成(RAG)和持续学习(CL)等技术来提升LLM的性能。
关键创新:EvoWiki最重要的创新点在于其自动更新机制和对知识演化状态的分类。传统的评估基准通常是静态的,无法反映知识的演化过程。而EvoWiki通过自动更新机制,可以实时跟踪知识的变化,并根据知识的演化状态进行分类,从而更准确地评估LLM在演化知识上的表现。此外,EvoWiki还强调了RAG和CL在处理演化知识方面的协同效应,为未来的研究提供了新的思路。
关键设计:EvoWiki的关键设计包括:1) 知识分类策略:如何准确地将知识分为稳定、演化和未探索三种类型;2) 数据更新频率:如何选择合适的数据更新频率,以保证知识库的实时性;3) 评估指标:如何设计合适的评估指标,以准确评估LLM在演化知识上的表现。此外,EvoWiki还考虑了如何减少数据污染的影响,例如通过使用时间戳来过滤掉LLM在训练过程中已经接触到的数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的LLM在处理演化知识时表现不佳,经常提供过时或不正确的答案。例如,在处理演化知识的问答任务中,LLM的准确率显著低于处理稳定知识的问答任务。此外,实验还表明,RAG和CL的结合可以有效提升LLM对演化知识的适应能力,例如,通过RAG可以检索到最新的知识,并通过CL可以更新LLM的知识库。
🎯 应用场景
EvoWiki的研究成果可以应用于多个领域。例如,可以用于评估和改进LLM在信息检索、问答系统和对话生成等任务中的性能。此外,EvoWiki还可以用于开发更智能的知识管理系统,帮助用户更好地跟踪和理解知识的演化过程。未来,EvoWiki的研究思路可以推广到其他类型的知识库,例如医学知识库和法律知识库,从而为这些领域的应用提供更可靠的评估基准。
📄 摘要(原文)
Knowledge utilization is a critical aspect of LLMs, and understanding how they adapt to evolving knowledge is essential for their effective deployment. However, existing benchmarks are predominantly static, failing to capture the evolving nature of LLMs and knowledge, leading to inaccuracies and vulnerabilities such as contamination. In this paper, we introduce EvoWiki, an evolving dataset designed to reflect knowledge evolution by categorizing information into stable, evolved, and uncharted states. EvoWiki is fully auto-updatable, enabling precise evaluation of continuously changing knowledge and newly released LLMs. Through experiments with Retrieval-Augmented Generation (RAG) and Contunual Learning (CL), we evaluate how effectively LLMs adapt to evolving knowledge. Our results indicate that current models often struggle with evolved knowledge, frequently providing outdated or incorrect responses. Moreover, the dataset highlights a synergistic effect between RAG and CL, demonstrating their potential to better adapt to evolving knowledge. EvoWiki provides a robust benchmark for advancing future research on the knowledge evolution capabilities of large language models.