Socio-Culturally Aware Evaluation Framework for LLM-Based Content Moderation
作者: Shanu Kumar, Gauri Kholkar, Saish Mendke, Anubhav Sadana, Parag Agrawal, Sandipan Dandapat
分类: cs.CL, cs.AI
发布日期: 2024-12-18
备注: Accepted in SUMEval Workshop in COLING 2025
💡 一句话要点
提出一种社会文化敏感的评估框架,用于评估基于LLM的内容审核能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内容审核 大型语言模型 社会文化意识 评估框架 角色扮演生成 数据集多样性 自然语言处理
📋 核心要点
- 现有内容审核数据集缺乏对不同社会文化群体的充分代表性,导致LLM评估结果存在偏差。
- 提出一种基于角色生成的多样化数据集创建方法,并构建社会文化敏感的内容审核评估框架。
- 实验表明,该框架生成的数据集对LLM提出了更大挑战,尤其是在小型LLM上,验证了框架的有效性。
📝 摘要(中文)
随着社交媒体和大型语言模型的快速发展,内容审核变得至关重要。然而,许多现有的数据集缺乏对不同群体的充分代表性,导致评估结果不可靠。为了解决这个问题,我们提出了一种社会文化敏感的评估框架,用于评估基于LLM的内容审核能力,并引入了一种可扩展的方法,通过基于角色的生成来创建多样化的数据集。我们的分析表明,与没有角色的、仅关注多样性的生成方法相比,这些数据集提供了更广泛的视角,并对LLM提出了更大的挑战。这种挑战在较小的LLM中尤为明显,突出了它们在审核如此多样化内容时遇到的困难。
🔬 方法详解
问题定义:论文旨在解决现有内容审核评估数据集缺乏社会文化多样性的问题。现有数据集无法充分代表不同社会文化群体,导致LLM在内容审核方面的评估结果存在偏差,无法准确反映LLM在真实世界场景中的表现。现有方法的痛点在于无法生成足够多样化和具有挑战性的内容,从而限制了对LLM内容审核能力的全面评估。
核心思路:论文的核心思路是利用基于角色的生成方法,创建更具社会文化多样性的数据集。通过模拟不同背景、信仰和价值观的角色,生成包含各种观点的文本内容,从而构建更具挑战性的内容审核场景。这种方法能够更全面地评估LLM在处理不同社会文化背景下的内容审核能力。
技术框架:该框架主要包含两个阶段:1) 基于角色的数据集生成阶段:利用LLM生成具有不同角色特征的文本内容。这些角色具有不同的社会文化背景、信仰和价值观。2) 内容审核评估阶段:使用生成的数据集评估LLM的内容审核能力。评估指标包括准确率、召回率和F1值等。
关键创新:该论文的关键创新在于提出了基于角色的数据集生成方法,用于创建更具社会文化多样性的内容审核评估数据集。与传统的仅关注多样性的生成方法相比,基于角色的生成方法能够更好地模拟真实世界场景,生成更具挑战性的内容,从而更全面地评估LLM的内容审核能力。
关键设计:在基于角色的数据集生成阶段,需要精心设计角色的属性,例如年龄、性别、种族、宗教信仰、政治立场等。这些属性将影响LLM生成的内容。此外,还需要设计合适的提示语,引导LLM生成符合角色特征的文本内容。在内容审核评估阶段,需要选择合适的评估指标,并对评估结果进行分析,以了解LLM在不同社会文化背景下的表现。
🖼️ 关键图片

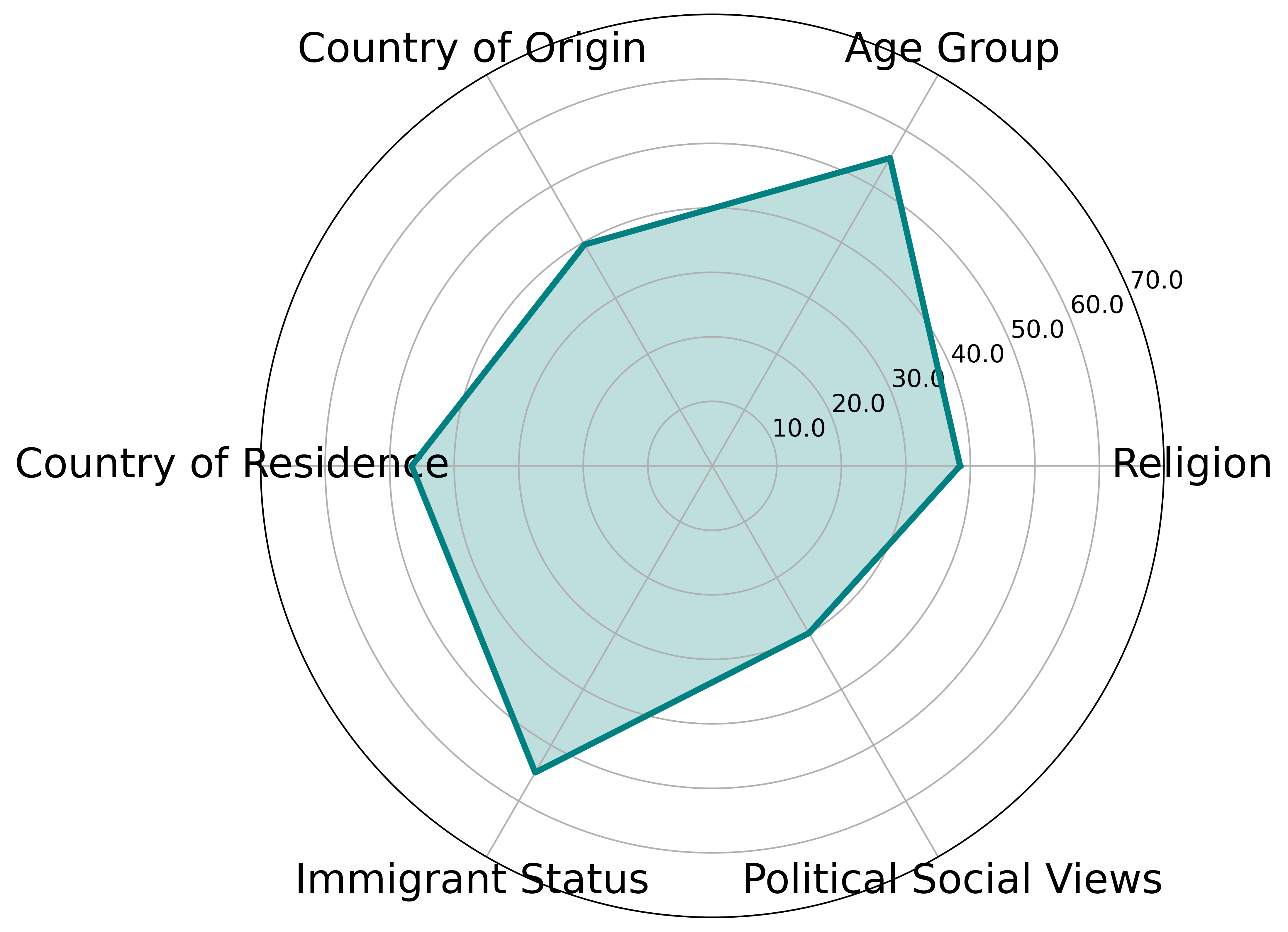
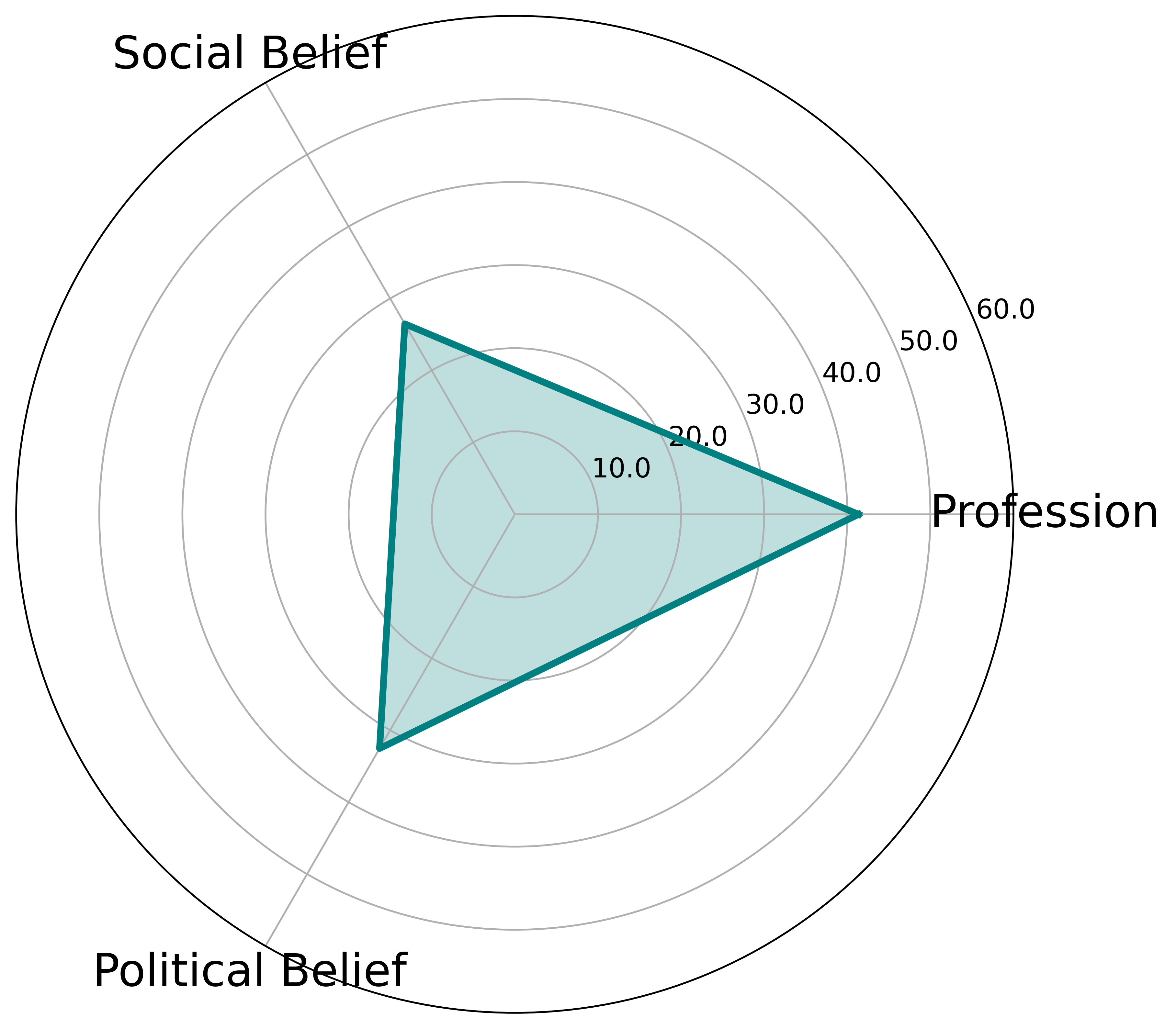
📊 实验亮点
实验结果表明,使用该框架生成的数据集对LLM提出了更大的挑战,尤其是在小型LLM上。与使用传统方法生成的数据集相比,LLM在基于角色生成的数据集上的性能显著下降,表明该框架能够更有效地评估LLM在处理社会文化多样性方面的能力。例如,小型LLM的F1值下降了10%-15%。
🎯 应用场景
该研究成果可应用于社交媒体平台、在线论坛、新闻评论区等场景,帮助提高内容审核的准确性和公平性,减少有害信息的传播。通过更全面地评估LLM的内容审核能力,可以更好地保护用户免受网络欺凌、仇恨言论等不良信息的影响,营造更健康的网络环境。该研究也有助于提升LLM在处理社会文化多样性方面的能力,使其更好地服务于不同背景的用户。
📄 摘要(原文)
With the growth of social media and large language models, content moderation has become crucial. Many existing datasets lack adequate representation of different groups, resulting in unreliable assessments. To tackle this, we propose a socio-culturally aware evaluation framework for LLM-driven content moderation and introduce a scalable method for creating diverse datasets using persona-based generation. Our analysis reveals that these datasets provide broader perspectives and pose greater challenges for LLMs than diversity-focused generation methods without personas. This challenge is especially pronounced in smaller LLMs, emphasizing the difficulties they encounter in moderating such diverse content.