Curriculum Learning for Cross-Lingual Data-to-Text Generation With Noisy Data
作者: Kancharla Aditya Hari, Manish Gupta, Vasudeva Varma
分类: cs.CL
发布日期: 2024-12-18
💡 一句话要点
提出基于课程学习的跨语言数据到文本生成方法,提升噪声数据下的生成质量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 课程学习 跨语言生成 数据到文本生成 噪声数据 对齐得分
📋 核心要点
- 现有数据到文本生成方法在跨语言场景和噪声数据下表现不佳。
- 论文提出基于对齐得分的课程学习方法,并结合退火策略训练模型。
- 实验结果表明,该方法显著提升了跨语言数据到文本生成的质量和效果。
📝 摘要(中文)
本文研究了课程学习在跨语言数据到文本生成(DTG)任务中的应用,旨在提升含噪声数据下的文本生成质量。现有单语DTG的难度评估标准难以直接应用于跨语言场景,且未考虑噪声数据的影响。因此,本文探索了多种适用于跨语言DTG且能有效处理噪声数据的难度评估标准,并结合两种课程学习策略进行模型训练。实验结果表明,使用对齐得分作为排序标准,并采用退火策略进行训练,在两个数据集上的11种印度语言和英语的跨语言生成任务中,BLEU值提升高达4个点,生成文本的忠实度和覆盖率平均提升5-15%。代码和数据已公开。
🔬 方法详解
问题定义:论文旨在解决跨语言数据到文本生成任务中,由于训练数据存在噪声以及跨语言特性带来的难度评估问题,导致生成文本质量下降的问题。现有单语数据到文本生成方法难以直接应用于跨语言场景,并且没有充分考虑噪声数据的影响。
核心思路:论文的核心思路是利用课程学习的思想,根据训练样本的难度进行排序,并按照由易到难的顺序进行训练。通过这种方式,模型可以先学习简单的样本,逐步适应复杂的样本,从而提高生成文本的质量和鲁棒性。同时,论文针对跨语言场景和噪声数据,提出了新的难度评估标准。
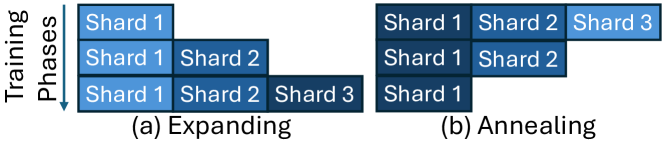
技术框架:整体框架包括数据预处理、难度评估、课程安排和模型训练四个主要阶段。首先,对跨语言数据进行预处理,例如对齐等操作。然后,使用对齐得分等标准评估每个样本的难度。接着,根据难度评估结果,制定课程学习的训练计划,例如使用退火策略。最后,使用排序后的数据训练数据到文本生成模型。
关键创新:论文的关键创新在于提出了适用于跨语言数据到文本生成的难度评估标准,例如基于对齐得分的标准。与传统的单语难度评估标准相比,该标准能够更好地反映跨语言数据的特点。此外,论文还探索了不同的课程学习策略,例如退火策略,以提高模型的训练效果。
关键设计:论文使用对齐得分作为排序标准,具体而言,计算源语言数据和目标语言文本之间的对齐得分,得分越高表示样本越简单。在课程安排方面,采用了退火策略,即在训练初期使用较多的简单样本,随着训练的进行,逐渐增加复杂样本的比例。模型方面,可以使用常见的序列到序列模型,例如Transformer。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用对齐得分作为排序标准,并采用退火策略进行训练,在两个数据集上的11种印度语言和英语的跨语言生成任务中,BLEU值提升高达4个点,生成文本的忠实度和覆盖率平均提升5-15%。这些结果表明,该方法能够显著提升跨语言数据到文本生成的质量和效果。
🎯 应用场景
该研究成果可应用于跨语言信息生成、机器翻译、多语言对话系统等领域。通过提升跨语言数据到文本生成的质量,可以更好地支持多语言环境下的信息交流和知识共享,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Curriculum learning has been used to improve the quality of text generation systems by ordering the training samples according to a particular schedule in various tasks. In the context of data-to-text generation (DTG), previous studies used various difficulty criteria to order the training samples for monolingual DTG. These criteria, however, do not generalize to the crosslingual variant of the problem and do not account for noisy data. We explore multiple criteria that can be used for improving the performance of cross-lingual DTG systems with noisy data using two curriculum schedules. Using the alignment score criterion for ordering samples and an annealing schedule to train the model, we show increase in BLEU score by up to 4 points, and improvements in faithfulness and coverage of generations by 5-15% on average across 11 Indian languages and English in 2 separate datasets. We make code and data publicly available