A Statistical and Multi-Perspective Revisiting of the Membership Inference Attack in Large Language Models
作者: Bowen Chen, Namgi Han, Yusuke Miyao
分类: cs.CL, cs.AI
发布日期: 2024-12-18
备注: main content 8 pages, 6 figures
💡 一句话要点
针对大型语言模型成员推断攻击,提出一种统计和多视角分析方法,揭示其性能不一致性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 大型语言模型 隐私风险 统计分析 多视角分析
📋 核心要点
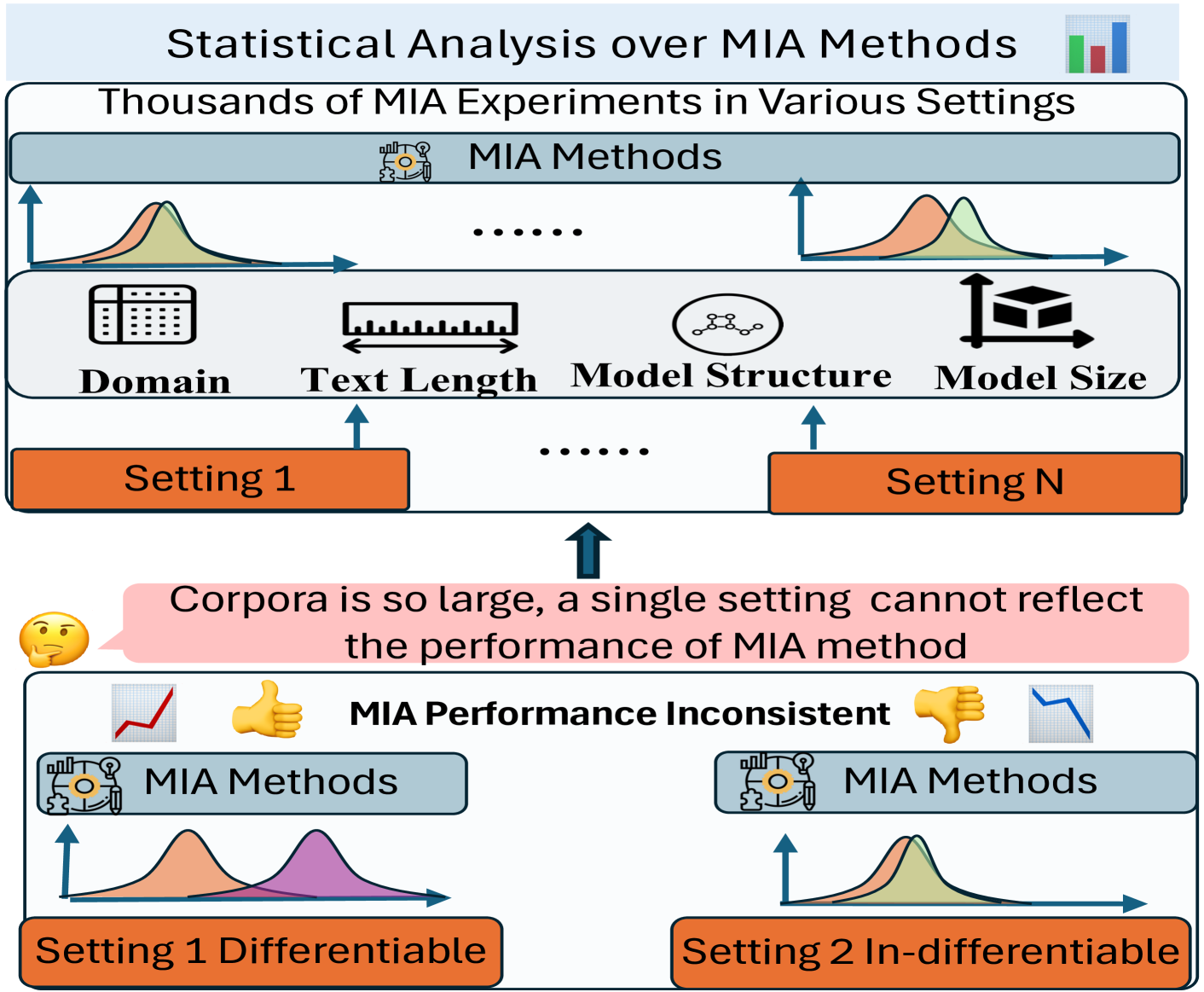
- 现有成员推断攻击(MIA)在不同LLM设置下性能不稳定,缺乏对语料库分布的考虑。
- 通过统计分析和多视角研究,探索不同设置下MIA的性能差异,并分析文本特征、嵌入和解码动态。
- 实验表明MIA性能受模型大小和领域影响,且阈值选择至关重要,文本差异性和长文本有利于MIA。
📝 摘要(中文)
大型语言模型(LLM)缺乏数据透明性,使得成员推断攻击(MIA)变得重要,它可以区分训练数据(成员)和未训练数据(非成员)。虽然之前的研究表明MIA取得了一定的成功,但最近的研究报告称,在不同的设置下,MIA的性能接近随机,这突出了显著的性能不一致性。我们认为,单一设置无法代表庞大语料库的分布,导致采样到的成员和非成员具有不同的分布,从而导致不一致。在本研究中,我们没有采用单一设置,而是从各种设置中对MIA方法进行了统计性的重新审视,对每种MIA方法进行了数千次实验,并研究了成员和非成员的文本特征、嵌入、阈值决策和解码动态。我们发现:(1)MIA性能随着模型大小的增加而提高,并随领域而变化,但大多数方法在统计上并未优于基线;(2)虽然MIA性能普遍较低,但存在大量可区分的成员和非成员异常值,并且这些异常值因MIA方法而异;(3)确定区分成员和非成员的阈值是一个被忽视的挑战;(4)文本差异性和长文本有利于MIA性能;(5)是否可区分反映在LLM嵌入中;(6)成员和非成员表现出不同的解码动态。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中成员推断攻击(MIA)性能不一致的问题。现有的MIA方法在不同的数据集和模型设置下表现出显著的性能差异,这使得评估LLM的隐私风险变得困难。现有的方法通常只关注单一的设置,忽略了大型语料库的复杂分布,导致评估结果的偏差。
核心思路:论文的核心思路是通过对多种设置下的MIA方法进行大规模的统计分析,从而更全面地评估LLM的隐私风险。通过分析成员和非成员在文本特征、嵌入空间和解码动态上的差异,揭示影响MIA性能的关键因素。这种多视角的分析方法旨在克服单一设置的局限性,提供更可靠的隐私评估结果。
技术框架:论文采用的框架主要包括以下几个阶段:1) 数据集构建:从不同的领域和来源收集大量文本数据,用于训练和评估LLM。2) 模型训练:使用不同的LLM架构和训练策略,训练多个LLM模型。3) MIA攻击:应用多种现有的MIA方法,对训练好的LLM进行攻击,尝试区分成员和非成员数据。4) 统计分析:对MIA攻击的结果进行统计分析,评估不同设置下的MIA性能,并识别影响MIA性能的关键因素。5) 多视角分析:从文本特征、嵌入空间和解码动态等多个角度,分析成员和非成员数据的差异。
关键创新:论文的关键创新在于其统计性和多视角分析方法。传统的MIA研究通常只关注单一的设置,而该论文通过对多种设置进行大规模的实验,从而更全面地评估LLM的隐私风险。此外,论文还从文本特征、嵌入空间和解码动态等多个角度分析成员和非成员数据的差异,从而更深入地理解MIA的原理。
关键设计:论文的关键设计包括:1) 多样化的数据集:为了模拟真实世界的场景,论文使用了来自不同领域和来源的文本数据。2) 多种MIA方法:论文应用了多种现有的MIA方法,以评估不同方法的性能。3) 统计分析:论文使用了统计学方法,对MIA攻击的结果进行分析,例如计算平均性能、标准差和置信区间。4) 多视角分析:论文从文本特征(例如文本长度、词汇多样性)、嵌入空间(例如余弦相似度)和解码动态(例如生成概率)等多个角度分析成员和非成员数据的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MIA性能与模型大小和领域相关,但多数方法在统计上并未显著优于基线。尽管MIA性能整体较低,但存在可区分的成员和非成员异常值。文本差异性和长文本有利于MIA性能。研究还发现成员和非成员在LLM嵌入和解码动态上存在差异。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的隐私保护能力。通过识别易受MIA攻击的场景和特征,可以设计更有效的防御机制,例如差分隐私训练、对抗训练等,从而降低LLM泄露用户隐私的风险。此外,该研究还可以帮助开发者选择更安全的模型架构和训练策略。
📄 摘要(原文)
The lack of data transparency in Large Language Models (LLMs) has highlighted the importance of Membership Inference Attack (MIA), which differentiates trained (member) and untrained (non-member) data. Though it shows success in previous studies, recent research reported a near-random performance in different settings, highlighting a significant performance inconsistency. We assume that a single setting doesn't represent the distribution of the vast corpora, causing members and non-members with different distributions to be sampled and causing inconsistency. In this study, instead of a single setting, we statistically revisit MIA methods from various settings with thousands of experiments for each MIA method, along with study in text feature, embedding, threshold decision, and decoding dynamics of members and non-members. We found that (1) MIA performance improves with model size and varies with domains, while most methods do not statistically outperform baselines, (2) Though MIA performance is generally low, a notable amount of differentiable member and non-member outliers exists and vary across MIA methods, (3) Deciding a threshold to separate members and non-members is an overlooked challenge, (4) Text dissimilarity and long text benefit MIA performance, (5) Differentiable or not is reflected in the LLM embedding, (6) Member and non-members show different decoding dynamics.