Lightweight Safety Classification Using Pruned Language Models
作者: Mason Sawtell, Tula Masterman, Sandi Besen, Jim Brown
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-18
💡 一句话要点
提出层增强分类(LEC),利用剪枝语言模型实现轻量级安全内容分类与提示注入检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内容安全 提示注入检测 轻量级分类 语言模型剪枝 特征提取
📋 核心要点
- 现有内容安全和提示注入检测方法计算成本高昂,且通常需要针对特定任务进行微调,泛化能力有限。
- 论文提出层增强分类(LEC)方法,利用LLM中间层的隐藏状态训练轻量级分类器,实现高效且通用的安全分类。
- 实验表明,LEC方法在内容安全和提示注入检测任务上超越了GPT-4o和专用模型,且仅需少量高质量样本即可训练。
📝 摘要(中文)
本文提出了一种针对大型语言模型的内容安全和提示注入分类的新技术,称为层增强分类(LEC)。LEC通过在LLM的最佳中间Transformer层的隐藏状态上训练惩罚逻辑回归(PLR)分类器来实现。该方法结合了精简PLR分类器的计算效率和LLM的复杂语言理解能力,实现了超越GPT-4o和针对每个任务微调的专用模型的卓越性能。研究发现,小型通用模型(Qwen 2.5的0.5B、1.5B和3B版本)以及其他基于Transformer的架构(如DeBERTa v3)是强大的特征提取器,允许简单的分类器在少于100个高质量示例上进行有效训练。重要的是,这些模型的中间Transformer层通常优于最终层。结果表明,单个通用LLM可用于分类内容安全、检测提示注入并同时生成输出token。或者,这些相对较小的LLM可以被剪枝到最佳中间层,并专门用作强大的特征提取器。由于结果在不同的Transformer架构上是一致的,因此推断出强大的特征提取是大多数(如果不是全部)LLM的固有能力。
🔬 方法详解
问题定义:当前大型语言模型(LLM)的内容安全和提示注入检测通常依赖于计算密集型的方法,例如微调大型模型或使用复杂的规则引擎。这些方法成本高昂,并且可能无法很好地泛化到新的攻击或内容类型。因此,需要一种轻量级、高效且通用的方法来解决这些问题。
核心思路:论文的核心思路是利用LLM中间层的隐藏状态作为特征提取器,然后训练一个简单的分类器(惩罚逻辑回归,PLR)来执行内容安全和提示注入检测。作者认为,LLM的中间层已经学习了丰富的语言表示,这些表示足以用于区分安全和不安全的内容,而无需使用整个模型。
技术框架:LEC方法包含以下主要步骤:1) 选择一个预训练的LLM(例如Qwen或DeBERTa v3)。2) 使用少量高质量的训练数据(少于100个样本)来训练PLR分类器。训练数据包括安全内容和不安全内容(例如提示注入攻击)。3) 对于每个训练样本,将样本输入到LLM中,并提取指定中间Transformer层的隐藏状态。4) 使用提取的隐藏状态作为特征,训练PLR分类器。5) 在推理时,将输入文本输入到LLM中,提取中间层的隐藏状态,并使用训练好的PLR分类器进行分类。
关键创新:LEC方法的关键创新在于:1) 利用LLM的中间层作为特征提取器,而不是使用整个模型。这大大降低了计算成本。2) 使用简单的PLR分类器,进一步提高了效率。3) 发现中间层通常优于最终层,这表明LLM的中间层已经学习了足够用于安全分类的表示。4) 证明该方法可以推广到不同的Transformer架构,表明强大的特征提取是LLM的固有能力。
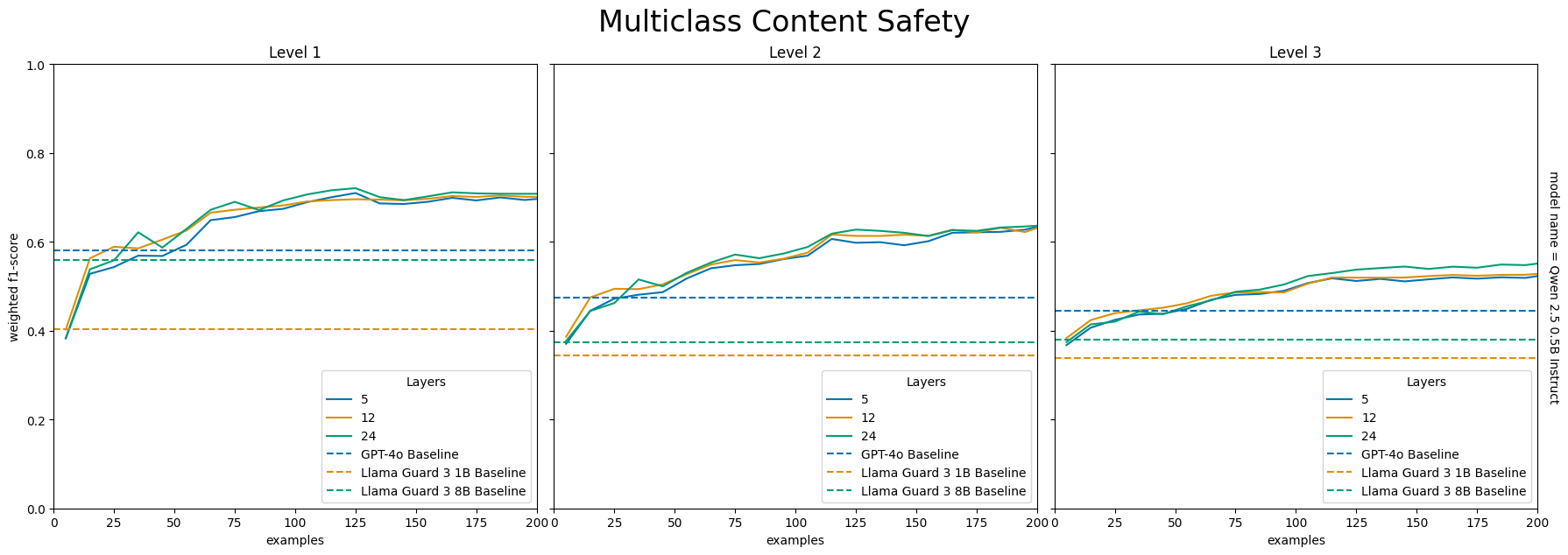
关键设计:论文的关键设计包括:1) 选择合适的中间Transformer层。作者通过实验发现,不同的层在不同的任务上表现不同,因此需要选择最佳的中间层。2) 使用惩罚逻辑回归(PLR)作为分类器。PLR可以防止过拟合,并且具有良好的泛化能力。3) 使用少量高质量的训练数据。作者发现,即使只有少于100个样本,该方法也能取得良好的效果。4) 对LLM进行剪枝,只保留到最佳中间层,进一步降低计算成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LEC方法在内容安全和提示注入检测任务上优于GPT-4o和专用模型。例如,使用Qwen 2.5 (0.5B) 作为特征提取器,LEC方法在提示注入检测任务上取得了显著的性能提升。此外,该方法仅需少量高质量样本即可训练,降低了训练成本。
🎯 应用场景
该研究成果可广泛应用于各种需要内容安全和提示注入检测的场景,例如在线社交平台、聊天机器人、内容生成工具等。通过使用轻量级的LEC方法,可以有效地过滤有害内容,保护用户免受恶意攻击,并提高LLM应用的安全性。
📄 摘要(原文)
In this paper, we introduce a novel technique for content safety and prompt injection classification for Large Language Models. Our technique, Layer Enhanced Classification (LEC), trains a Penalized Logistic Regression (PLR) classifier on the hidden state of an LLM's optimal intermediate transformer layer. By combining the computational efficiency of a streamlined PLR classifier with the sophisticated language understanding of an LLM, our approach delivers superior performance surpassing GPT-4o and special-purpose models fine-tuned for each task. We find that small general-purpose models (Qwen 2.5 sizes 0.5B, 1.5B, and 3B) and other transformer-based architectures like DeBERTa v3 are robust feature extractors allowing simple classifiers to be effectively trained on fewer than 100 high-quality examples. Importantly, the intermediate transformer layers of these models typically outperform the final layer across both classification tasks. Our results indicate that a single general-purpose LLM can be used to classify content safety, detect prompt injections, and simultaneously generate output tokens. Alternatively, these relatively small LLMs can be pruned to the optimal intermediate layer and used exclusively as robust feature extractors. Since our results are consistent on different transformer architectures, we infer that robust feature extraction is an inherent capability of most, if not all, LLMs.