AI PERSONA: Towards Life-long Personalization of LLMs
作者: Tiannan Wang, Meiling Tao, Ruoyu Fang, Huilin Wang, Shuai Wang, Yuchen Eleanor Jiang, Wangchunshu Zhou
分类: cs.CL, cs.AI
发布日期: 2024-12-17
备注: Work in progress
💡 一句话要点
提出AI Persona框架,实现大语言模型(LLM)的终身个性化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 个性化 终身学习 AI Persona 用户画像 语言代理 基准测试
📋 核心要点
- 现有LLM主要关注通用能力提升,忽略了用户个性化需求,无法提供持续适应用户变化信息的个性化服务。
- 提出AI Persona框架,旨在使LLM能够终身学习并适应每个用户的独特偏好和实时变化,提供个性化协助。
- 论文提供了合成真实基准和评估指标的方法,并开源代码和数据,以促进LLM个性化方向的未来研究。
📝 摘要(中文)
本文提出了大语言模型终身个性化这一任务。当前LLM领域的研究主要集中于通过扩展数据和计算资源来提升LLM的能力,但我们认为,使LLM系统或语言代理能够持续适应每个用户的多样化和不断变化的个人资料,并提供最新的个性化帮助同样重要。我们明确地定义了该任务,并提出了一个简单、通用、有效且可扩展的框架,用于LLM系统和语言代理的终身个性化。为了促进未来对LLM个性化的研究,我们还介绍了合成真实基准和稳健评估指标的方法。我们将发布所有代码和数据,用于构建和评估终身个性化的LLM系统。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在个性化方面存在不足。虽然LLM在通用任务上表现出色,但它们难以持续适应每个用户的独特偏好和不断变化的信息。这导致LLM无法提供真正个性化的服务,尤其是在用户长期使用过程中,LLM无法记住用户的历史偏好和实时需求。
核心思路:本文的核心思路是构建一个能够代表用户个性化信息的“AI Persona”,并利用这个Persona来指导LLM的行为。通过不断更新和完善这个Persona,LLM可以持续学习用户的偏好,从而提供更准确、更个性化的服务。这种方法旨在使LLM能够像一个了解用户的助手一样工作。
技术框架:该框架包含以下主要模块:1) 用户信息收集模块,用于收集用户的历史交互数据和实时信息;2) AI Persona构建模块,用于根据收集到的用户信息构建用户的个性化画像;3) LLM个性化模块,利用AI Persona来指导LLM的生成过程,使其输出更符合用户的偏好;4) 评估模块,用于评估个性化效果。整体流程是,首先收集用户信息,然后构建AI Persona,接着利用Persona来个性化LLM,最后进行评估。
关键创新:该方法最重要的创新点在于提出了“AI Persona”的概念,并将其作为LLM个性化的核心。与以往直接微调LLM的方法不同,该方法通过构建一个独立的Persona来表示用户的个性化信息,从而避免了对LLM的过度修改,并提高了模型的泛化能力。此外,该方法还提供了一种可扩展的框架,可以方便地集成不同的用户信息和个性化策略。
关键设计:AI Persona的具体实现方式未知,论文中可能使用了某种向量表示或知识图谱来存储用户的个性化信息。损失函数的设计可能包括个性化损失和通用损失,以平衡个性化效果和通用能力。具体的网络结构也未知,但可以推测使用了某种注意力机制来将AI Persona的信息融入到LLM的生成过程中。
🖼️ 关键图片

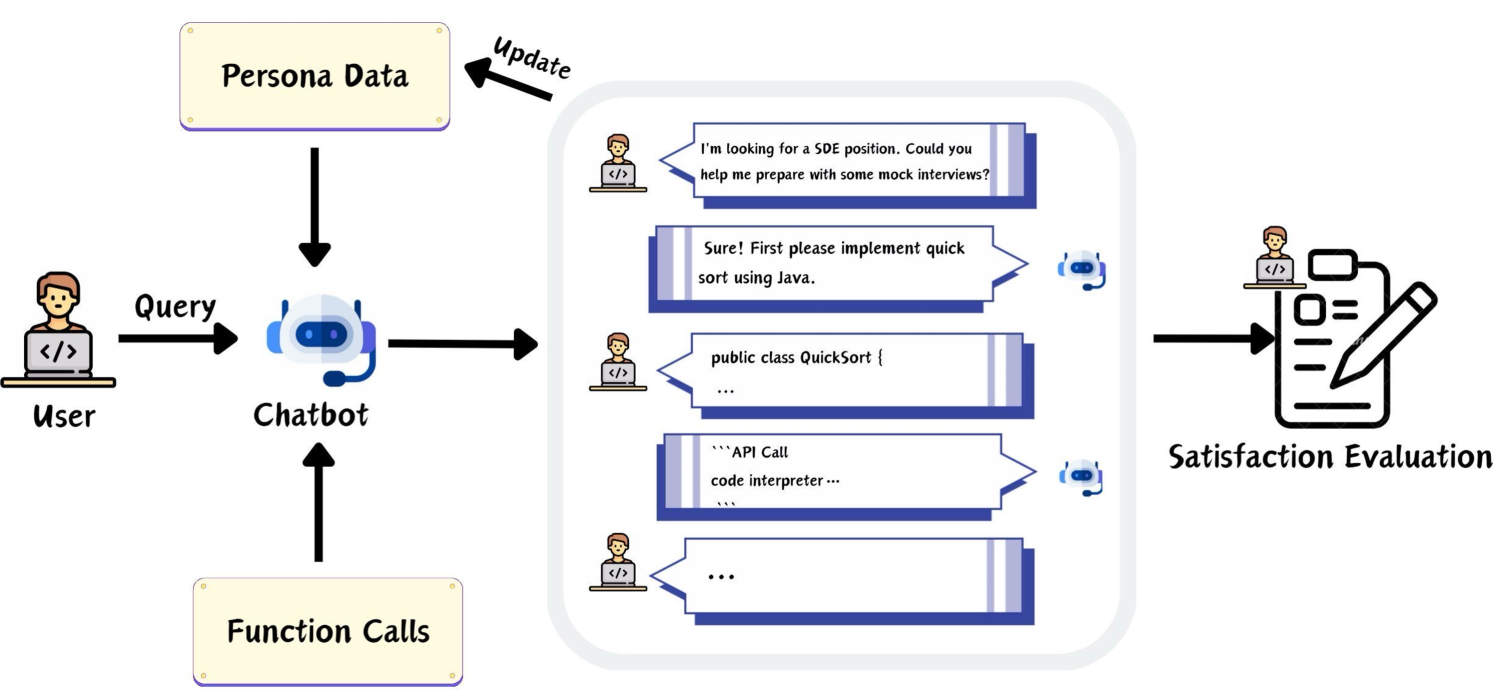
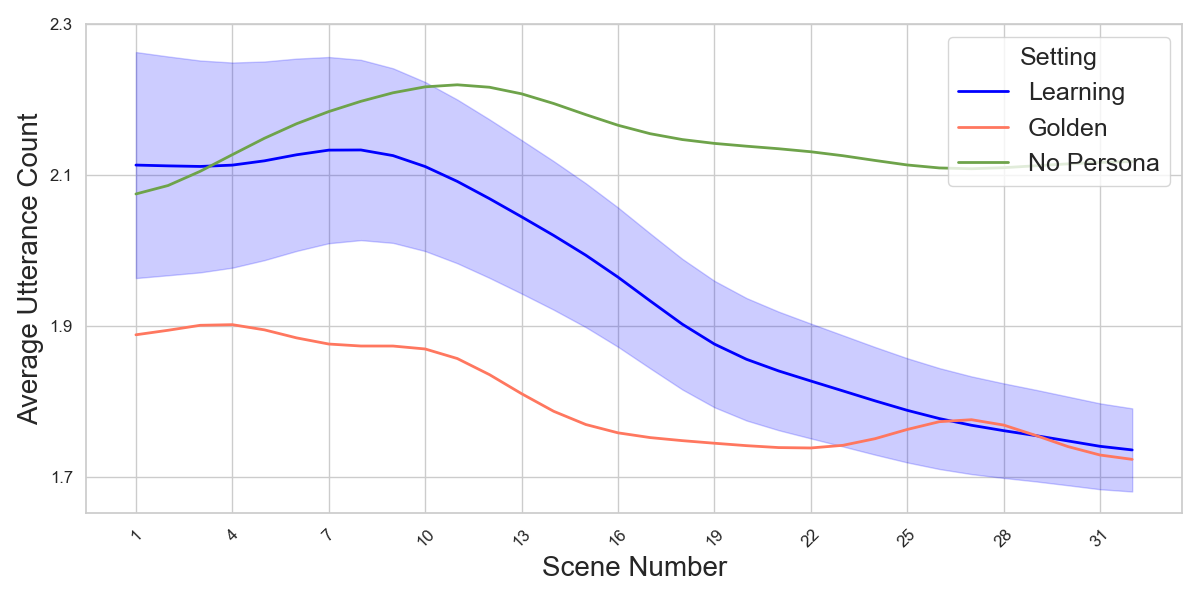
📊 实验亮点
论文提出了一个简单、通用、有效且可扩展的框架,用于LLM系统和语言代理的终身个性化。为了促进未来对LLM个性化的研究,论文还介绍了合成真实基准和稳健评估指标的方法。具体的性能数据和对比基线未知,但论文强调了该框架的有效性和可扩展性。
🎯 应用场景
该研究成果可广泛应用于智能助手、个性化推荐、教育辅导、医疗咨询等领域。通过构建用户的AI Persona,LLM可以提供更加贴合用户需求的个性化服务,提升用户体验和工作效率。未来,该技术有望实现真正意义上的“千人千面”的AI服务,为每个人提供定制化的智能解决方案。
📄 摘要(原文)
In this work, we introduce the task of life-long personalization of large language models. While recent mainstream efforts in the LLM community mainly focus on scaling data and compute for improved capabilities of LLMs, we argue that it is also very important to enable LLM systems, or language agents, to continuously adapt to the diverse and ever-changing profiles of every distinct user and provide up-to-date personalized assistance. We provide a clear task formulation and introduce a simple, general, effective, and scalable framework for life-long personalization of LLM systems and language agents. To facilitate future research on LLM personalization, we also introduce methods to synthesize realistic benchmarks and robust evaluation metrics. We will release all codes and data for building and benchmarking life-long personalized LLM systems.