NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
作者: Karan Wanchoo, Xiaoye Zuo, Hannah Gonzalez, Soham Dan, Georgios Georgakis, Dan Roth, Kostas Daniilidis, Eleni Miltsakaki
分类: cs.CL, cs.CV
发布日期: 2024-12-17 (更新: 2024-12-18)
💡 一句话要点
提出NAVCON:一个认知启发且语言对齐的视觉语言导航语料库
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 认知启发 导航概念 语料库构建 指令理解
📋 核心要点
- 现有VLN数据集缺乏对导航概念的明确标注,阻碍了模型对指令深层语义的理解。
- NAVCON通过引入四个认知驱动的导航概念,并自动标注大规模语料,弥补了这一不足。
- 实验表明,NAVCON的标注质量高,且能有效提升模型在导航概念检测任务上的性能。
📝 摘要(中文)
本文提出了NAVCON,一个大规模的、带有标注的视觉语言导航(VLN)语料库,构建于两个流行的数据集(R2R和RxR)之上。论文引入了四个核心的、认知驱动且语言对齐的导航概念,并提出了一种算法,用于生成大规模的、银标签标注,这些标注对应于导航指令中自然出现的这些概念的语言表达。我们将标注的指令与智能体执行这些指令时的视频片段配对。NAVCON包含约30,000条指令的236,316个概念标注,以及约19,000条指令的270万张对齐图像,展示了智能体执行指令时所看到的内容。据我们所知,这是第一个全面的导航概念资源。我们通过对NAVCON样本进行人工评估研究来评估银标签标注的质量。作为对资源质量和实用性的进一步验证,我们训练了一个模型来检测未见指令中的导航概念及其语言表达。此外,我们展示了使用NAVCON的大规模银标签标注,GPT-4o在小样本学习方面表现良好。
🔬 方法详解
问题定义:现有的视觉语言导航(VLN)数据集,如R2R和RxR,虽然规模较大,但缺乏对导航指令中关键概念的明确标注。这使得模型难以学习指令中蕴含的深层语义信息,例如“左转”、“直走”等动作的精确含义,以及它们与视觉环境之间的关系。因此,如何有效地标注和利用这些导航概念,是提升VLN模型性能的关键挑战。
核心思路:本文的核心思路是,基于认知科学的理论,定义一组核心的导航概念,并设计算法自动标注大规模的VLN数据集。通过将指令分解为这些基本概念的组合,模型可以更好地理解指令的含义,并将其与视觉环境联系起来。这种方法借鉴了人类认知过程,旨在提高模型的泛化能力和鲁棒性。
技术框架:NAVCON的构建流程主要包括以下几个步骤:1) 定义四个核心导航概念;2) 设计算法自动标注R2R和RxR数据集;3) 将标注的指令与智能体执行指令时的视频片段配对,构建NAVCON语料库;4) 进行人工评估,验证标注质量;5) 训练模型,验证NAVCON的有效性。其中,自动标注算法是关键,它需要能够准确地识别指令中出现的导航概念,并将其与相应的语言表达联系起来。
关键创新:NAVCON的主要创新在于:1) 首次提出了四个核心的、认知驱动的导航概念,为VLN研究提供了一个新的视角;2) 设计了一种高效的自动标注算法,能够在大规模数据集上生成高质量的银标签标注;3) 构建了一个包含大量标注和视频片段的NAVCON语料库,为VLN研究提供了一个宝贵的资源。与现有方法相比,NAVCON更加注重对指令深层语义的理解,而不是简单地进行序列到序列的映射。
关键设计:关于自动标注算法的技术细节,论文中提到使用了某种算法来生成大规模的银标签标注,但具体算法细节未知。关于模型训练,论文提到训练了一个模型来检测未见指令中的导航概念及其语言表达,但具体的网络结构、损失函数等细节未知。论文还提到使用GPT-4o进行小样本学习,但具体prompt设计和训练策略未知。
🖼️ 关键图片

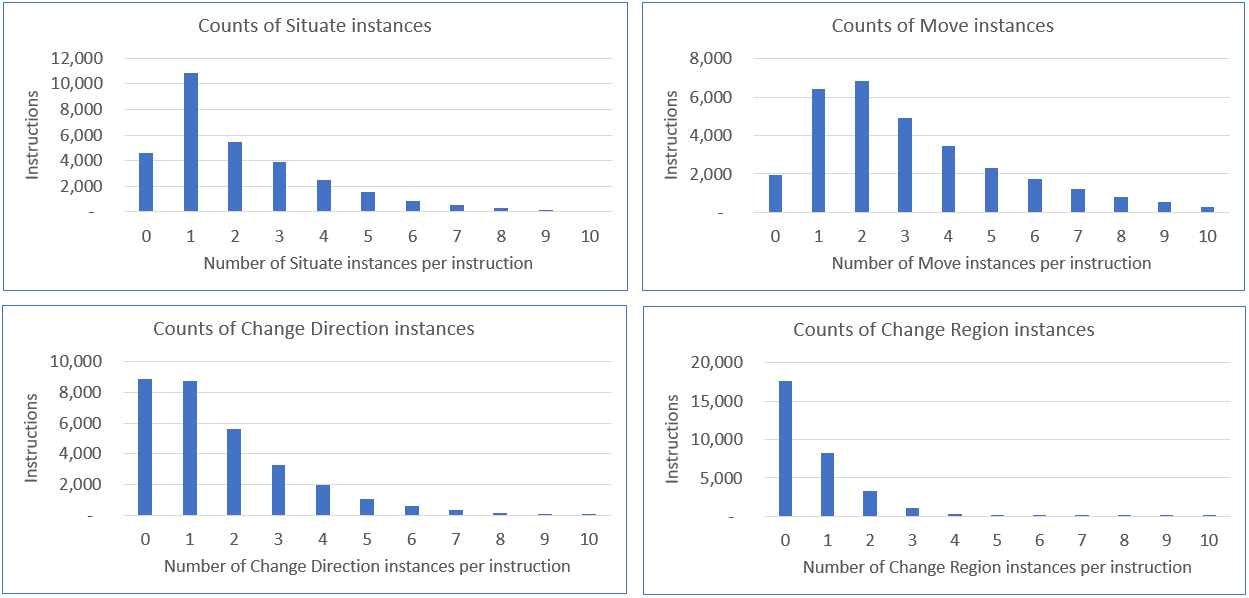

📊 实验亮点
论文通过人工评估验证了NAVCON标注的质量,结果表明标注准确率较高。此外,论文还训练了一个模型来检测未见指令中的导航概念,结果表明该模型在NAVCON数据集上取得了良好的性能。更重要的是,论文展示了GPT-4o在NAVCON数据集上进行小样本学习的潜力,验证了NAVCON的有效性和实用性。
🎯 应用场景
NAVCON语料库可以广泛应用于机器人导航、自动驾驶、虚拟现实等领域。通过训练模型理解导航指令中的关键概念,可以提升机器人在复杂环境中的导航能力,实现更自然、更智能的人机交互。此外,NAVCON还可以用于研究人类认知过程,例如人类如何理解和执行导航指令。
📄 摘要(原文)
We present NAVCON, a large-scale annotated Vision-Language Navigation (VLN) corpus built on top of two popular datasets (R2R and RxR). The paper introduces four core, cognitively motivated and linguistically grounded, navigation concepts and an algorithm for generating large-scale silver annotations of naturally occurring linguistic realizations of these concepts in navigation instructions. We pair the annotated instructions with video clips of an agent acting on these instructions. NAVCON contains 236, 316 concept annotations for approximately 30, 0000 instructions and 2.7 million aligned images (from approximately 19, 000 instructions) showing what the agent sees when executing an instruction. To our knowledge, this is the first comprehensive resource of navigation concepts. We evaluated the quality of the silver annotations by conducting human evaluation studies on NAVCON samples. As further validation of the quality and usefulness of the resource, we trained a model for detecting navigation concepts and their linguistic realizations in unseen instructions. Additionally, we show that few-shot learning with GPT-4o performs well on this task using large-scale silver annotations of NAVCON.