Question: How do Large Language Models perform on the Question Answering tasks? Answer:
作者: Kevin Fischer, Darren Fürst, Sebastian Steindl, Jakob Lindner, Ulrich Schäfer
分类: cs.CL
发布日期: 2024-12-17
备注: Accepted at SAI Computing Conference 2025
💡 一句话要点
对比研究:大型语言模型在问答任务中的表现及单次推理提示优化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 问答系统 单次推理 提示工程 SQuAD2 领域泛化 计算效率
📋 核心要点
- 现有问答系统在处理包含无法回答问题的数据集时,通常采用双重推理方法,计算成本较高。
- 论文提出一种新的提示风格,旨在通过单次推理实现与双重推理相当的性能,从而降低计算资源消耗。
- 实验结果表明,小型微调模型在特定任务上表现优异,而大型语言模型在跨领域泛化能力上更具优势。
📝 摘要(中文)
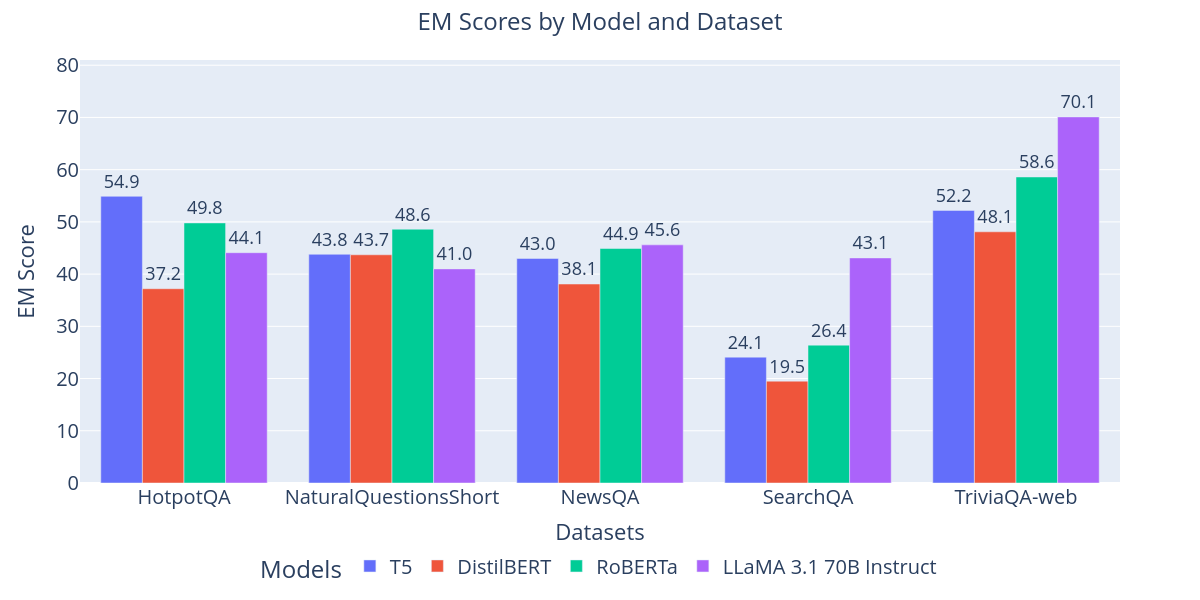
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中展现出良好的性能,无需显式训练,仅通过少量样本或零样本提示技术即可。问答(QA)是常见的NLP任务。本研究对小型微调模型和开箱即用的指令跟随LLM在Stanford Question Answering Dataset 2.0 (SQuAD2)上的性能进行了全面比较,特别是在使用单次推理提示技术时。由于该数据集包含无法回答的问题,之前的工作使用了双重推理方法。我们提出了一种提示风格,旨在无需双重推理即可获得相同能力,从而节省计算时间和资源。此外,我们通过比较它们在相似但不同的QA数据集上的性能来研究它们的泛化能力,无需对任何模型进行微调,模拟真实世界的用例,其中上下文和问题可能与原始训练分布不同,例如将维基百科替换为新闻文章。结果表明,较小的微调模型在微调任务上优于当前最先进的(SOTA) LLM,但最近的SOTA模型能够缩小这种差距,并在5个测试的QA数据集中有3个上优于微调模型。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在问答(QA)任务中的表现,并解决现有方法在处理包含无法回答问题的数据集时计算成本高的问题。现有方法通常采用双重推理,即先判断问题是否可回答,再进行答案抽取,这增加了计算负担。
核心思路:论文的核心思路是设计一种新的提示风格,使得LLM能够通过单次推理,直接判断问题是否可回答,并给出答案(如果可回答)。这种方法旨在减少推理次数,从而降低计算成本,提高效率。
技术框架:论文采用了一种单次推理的提示技术,具体流程如下:首先,将问题和上下文输入LLM;然后,LLM根据提示生成答案或表明问题无法回答;最后,评估LLM的回答质量。论文没有涉及复杂的模型架构,而是侧重于提示工程的设计。
关键创新:论文的关键创新在于提出了一种新的提示风格,该风格能够使LLM在单次推理中同时完成问题可答性判断和答案抽取。这种方法避免了双重推理带来的额外计算开销,提高了效率。
关键设计:论文的关键设计在于提示语的设计。具体的提示语内容未知,但其目标是引导LLM在生成答案的同时,能够明确地表达问题是否可以回答。论文可能使用了特定的关键词或短语,来区分可回答和不可回答的问题。
🖼️ 关键图片


📊 实验亮点
实验结果表明,小型微调模型在SQuAD2数据集上表现优于当前最先进的LLM。然而,在跨领域泛化测试中,最新的SOTA模型在五个测试的QA数据集中有三个上超过了微调模型,表明大型语言模型在处理不同领域问题时具有更强的适应性。
🎯 应用场景
该研究成果可应用于各种需要问答功能的场景,例如智能客服、信息检索、教育辅助等。通过优化提示策略,可以提高问答系统的效率和准确性,降低计算成本,并提升用户体验。尤其在资源受限的环境下,单次推理提示技术具有重要的应用价值。
📄 摘要(原文)
Large Language Models (LLMs) have been showing promising results for various NLP-tasks without the explicit need to be trained for these tasks by using few-shot or zero-shot prompting techniques. A common NLP-task is question-answering (QA). In this study, we propose a comprehensive performance comparison between smaller fine-tuned models and out-of-the-box instruction-following LLMs on the Stanford Question Answering Dataset 2.0 (SQuAD2), specifically when using a single-inference prompting technique. Since the dataset contains unanswerable questions, previous work used a double inference method. We propose a prompting style which aims to elicit the same ability without the need for double inference, saving compute time and resources. Furthermore, we investigate their generalization capabilities by comparing their performance on similar but different QA datasets, without fine-tuning neither model, emulating real-world uses where the context and questions asked may differ from the original training distribution, for example swapping Wikipedia for news articles. Our results show that smaller, fine-tuned models outperform current State-Of-The-Art (SOTA) LLMs on the fine-tuned task, but recent SOTA models are able to close this gap on the out-of-distribution test and even outperform the fine-tuned models on 3 of the 5 tested QA datasets.