Accelerating Retrieval-Augmented Generation
作者: Derrick Quinn, Mohammad Nouri, Neel Patel, John Salihu, Alireza Salemi, Sukhan Lee, Hamed Zamani, Mohammad Alian
分类: cs.CL, cs.AI, cs.AR, cs.DC, cs.IR
发布日期: 2024-12-14
💡 一句话要点
设计智能知识存储IKS,加速检索增强生成RAG中的精确近邻搜索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 近内存计算 CXL 精确近邻搜索 智能知识存储 IKS 硬件加速
📋 核心要点
- RAG旨在提升LLM的准确性,但现有检索方法效率不高,特别是精确检索方案面临高计算成本的挑战。
- 论文提出智能知识存储IKS,一种基于CXL的近内存加速架构,旨在加速RAG中的精确最近邻搜索。
- 实验表明,IKS相比CPU方案,在精确近邻搜索上实现了显著加速,并降低了RAG应用的端到端推理时间。
📝 摘要(中文)
检索增强生成(RAG)是一种解决大型语言模型(LLM)幻觉并提高准确性的新兴方案,它通过从外部知识源(如网络)检索信息来增强LLM。本文分析了几种RAG执行流程,揭示了检索和生成阶段之间复杂的相互作用。研究表明,精确检索方案虽然成本较高,但与近似检索方案相比,可以减少推理时间,因为精确检索模型可以向生成模型发送更小但更准确的文档列表,同时保持相同的端到端准确性。这一观察结果促使我们加速RAG的精确最近邻搜索。本文设计了智能知识存储(IKS),一种type-2 CXL设备,它实现了一种横向扩展的近内存加速架构,并在主机CPU和近内存加速器之间提供了一种新型的缓存一致性接口。与在Intel Sapphire Rapids CPU上执行搜索相比,IKS在512GB向量数据库上提供13.4-27.9倍更快的精确最近邻搜索。这种更高的搜索性能转化为代表性RAG应用程序1.7-26.3倍的端到端推理时间降低。IKS本质上是一个内存扩展器;其内部DRAM可以被分解并用于服务器上运行的其他应用程序,以防止DRAM(当今服务器中最昂贵的组件)被闲置。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)流程中,精确最近邻搜索计算开销大的问题。现有方法,特别是基于CPU的实现,在处理大规模向量数据库时效率较低,成为RAG应用的瓶颈。
核心思路:论文的核心思路是利用近内存计算加速精确最近邻搜索。通过将计算逻辑靠近存储数据的DRAM,减少数据传输延迟,从而提高搜索效率。同时,利用CXL接口实现CPU和加速器之间的高速缓存一致性,简化编程模型。
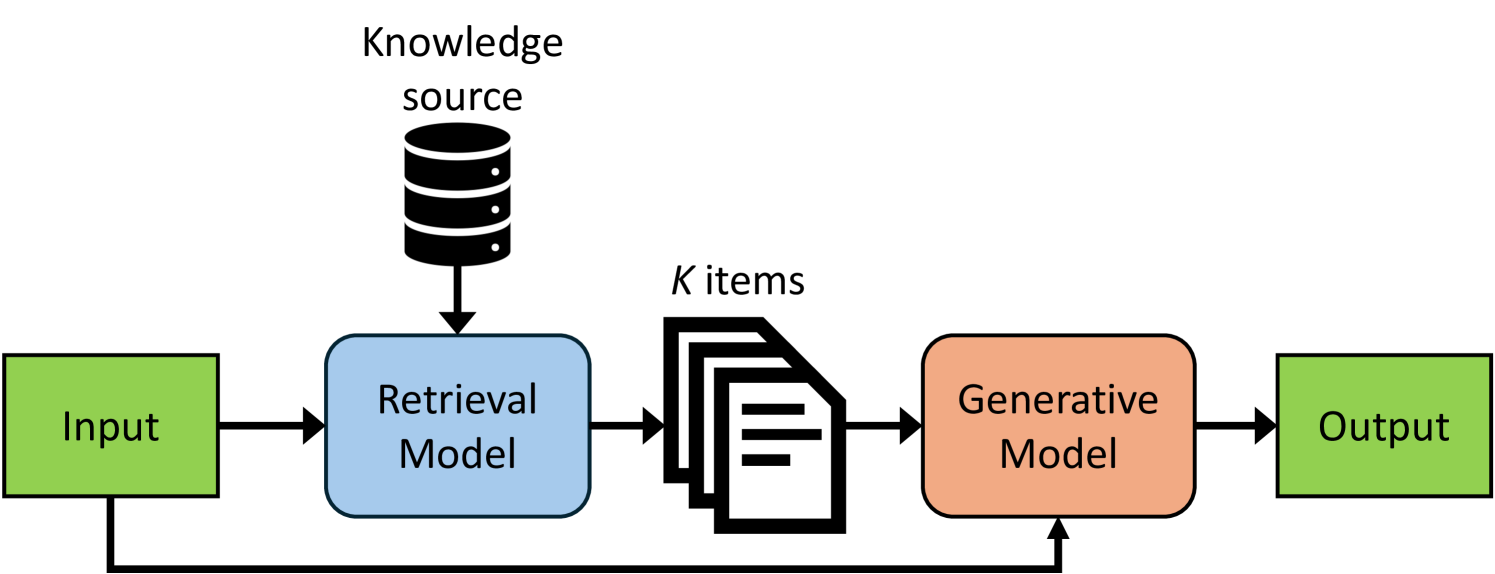
技术框架:论文提出了智能知识存储(IKS),它是一个Type-2 CXL设备,包含以下主要模块:1. 近内存加速器:负责执行精确最近邻搜索算法。2. 内部DRAM:存储向量数据库。3. CXL接口:提供CPU和加速器之间的高速缓存一致性连接。整体流程是:CPU将查询向量发送到IKS,IKS在内部DRAM中执行搜索,并将结果返回给CPU。
关键创新:论文的关键创新在于:1. 提出了基于CXL的近内存加速架构,有效降低了数据传输延迟。2. 设计了缓存一致性接口,简化了编程模型。3. IKS可以作为内存扩展器,在不需要加速搜索时,其内部DRAM可以被其他应用使用,提高了资源利用率。
关键设计:IKS的关键设计包括:1. 采用Type-2 CXL设备,允许CPU直接访问IKS的DRAM。2. 设计了高效的近邻搜索算法,充分利用近内存计算的优势。3. 实现了缓存一致性协议,保证CPU和加速器之间数据的一致性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
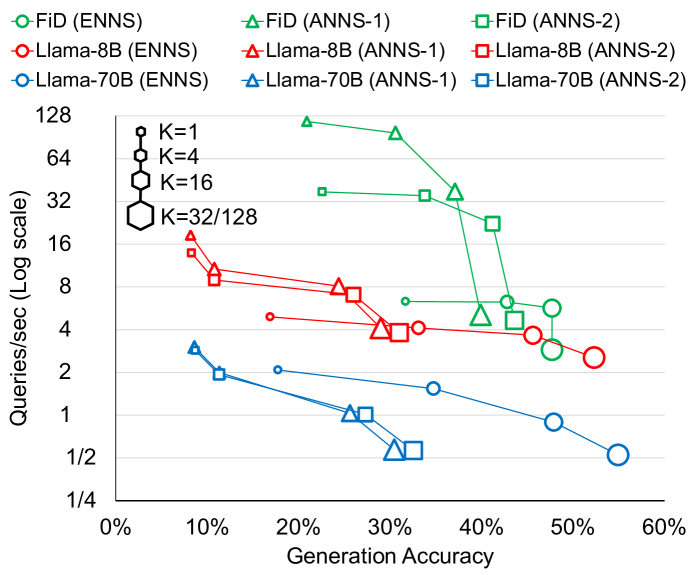
实验结果表明,IKS在512GB向量数据库上的精确最近邻搜索速度比Intel Sapphire Rapids CPU快13.4-27.9倍。对于代表性的RAG应用,IKS可以将端到端推理时间降低1.7-26.3倍。这些数据表明IKS在加速RAG应用方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于需要快速精确检索的RAG应用中,例如智能客服、知识图谱问答、文档检索等。通过加速检索过程,可以显著提升用户体验,并降低RAG应用的部署成本。未来,该技术有望应用于更广泛的AI推理加速场景。
📄 摘要(原文)
An evolving solution to address hallucination and enhance accuracy in large language models (LLMs) is Retrieval-Augmented Generation (RAG), which involves augmenting LLMs with information retrieved from an external knowledge source, such as the web. This paper profiles several RAG execution pipelines and demystifies the complex interplay between their retrieval and generation phases. We demonstrate that while exact retrieval schemes are expensive, they can reduce inference time compared to approximate retrieval variants because an exact retrieval model can send a smaller but more accurate list of documents to the generative model while maintaining the same end-to-end accuracy. This observation motivates the acceleration of the exact nearest neighbor search for RAG. In this work, we design Intelligent Knowledge Store (IKS), a type-2 CXL device that implements a scale-out near-memory acceleration architecture with a novel cache-coherent interface between the host CPU and near-memory accelerators. IKS offers 13.4-27.9x faster exact nearest neighbor search over a 512GB vector database compared with executing the search on Intel Sapphire Rapids CPUs. This higher search performance translates to 1.7-26.3x lower end-to-end inference time for representative RAG applications. IKS is inherently a memory expander; its internal DRAM can be disaggregated and used for other applications running on the server to prevent DRAM, which is the most expensive component in today's servers, from being stranded.