Can LLMs Help Create Grammar?: Automating Grammar Creation for Endangered Languages with In-Context Learning
作者: Piyapath T Spencer, Nanthipat Kongborrirak
分类: cs.CL
发布日期: 2024-12-14
备注: Preprint manuscript. Under revision. Accepted to COLING 2025
💡 一句话要点
利用上下文学习,LLM助力濒危语言的自动化语法生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文学习 濒危语言 语法生成 低资源语言
📋 核心要点
- 现有方法在为低资源濒危语言构建语法时面临数据稀缺和成本高昂的挑战。
- 论文提出利用LLM的上下文学习能力,通过少量双语数据生成目标语言的语法规则和词汇信息。
- 实验表明,LLM能够有效地捕捉目标语言的关键语法结构,为濒危语言保护提供了一种新途径。
📝 摘要(中文)
本文探讨了大型语言模型(LLM)在记录和保护濒危语言方面的应用前景,特别关注了如何通过上下文学习,在数据量有限的情况下,为低资源语言生成语法信息。研究以莫克伦语为例,评估了LLM在仅使用双语词典和平行句对的情况下,生成连贯语法规则和词条的能力,无需从头构建模型。该方法包括组织现有语言数据并通过提示有效地生成形式化的XLE语法。结果表明,LLM能够成功捕捉关键的语法结构和词汇信息,但也存在潜在的英语语法偏差等挑战。这项研究强调了LLM在加强语言文档工作方面的潜力,为生成语言数据提供了一种经济高效的解决方案,并有助于保护濒危语言。
🔬 方法详解
问题定义:论文旨在解决濒危语言语法资源匮乏的问题。传统语法构建方法需要大量标注数据和语言学专业知识,成本高昂且耗时,难以应用于缺乏资源的濒危语言。现有方法难以在数据稀疏的情况下,快速有效地生成可用的语法信息。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的上下文学习能力,通过少量双语词典和平行语料,引导LLM生成目标语言的语法规则和词汇条目。这种方法无需从头训练模型,降低了成本和数据需求。
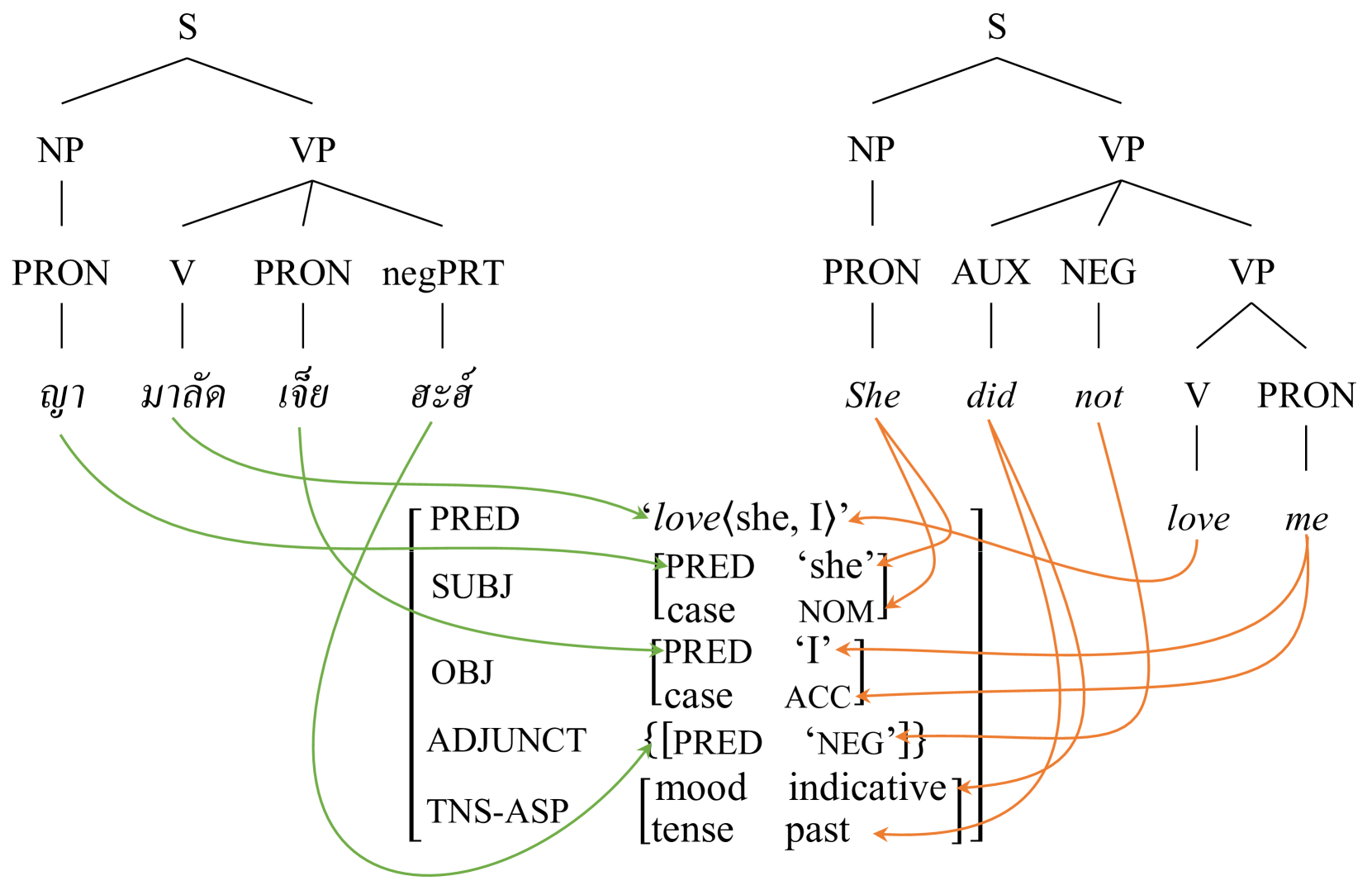
技术框架:该方法主要包含以下几个阶段:1) 数据准备:整理已有的双语词典和平行语料;2) 提示工程:设计合适的提示语,引导LLM生成目标语法信息;3) LLM生成:使用LLM(如GPT-3)根据提示语生成语法规则和词汇条目;4) 语法形式化:将LLM生成的非结构化文本转换为形式化的XLE语法。
关键创新:该方法最重要的创新在于利用LLM的上下文学习能力,实现了在低资源条件下自动化生成语法。与传统方法相比,该方法无需大量标注数据和人工干预,大大降低了语法构建的成本和时间。此外,该方法直接生成形式化的XLE语法,方便后续的语言处理应用。
关键设计:关键设计包括:1) 提示语的设计:提示语需要包含足够的上下文信息,引导LLM生成正确的语法规则。例如,可以提供一些例句和对应的语法分析结果,让LLM学习目标语言的语法结构。2) XLE语法的形式化:需要定义一套清晰的XLE语法规则,将LLM生成的文本转换为符合规范的语法结构。3) 实验评估:需要设计合理的实验评估指标,评估LLM生成的语法的质量和可用性。
🖼️ 关键图片

📊 实验亮点
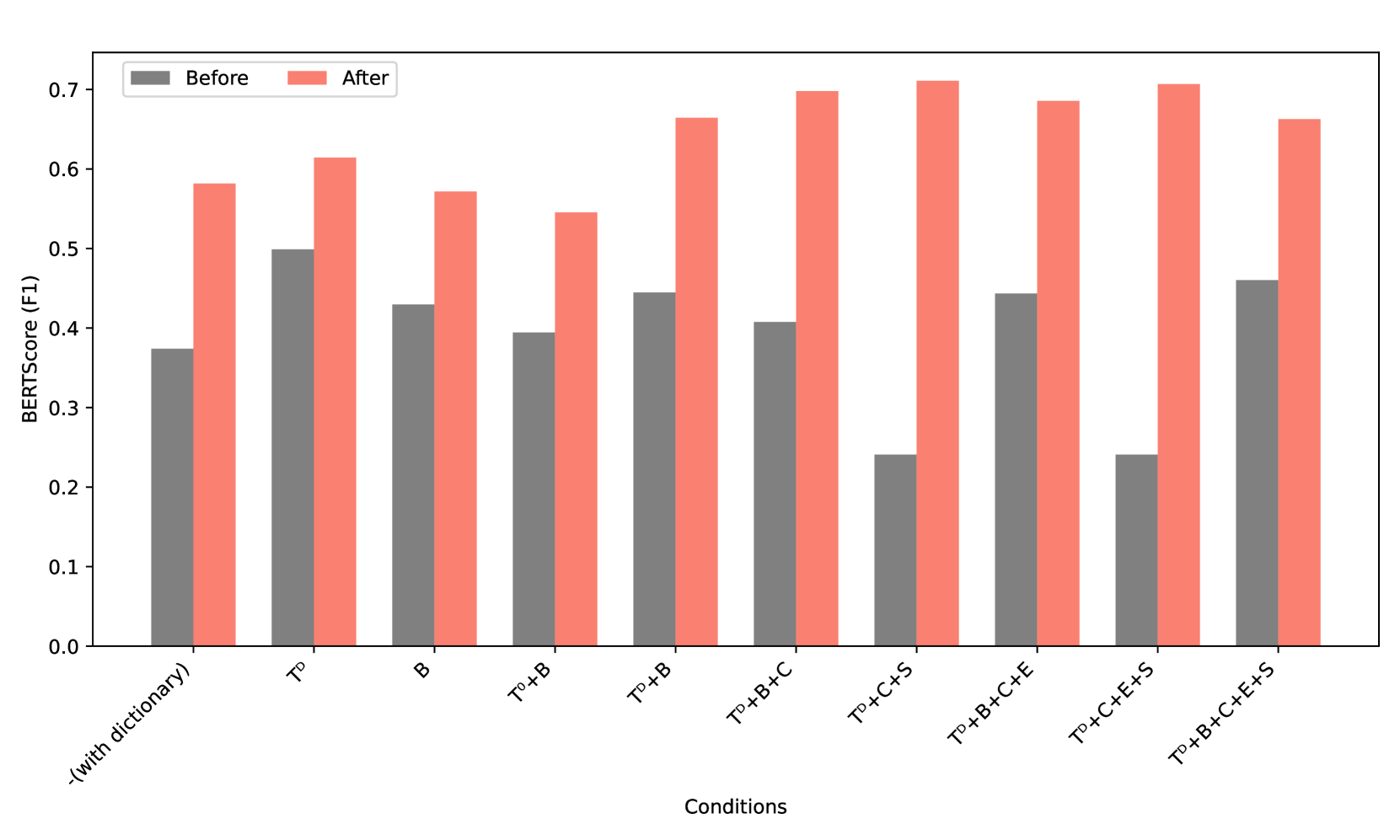
研究表明,LLM在仅使用少量双语数据的情况下,能够成功捕捉莫克伦语的关键语法结构和词汇信息,生成初步可用的XLE语法。虽然存在英语语法偏差等问题,但该方法为低资源语言的语法构建提供了一种经济高效的解决方案,具有重要的应用前景。
🎯 应用场景
该研究成果可广泛应用于濒危语言的保护和传承。通过自动化生成语法,可以快速构建低资源语言的语言资源,为语言教学、机器翻译、语音识别等应用提供支持。此外,该方法还可以应用于其他低资源场景,例如方言保护、古文字研究等,具有重要的社会价值和学术意义。
📄 摘要(原文)
Yes! In the present-day documenting and preserving endangered languages, the application of Large Language Models (LLMs) presents a promising approach. This paper explores how LLMs, particularly through in-context learning, can assist in generating grammatical information for low-resource languages with limited amount of data. We takes Moklen as a case study to evaluate the efficacy of LLMs in producing coherent grammatical rules and lexical entries using only bilingual dictionaries and parallel sentences of the unknown language without building the model from scratch. Our methodology involves organising the existing linguistic data and prompting to efficiently enable to generate formal XLE grammar. Our results demonstrate that LLMs can successfully capture key grammatical structures and lexical information, although challenges such as the potential for English grammatical biases remain. This study highlights the potential of LLMs to enhance language documentation efforts, providing a cost-effective solution for generating linguistic data and contributing to the preservation of endangered languages.