Rethinking Chain-of-Thought from the Perspective of Self-Training
作者: Zongqian Wu, Baoduo Xu, Ruochen Cui, Mengmeng Zhan, Xiaofeng Zhu, Lei Feng
分类: cs.CL, cs.AI
发布日期: 2024-12-14 (更新: 2025-05-25)
备注: 21 pages, 8 figures
💡 一句话要点
从自训练视角重新审视思维链,提出自适应迭代CoT框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 自训练 大型语言模型 提示工程 自适应迭代
📋 核心要点
- 现有CoT方法存在过度推理和连续迭代相似性高的问题,限制了推理性能的提升。
- 论文从自训练角度出发,设计任务特定提示和自适应迭代模块,优化CoT推理过程。
- 实验结果表明,该方法在推理性能和计算效率上均优于现有CoT方法,具有显著优势。
📝 摘要(中文)
思维链(CoT)推理已成为激发大型语言模型(LLM)潜在能力的有效方法。有趣的是,我们观察到CoT推理和自训练具有相同的核心目标:迭代地利用模型生成的信息来逐步降低预测不确定性。基于这一洞察,我们提出了一种新颖的CoT框架来提高推理性能。我们的框架集成了两个关键组件:(i)一个任务特定的提示模块,用于优化初始推理过程;(ii)一个自适应推理迭代模块,用于动态地细化推理过程,并解决先前CoT方法的局限性,即过度推理和连续推理迭代之间的高度相似性。大量的实验表明,所提出的方法在性能和计算效率方面都取得了显著的优势。
🔬 方法详解
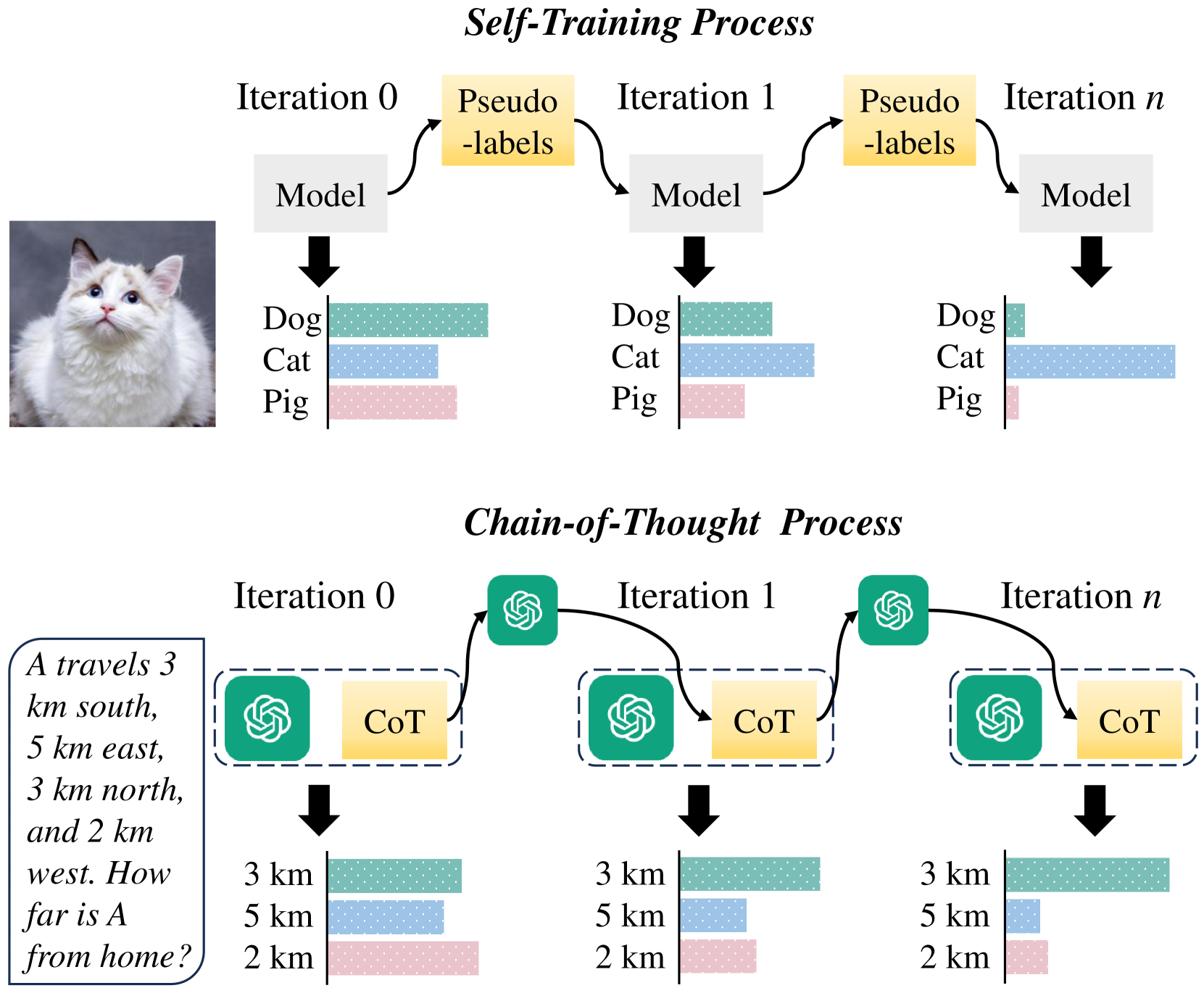
问题定义:论文旨在解决现有思维链(CoT)推理方法中存在的两个主要问题:一是“过度推理”,即推理步骤过多导致性能下降;二是连续推理迭代之间存在高度相似性,导致信息冗余和效率低下。这些问题限制了CoT方法在复杂推理任务中的应用效果。
核心思路:论文的核心思路是将CoT推理过程视为一种自训练过程,即利用模型自身生成的信息来逐步提高推理能力。通过优化初始推理过程和动态调整推理迭代过程,减少预测不确定性,从而提高推理性能。这种思路借鉴了自训练方法的迭代改进和逐步优化的思想。
技术框架:该框架包含两个主要模块:1) 任务特定提示模块:该模块旨在优化初始推理过程,通过精心设计的提示,引导模型生成更准确、更有效的初始推理步骤。2) 自适应推理迭代模块:该模块动态地细化推理过程,根据模型当前的推理状态和预测不确定性,自适应地调整推理迭代的次数和内容。该模块旨在解决过度推理和迭代相似性高的问题。
关键创新:论文的关键创新在于从自训练的角度重新审视CoT推理,并提出了自适应推理迭代模块。该模块能够动态地调整推理过程,避免过度推理和信息冗余,从而提高推理效率和准确性。与传统的CoT方法相比,该方法更加灵活和高效。
关键设计:任务特定提示模块的设计需要根据具体任务进行优化,例如,可以通过人工设计或自动搜索的方式找到最佳提示。自适应推理迭代模块的关键在于如何衡量模型当前的推理状态和预测不确定性,以及如何根据这些信息调整推理迭代的次数和内容。具体的实现细节(如参数设置、损失函数等)在论文中可能没有详细描述,需要进一步研究。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了所提出方法的有效性。实验结果表明,该方法在多个推理任务上取得了显著的性能提升,并且在计算效率方面也优于现有的CoT方法。具体的性能数据和对比基线在论文中应该有详细的展示,例如在某个数据集上提升了多少百分点。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如问答系统、自然语言推理、知识图谱推理等。通过提高推理的准确性和效率,可以提升这些应用的用户体验和性能。未来,该方法有望应用于更广泛的人工智能领域,例如机器人控制、智能决策等。
📄 摘要(原文)
Chain-of-thought (CoT) reasoning has emerged as an effective approach for activating latent capabilities in LLMs. Interestingly, we observe that both CoT reasoning and self-training share the core objective: iteratively leveraging model-generated information to progressively reduce prediction uncertainty. Building on this insight, we propose a novel CoT framework to improve reasoning performance. Our framework integrates two key components: (i) a task-specific prompt module that optimizes the initial reasoning process, and (ii) an adaptive reasoning iteration module that dynamically refines the reasoning process and addresses the limitations of previous CoT approaches, \ie over-reasoning and high similarity between consecutive reasoning iterations. Extensive experiments demonstrate that the proposed method achieves significant advantages in both performance and computational efficiency.