Learning to Verify Summary Facts with Fine-Grained LLM Feedback
作者: Jihwan Oh, Jeonghwan Choi, Nicole Hee-Yeon Kim, Taewon Yun, Hwanjun Song
分类: cs.CL, cs.AI
发布日期: 2024-12-14
备注: Accepted at COLING 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出FineSumFact数据集,利用LLM反馈提升摘要事实核查模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 摘要事实核查 大型语言模型 LLM反馈 数据增强 微调 自然语言处理 信息抽取
📋 核心要点
- 现有摘要事实核查模型受限于人工标注数据稀缺,阻碍了模型性能的进一步提升。
- 利用LLM生成细粒度反馈,构建大规模FineSumFact数据集,用于训练轻量级事实核查模型。
- 实验表明,基于LLM反馈训练的模型在人工测试集上表现优于人工标注数据训练的模型,且更具成本效益。
📝 摘要(中文)
训练自动摘要事实核查器通常面临缺乏人工标注数据的挑战。本文探索了利用大型语言模型(LLM)生成的反馈来解决使用人工标注数据的固有局限性的替代方法。我们引入了FineSumFact,一个包含摘要细粒度事实反馈的大规模数据集。我们使用10个不同的LLM进行多样化的摘要生成,并使用Llama-3-70B-Instruct进行反馈。我们利用该数据集来微调轻量级的开源模型Llama-3-8B-Instruct,优化资源效率,同时保持高性能。我们的实验结果表明,在大量LLM生成的数据集上训练的模型,在使用人工生成的测试集进行评估时,超过了在较小的人工标注数据集上训练的模型。使用LLM反馈微调事实核查模型可能比使用人工反馈更有效且成本更低。该数据集可在https://github.com/DISL-Lab/FineSumFact获取。
🔬 方法详解
问题定义:论文旨在解决摘要事实核查任务中,由于缺乏大规模人工标注数据而导致模型性能受限的问题。现有方法依赖于少量人工标注数据,难以覆盖各种摘要错误类型,且标注成本高昂。
核心思路:论文的核心思路是利用LLM强大的生成和理解能力,自动生成大量带有细粒度事实反馈的摘要数据,从而替代或补充人工标注数据。通过在这些LLM生成的数据上训练事实核查模型,可以提高模型对各种摘要错误的识别能力,并降低训练成本。
技术框架:整体框架包括三个主要阶段:1) 使用多个LLM生成多样化的摘要;2) 使用Llama-3-70B-Instruct对生成的摘要进行细粒度的事实性评估,生成反馈;3) 使用生成的摘要和反馈数据微调Llama-3-8B-Instruct模型,得到最终的事实核查模型。
关键创新:最重要的创新点在于利用LLM自动生成大规模、细粒度的摘要事实反馈数据集FineSumFact。这种方法摆脱了对大量人工标注数据的依赖,降低了训练成本,并提高了模型性能。
关键设计:论文的关键设计包括:1) 使用10个不同的LLM生成摘要,以保证数据的多样性;2) 使用Llama-3-70B-Instruct进行反馈,利用其强大的指令遵循能力;3) 使用Llama-3-8B-Instruct作为基础模型进行微调,兼顾性能和效率;4) 数据集包含细粒度的反馈信息,例如识别出摘要中哪些部分存在错误,以及错误的类型。
🖼️ 关键图片
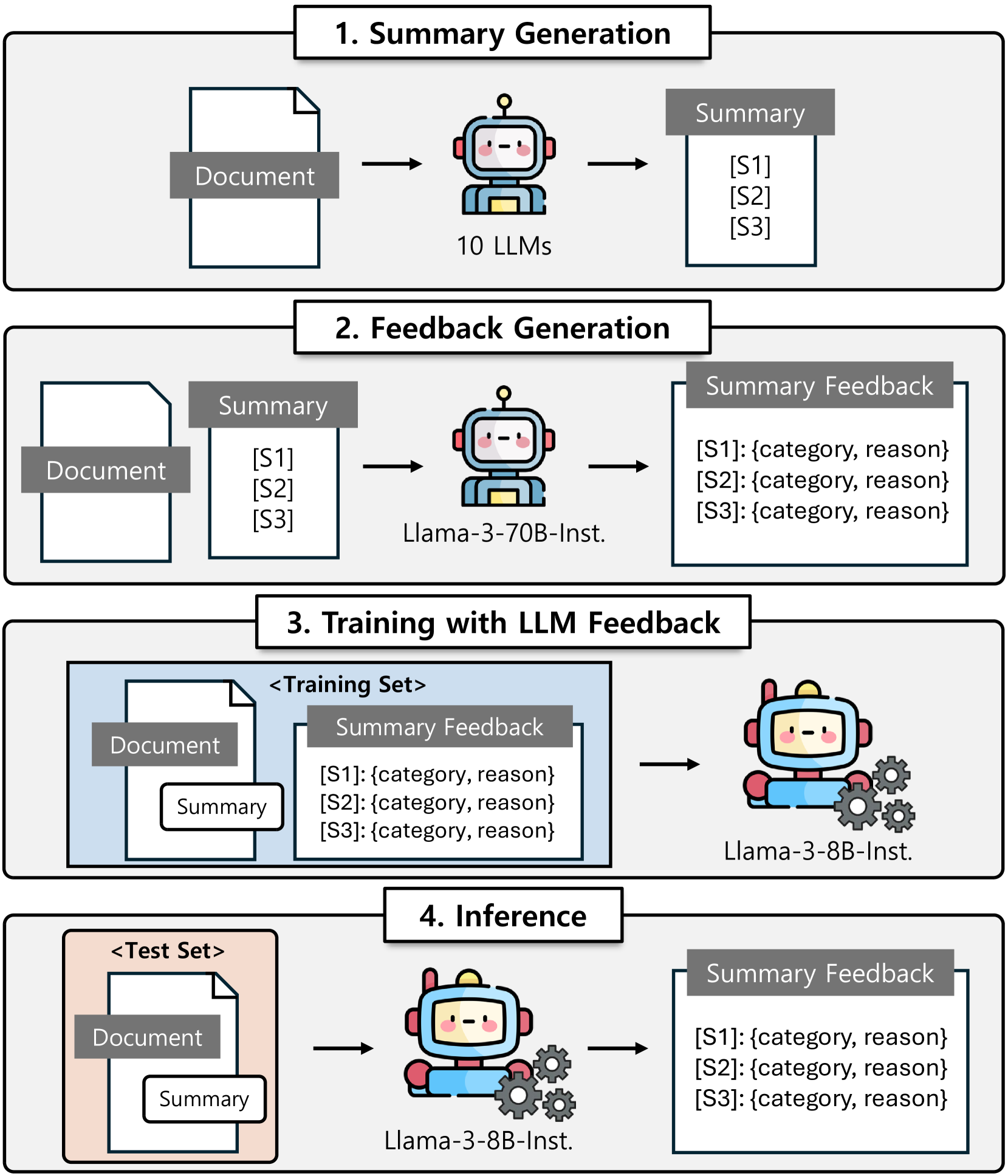

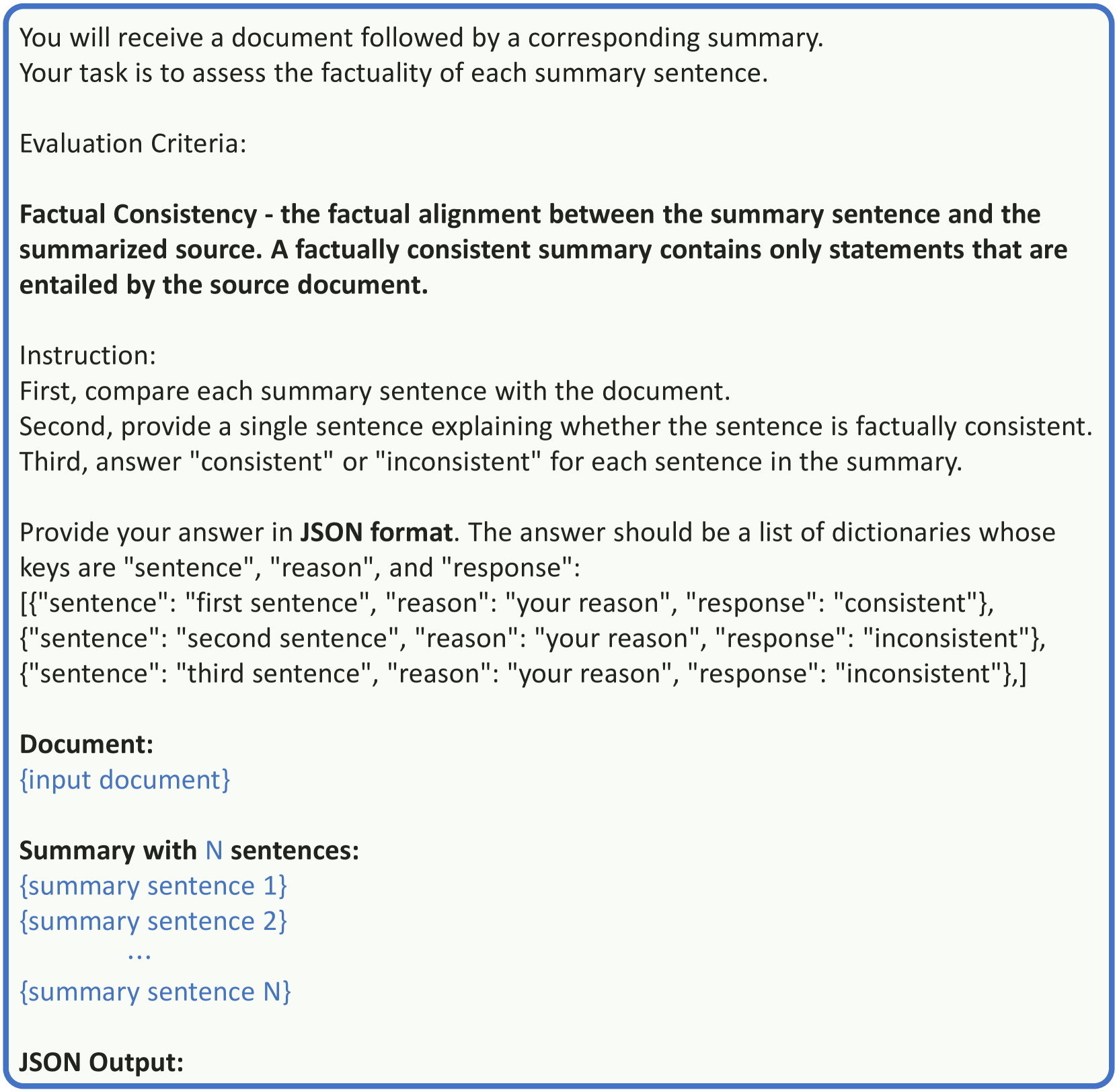
📊 实验亮点
实验结果表明,在FineSumFact数据集上训练的Llama-3-8B-Instruct模型,在使用人工生成的测试集进行评估时,性能超过了在人工标注数据集上训练的模型。这表明利用LLM生成的反馈进行微调,可以更有效地提升事实核查模型的性能,且更具成本效益。具体性能数据未知。
🎯 应用场景
该研究成果可广泛应用于自动摘要生成、新闻内容审核、学术论文评估等领域。通过自动核查摘要的事实性,可以提高信息质量,减少虚假信息的传播。未来,该方法还可以扩展到其他自然语言处理任务中,例如机器翻译、对话系统等。
📄 摘要(原文)
Training automatic summary fact verifiers often faces the challenge of a lack of human-labeled data. In this paper, we explore alternative way of leveraging Large Language Model (LLM) generated feedback to address the inherent limitation of using human-labeled data. We introduce FineSumFact, a large-scale dataset containing fine-grained factual feedback on summaries. We employ 10 distinct LLMs for diverse summary generation and Llama-3-70B-Instruct for feedback. We utilize this dataset to fine-tune the lightweight open-source model Llama-3-8B-Instruct, optimizing resource efficiency while maintaining high performance. Our experimental results reveal that the model trained on extensive LLM-generated datasets surpasses that trained on smaller human-annotated datasets when evaluated using human-generated test sets. Fine-tuning fact verification models with LLM feedback can be more effective and cost-efficient than using human feedback. The dataset is available at https://github.com/DISL-Lab/FineSumFact.