MPPO: Multi Pair-wise Preference Optimization for LLMs with Arbitrary Negative Samples
作者: Shuo Xie, Fangzhi Zhu, Jiahui Wang, Lulu Wen, Wei Dai, Xiaowei Chen, Junxiong Zhu, Kai Zhou, Bo Zheng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-13
备注: Accepted by COLING2025
💡 一句话要点
MPPO:面向任意负样本的大语言模型多重成对偏好优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏好优化 人类反馈 强化学习 多重回复 平均似然 模型对齐
📋 核心要点
- 现有偏好优化方法(如DPO)依赖参考模型,增加GPU资源消耗,且对数据量要求高,限制了其应用。
- MPPO算法通过平均模型响应可能性拟合奖励函数,充分利用多回复偏好数据,提升数据利用率。
- 实验表明,MPPO在MT-Bench和Arena-Hard等基准测试中显著优于DPO、ORPO和SimPO等方法。
📝 摘要(中文)
对齐大型语言模型(LLMs)与人类反馈对其发展至关重要。现有的偏好优化方法,如DPO和KTO,虽然在基于人类反馈的强化学习(RLHF)基础上有所改进,但本质上源于PPO,需要一个参考模型,这增加了GPU内存资源消耗,并且严重依赖于大量的偏好数据。同时,当前的偏好优化研究主要针对单问题双回复场景,忽略了多回复的优化,导致应用中数据浪费。本研究引入了MPPO算法,该算法利用模型响应的平均可能性来拟合奖励函数,并最大化偏好数据的利用率。通过比较Point-wise、Pair-wise和List-wise实现,我们发现Pair-wise方法实现了最佳性能,显著提高了模型响应的质量。实验结果表明,MPPO在各种基准测试中表现出色。在MT-Bench上,MPPO优于DPO、ORPO和SimPO。值得注意的是,在Arena-Hard上,MPPO大幅超越DPO和ORPO。这些成就突显了MPPO在偏好优化任务中的显著优势。
🔬 方法详解
问题定义:现有基于人类反馈的语言模型对齐方法,如DPO,虽然简化了RLHF流程,但仍然需要一个参考模型,增加了计算和存储开销。此外,现有方法主要处理单问题-双回复的偏好数据,忽略了实际应用中存在的多回复场景,造成了数据浪费。因此,如何更有效地利用偏好数据,同时降低对参考模型的依赖,是一个亟待解决的问题。
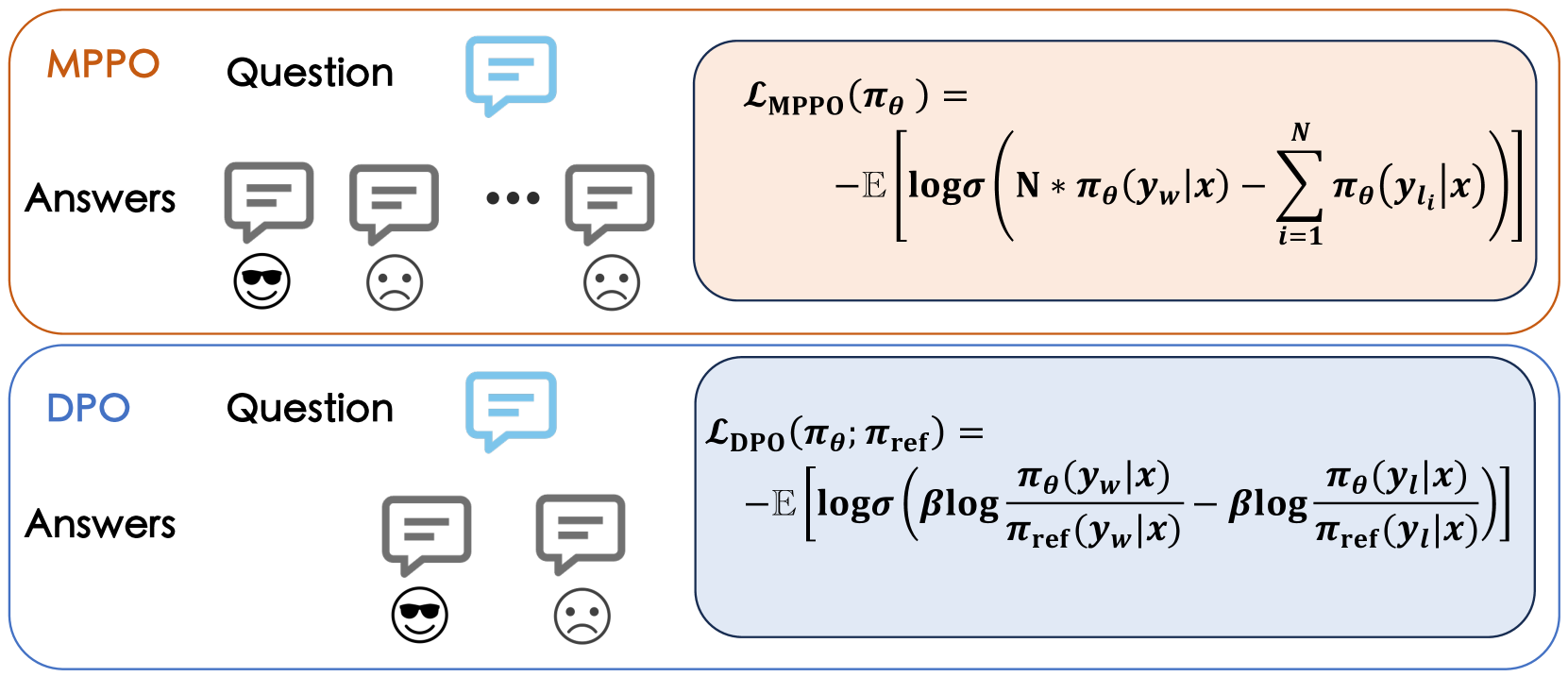
核心思路:MPPO的核心思路是通过最大化模型生成响应的平均似然来拟合奖励函数,从而避免直接学习奖励模型。具体来说,MPPO利用所有回复的平均似然来估计奖励,并使用成对偏好优化来训练模型。这种方法能够更有效地利用多回复偏好数据,并减少对参考模型的依赖。
技术框架:MPPO算法的整体框架包括以下几个主要步骤:1)收集包含多个回复的偏好数据;2)计算每个回复的平均似然;3)使用平均似然作为奖励信号;4)使用成对偏好优化目标训练模型。算法的关键在于如何有效地计算平均似然,并将其用于偏好优化。
关键创新:MPPO的关键创新在于使用平均似然来拟合奖励函数,从而避免了对参考模型的依赖。此外,MPPO还能够有效地利用多回复偏好数据,提高了数据利用率。与DPO等方法相比,MPPO在训练过程中不需要维护一个额外的参考模型,降低了计算和存储开销。
关键设计:MPPO使用交叉熵损失函数来优化模型,目标是最大化更受偏好回复的似然,同时最小化不太受偏好回复的似然。具体来说,对于每个问题,MPPO会选择一个受偏好的回复和一个不受偏好的回复,并计算它们的平均似然。然后,使用这些平均似然来计算交叉熵损失,并使用梯度下降来更新模型参数。此外,MPPO还探索了Point-wise、Pair-wise和List-wise三种不同的实现方式,实验结果表明Pair-wise方法效果最佳。
🖼️ 关键图片

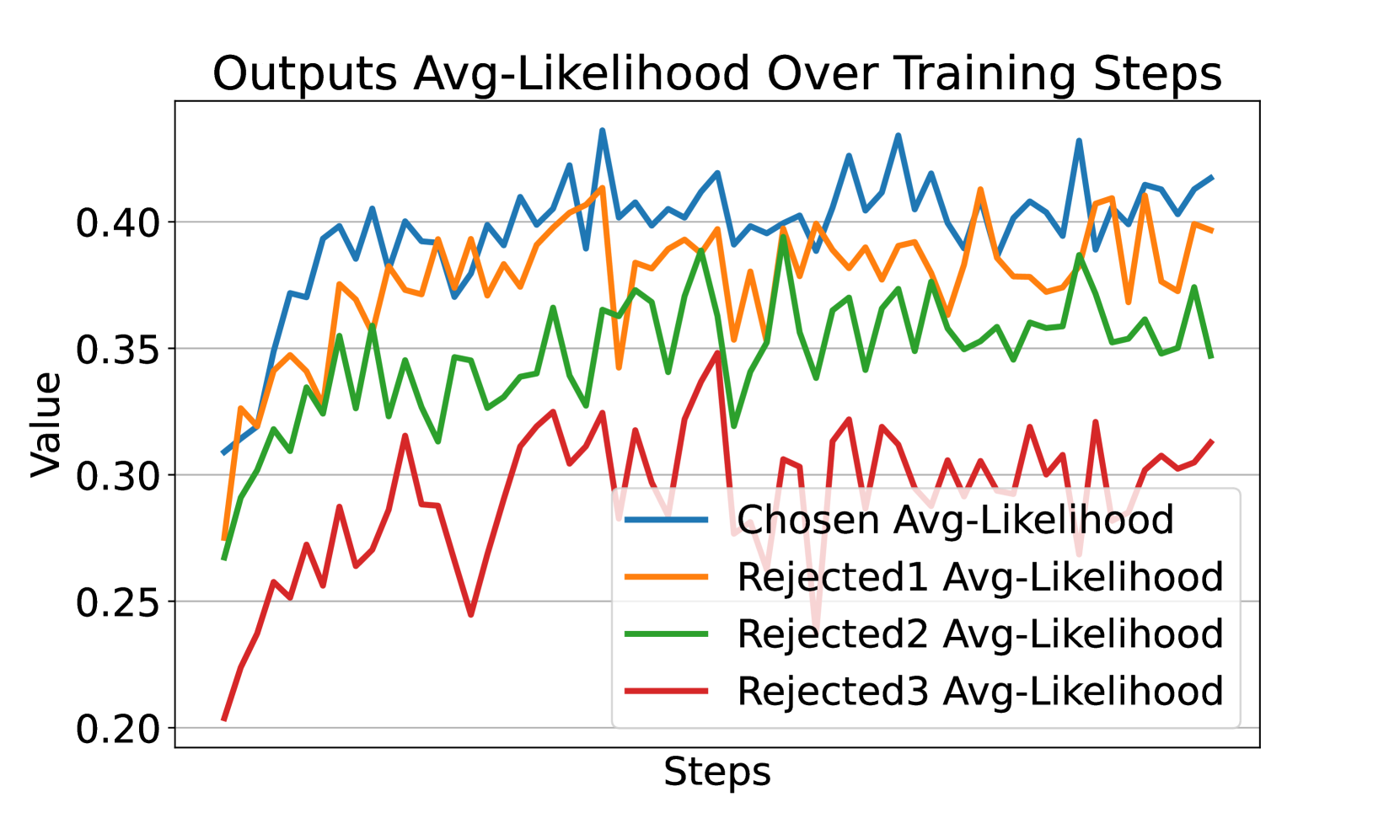
📊 实验亮点
实验结果表明,MPPO在MT-Bench和Arena-Hard等基准测试中取得了显著的性能提升。在MT-Bench上,MPPO优于DPO、ORPO和SimPO。更值得注意的是,在更具挑战性的Arena-Hard基准上,MPPO大幅超越了DPO和ORPO,验证了MPPO在处理复杂偏好优化任务方面的优势。这些结果表明,MPPO是一种有效的偏好优化算法,能够显著提升语言模型的性能。
🎯 应用场景
MPPO算法可广泛应用于各种需要对齐语言模型与人类偏好的场景,例如对话系统、文本摘要、代码生成等。通过更有效地利用偏好数据,MPPO能够提升模型生成内容的质量和安全性,使其更符合人类的期望和价值观。该研究的成果有助于推动语言模型在实际应用中的落地。
📄 摘要(原文)
Aligning Large Language Models (LLMs) with human feedback is crucial for their development. Existing preference optimization methods such as DPO and KTO, while improved based on Reinforcement Learning from Human Feedback (RLHF), are inherently derived from PPO, requiring a reference model that adds GPU memory resources and relies heavily on abundant preference data. Meanwhile, current preference optimization research mainly targets single-question scenarios with two replies, neglecting optimization with multiple replies, which leads to a waste of data in the application. This study introduces the MPPO algorithm, which leverages the average likelihood of model responses to fit the reward function and maximizes the utilization of preference data. Through a comparison of Point-wise, Pair-wise, and List-wise implementations, we found that the Pair-wise approach achieves the best performance, significantly enhancing the quality of model responses. Experimental results demonstrate MPPO's outstanding performance across various benchmarks. On MT-Bench, MPPO outperforms DPO, ORPO, and SimPO. Notably, on Arena-Hard, MPPO surpasses DPO and ORPO by substantial margins. These achievements underscore the remarkable advantages of MPPO in preference optimization tasks.