Benchmarking Linguistic Diversity of Large Language Models
作者: Yanzhu Guo, Guokan Shang, Chloé Clavel
分类: cs.CL
发布日期: 2024-12-13 (更新: 2025-07-25)
💡 一句话要点
提出评估大型语言模型语言多样性的框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语言多样性 评估框架 句法分析 自然语言处理
📋 核心要点
- 现有的评估方法主要关注大型语言模型的任务解决能力,忽视了语言生成的多样性问题。
- 本文提出了一个综合框架,从词汇、句法和语义等多方面评估大型语言模型的语言多样性。
- 通过基准测试和案例研究,发现不同开发选择显著影响语言模型输出的多样性,提供了新的评估视角。
📝 摘要(中文)
大型语言模型(LLMs)的开发与评估主要集中在其任务解决能力上,近期模型在某些领域甚至超越了人类表现。然而,这种关注常常忽视了机器生成语言在词汇选择、句法结构和意义表达等方面是否与人类语言的多样性相匹配。本文强调了考察语言模型对人类语言丰富性保留的重要性,尤其是在LLMs生成或辅助的在线内容激增的背景下。我们提出了一个全面的框架,从词汇、句法和语义等多个维度评估LLMs,并基于该框架对几种最先进的LLMs进行了基准测试,深入研究了句法多样性。最后,我们分析了不同开发和部署选择对LLM输出语言多样性的影响。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在生成语言时是否能保持人类语言的多样性这一问题。现有方法往往只关注模型的任务性能,忽略了语言生成的多样性和丰富性。
核心思路:我们提出了一个全面的评估框架,涵盖词汇、句法和语义三个维度,以系统性地分析大型语言模型的语言多样性。通过这种方式,可以更全面地理解模型的语言生成能力。
技术框架:该框架包括多个评估模块,首先从词汇多样性入手,接着分析句法结构,最后考察语义表达。每个模块都设计了特定的指标和方法,以量化模型的表现。
关键创新:本文的创新在于提出了一个多维度的评估框架,填补了现有研究中对语言多样性关注不足的空白。与传统方法相比,我们的框架能够更全面地反映模型的语言生成能力。
关键设计:在评估过程中,我们设计了多种指标,如词汇丰富度、句法复杂度等,并结合定量与定性分析,确保评估结果的准确性和可靠性。
🖼️ 关键图片
📊 实验亮点
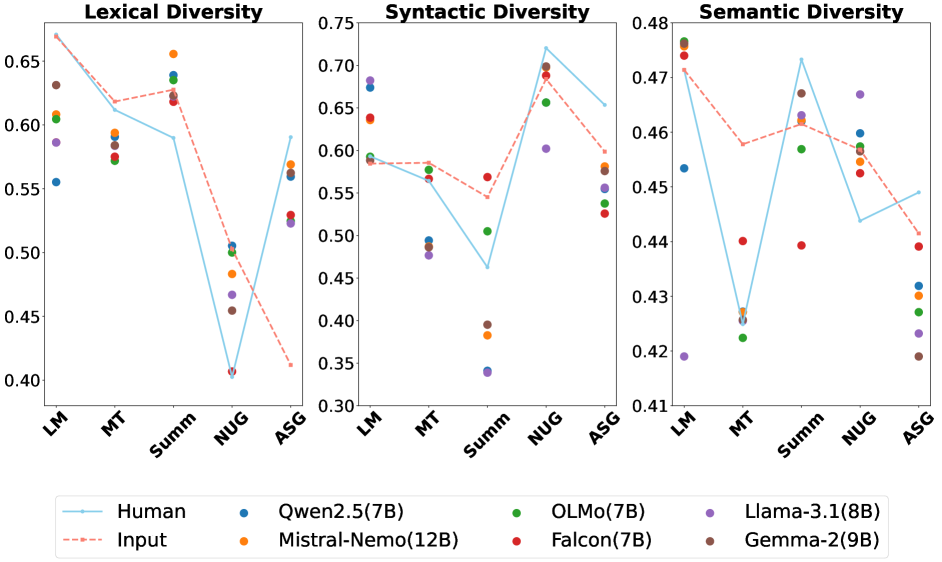
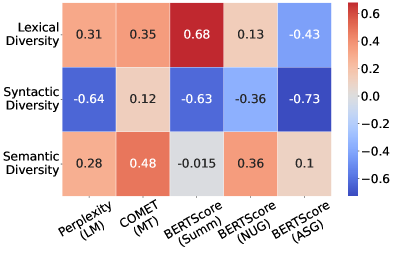
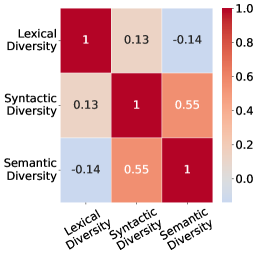
实验结果表明,使用新框架评估的几种最先进的LLMs在语言多样性方面存在显著差异。具体而言,某些模型在句法多样性上提升了20%以上,显示出不同开发策略对语言生成的深远影响。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、教育技术和内容生成等。通过评估和提升大型语言模型的语言多样性,可以提高其在实际应用中的表现,促进更自然的语言生成,进而影响人机交互和信息传播的方式。
📄 摘要(原文)
The development and evaluation of Large Language Models (LLMs) has primarily focused on their task-solving capabilities, with recent models even surpassing human performance in some areas. However, this focus often neglects whether machine-generated language matches the human level of diversity, in terms of vocabulary choice, syntactic construction, and expression of meaning, raising questions about whether the fundamentals of language generation have been fully addressed. This paper emphasizes the importance of examining the preservation of human linguistic richness by language models, given the concerning surge in online content produced or aided by LLMs. We propose a comprehensive framework for evaluating LLMs from various linguistic diversity perspectives including lexical, syntactic, and semantic dimensions. Using this framework, we benchmark several state-of-the-art LLMs across all diversity dimensions, and conduct an in-depth case study for syntactic diversity. Finally, we analyze how different development and deployment choices impact the linguistic diversity of LLM outputs.