Targeted Angular Reversal of Weights (TARS) for Knowledge Removal in Large Language Models
作者: Harry J. Davies, Giorgos Iacovides, Danilo P. Mandic
分类: cs.CL, cs.AI
发布日期: 2024-12-13 (更新: 2024-12-16)
备注: 14 pages, 5 figures, 1 table. Fixing typo with the final weight editing equation
💡 一句话要点
提出TARS方法,通过定向反转权重有效移除大语言模型中的特定知识。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识移除 大语言模型 权重反转 定向干预 模型安全
📋 核心要点
- 大型语言模型存在学习到有害或不应公开知识的风险,现有方法难以兼顾多语言、全方向移除和性能保持。
- TARS方法通过识别并反转与目标概念相关的权重向量,从而阻止该概念在模型中的传播。
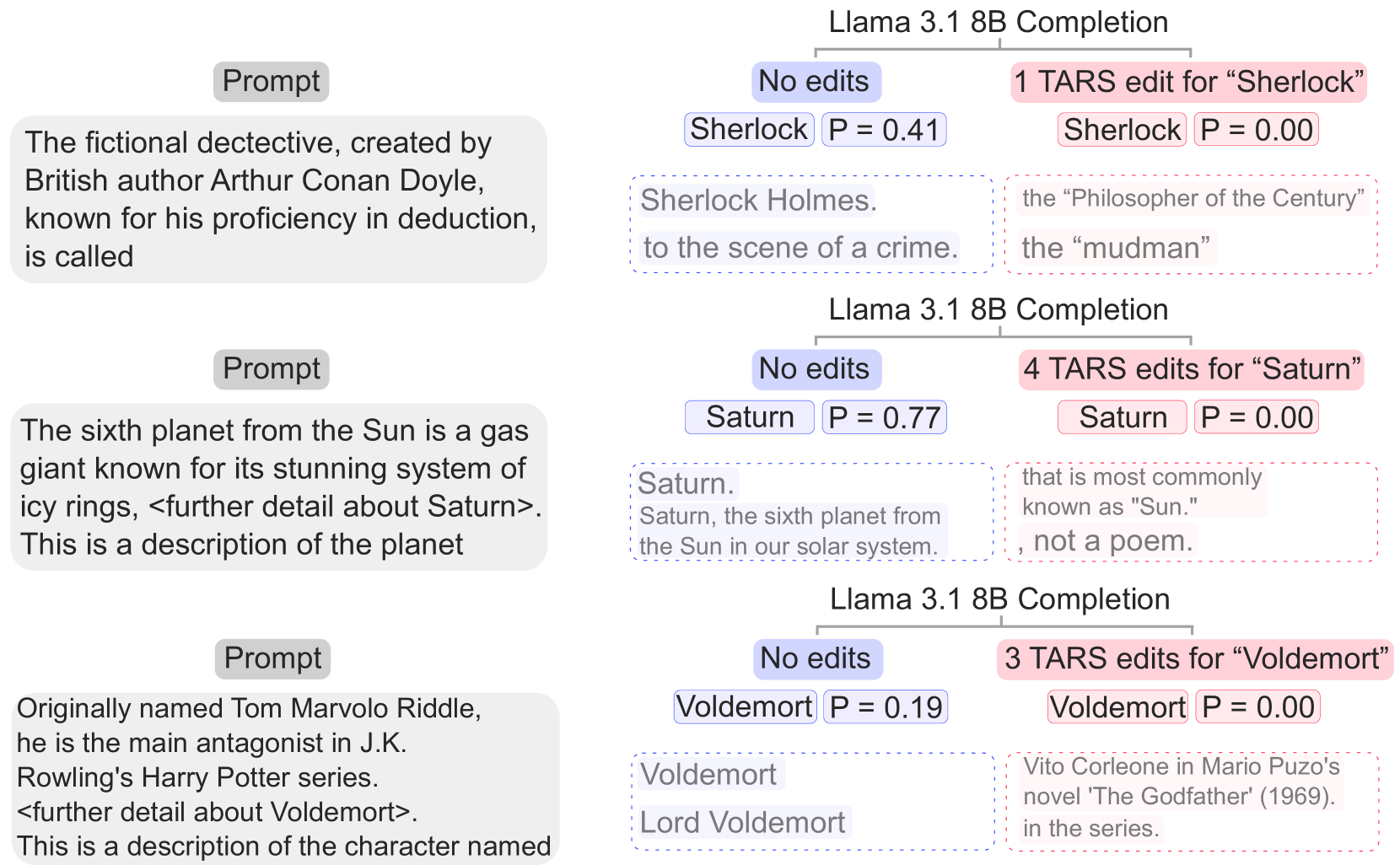
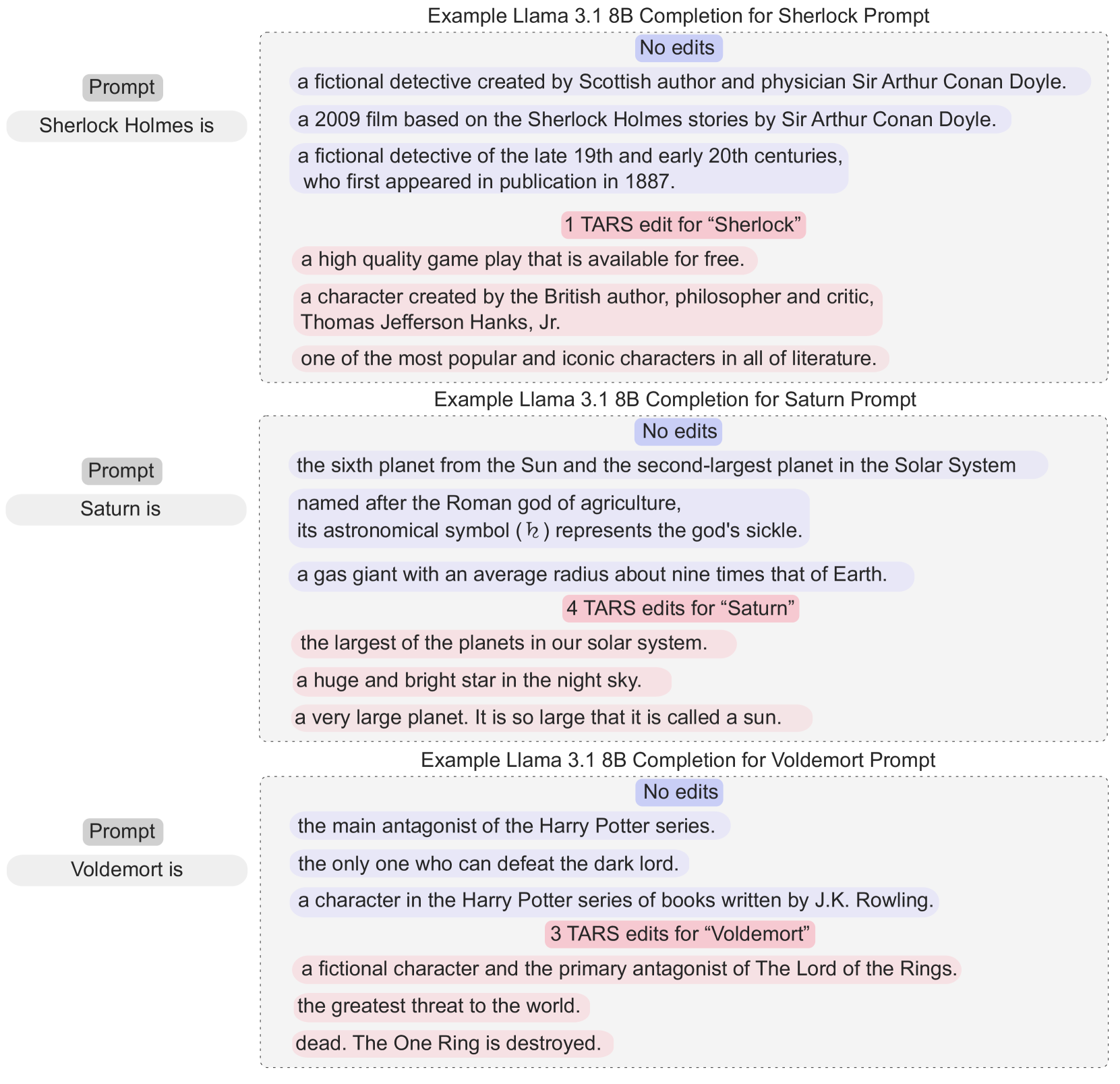
- 实验表明,TARS能有效移除特定知识,且对模型整体性能影响很小,在多语言环境下也有效。
📝 摘要(中文)
现代大型语言模型(LLM)训练所需的海量数据带来了显著风险,因为模型可能获得生物安全等敏感主题的知识,以及复制受版权保护作品的能力。旨在移除此类知识的方法必须能够从所有提示方向、以多语言能力进行,且不降低模型的一般性能。为此,我们引入了目标角度反转(TARS)方法,用于从LLM中移除知识。TARS方法首先利用LLM结合详细提示,在LLM的内部表示空间中聚合关于选定概念的信息。然后,通过用噪声扰动近似概念向量并使用语言模型头将其转换为token分数,来细化此近似概念向量,以高概率触发概念token。然后,将LLM中直接作用于内部表示空间且与此目标向量具有最高余弦相似度的前馈权重向量替换为反转的目标向量,从而限制概念在模型中的传播能力。TARS方法的模块化允许从Llama 3.1 8B中顺序移除概念,例如著名文学侦探夏洛克·福尔摩斯和土星。实验证明,只需1次TARS编辑即可将触发目标概念的概率降低到0.00,同时双向移除知识。此外,实验表明,尽管仅以英语为目标,但知识可以在所有语言中被移除。重要的是,TARS对模型的一般能力影响最小,因为在以模块化方式移除5个不同的概念后,LLM在大型维基百科文本语料库上的下一个token概率的KL散度最小(中位数为0.0015)。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的知识安全问题,即模型可能无意中学习到不应公开或有害的知识,例如生物安全信息或受版权保护的内容。现有知识移除方法的痛点在于,它们通常难以在多语言环境下工作,无法从所有可能的提示方向移除知识,并且容易对模型的一般性能造成较大影响。
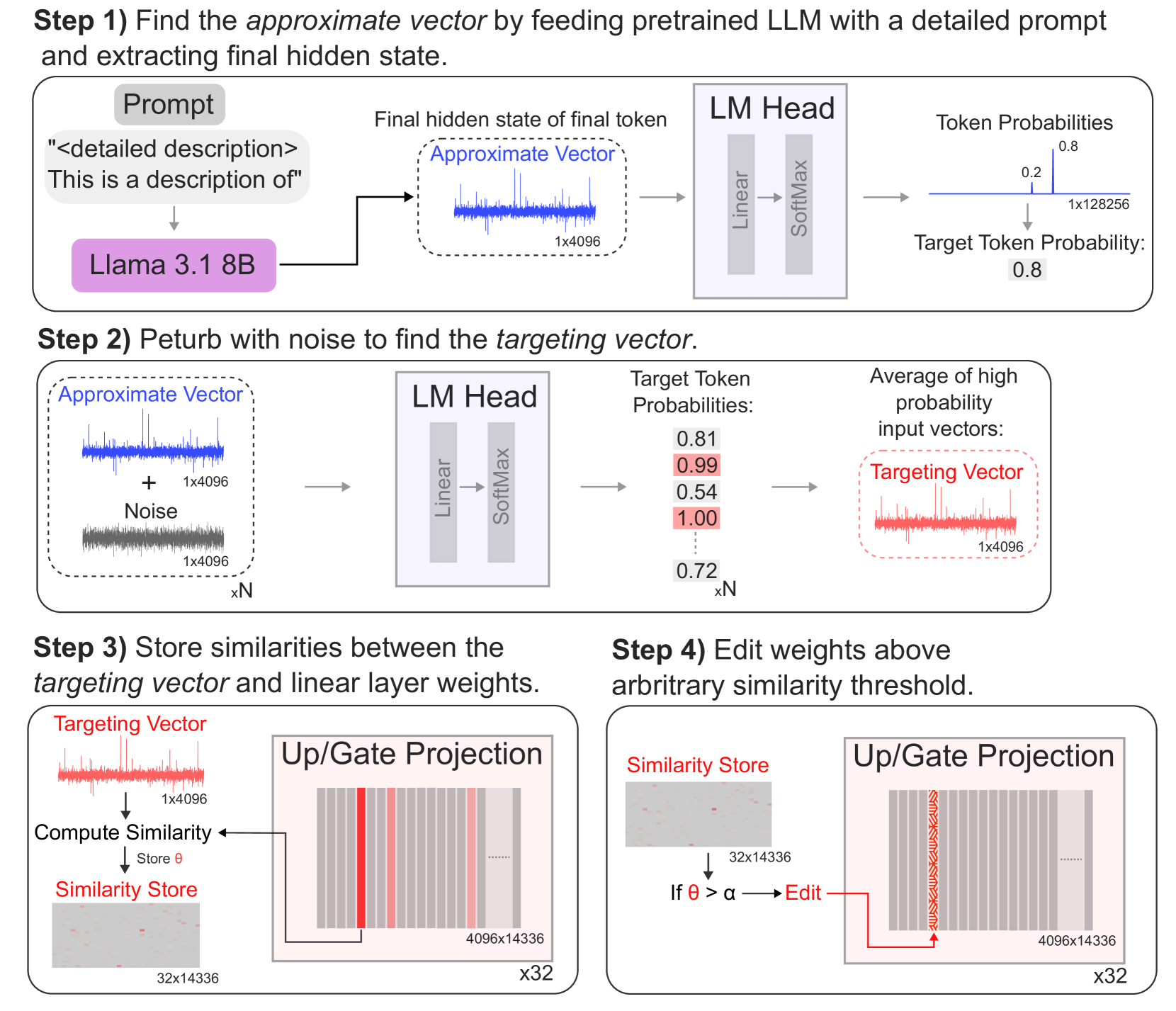
核心思路:TARS方法的核心思路是通过定向反转LLM中与目标概念相关的权重向量,从而阻止该概念在模型中的传播。具体来说,该方法首先识别出对目标概念激活贡献最大的权重向量,然后将其方向反转,从而使得模型在遇到相关提示时,不再激活该概念。这种方法旨在实现精确的知识移除,同时尽量减少对模型整体性能的干扰。
技术框架:TARS方法主要包含以下几个阶段: 1. 概念向量聚合:利用LLM和详细的提示,在模型的内部表示空间中聚合关于目标概念的信息,形成一个近似的概念向量。 2. 概念向量细化:通过向近似概念向量添加噪声,并使用语言模型头将其转换为token分数,来细化该向量,使其能够以高概率触发目标概念的token。 3. 权重向量反转:找到LLM中直接作用于内部表示空间,并且与细化后的目标向量具有最高余弦相似度的前馈权重向量,然后将其替换为反转后的目标向量。
关键创新:TARS方法的关键创新在于其定向反转权重向量的策略。与以往的知识移除方法相比,TARS能够更精确地定位并移除与目标概念相关的知识,从而减少对模型整体性能的影响。此外,TARS方法的模块化设计使其能够顺序移除多个概念,而不会相互干扰。
关键设计:TARS方法中的关键设计包括: 1. 目标向量的构建:通过结合LLM和详细提示,以及噪声扰动和token分数转换,来构建一个能够有效触发目标概念的精确目标向量。 2. 权重向量的选择:选择与目标向量具有最高余弦相似度的前馈权重向量,以确保移除的是对目标概念激活贡献最大的权重。 3. 模块化移除:允许顺序移除多个概念,而不会显著影响模型性能,通过控制每次反转的权重数量和反转幅度来实现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TARS方法能够有效地移除LLM中的特定知识。例如,只需一次TARS编辑,即可将触发目标概念(如夏洛克·福尔摩斯、土星)的概率降低到0.00。同时,该方法对模型的一般性能影响很小,在移除5个不同的概念后,LLM在维基百科文本语料库上的下一个token概率的KL散度中位数仅为0.0015。更重要的是,TARS方法能够在多语言环境下工作,即使仅以英语为目标,也能在其他语言中移除相关知识。
🎯 应用场景
TARS方法可应用于多种场景,例如:移除LLM中的有害信息(如仇恨言论、虚假信息),保护版权内容,以及定制化LLM的行为。该方法有助于提高LLM的安全性、可靠性和可控性,使其更适用于各种实际应用,例如智能客服、内容生成和教育等领域。未来,TARS有望成为LLM安全治理的重要工具。
📄 摘要(原文)
The sheer scale of data required to train modern large language models (LLMs) poses significant risks, as models are likely to gain knowledge of sensitive topics such as bio-security, as well the ability to replicate copyrighted works. Methods designed to remove such knowledge must do so from all prompt directions, in a multi-lingual capacity and without degrading general model performance. To this end, we introduce the targeted angular reversal (TARS) method of knowledge removal from LLMs. The TARS method firstly leverages the LLM in combination with a detailed prompt to aggregate information about a selected concept in the internal representation space of the LLM. It then refines this approximate concept vector to trigger the concept token with high probability, by perturbing the approximate concept vector with noise and transforming it into token scores with the language model head. The feedforward weight vectors in the LLM which operate directly on the internal representation space, and have the highest cosine similarity with this targeting vector, are then replaced by a reversed targeting vector, thus limiting the ability of the concept to propagate through the model. The modularity of the TARS method allows for a sequential removal of concepts from Llama 3.1 8B, such as the famous literary detective Sherlock Holmes, and the planet Saturn. It is demonstrated that the probability of triggering target concepts can be reduced to 0.00 with as few as 1 TARS edit, whilst simultaneously removing the knowledge bi-directionally. Moreover, knowledge is shown to be removed across all languages despite only being targeted in English. Importantly, TARS has minimal impact on the general model capabilities, as after removing 5 diverse concepts in a modular fashion, there is minimal KL divergence in the next token probabilities of the LLM on large corpora of Wikipedia text (median of 0.0015).