ASLoRA: Adaptive Sharing Low-Rank Adaptation Across Layers
作者: Junyan Hu, Xue Xiao, Mengqi Zhang, Yao Chen, Zhaochun Ren, Zhumin Chen, Pengjie Ren
分类: cs.CL
发布日期: 2024-12-13 (更新: 2024-12-16)
💡 一句话要点
ASLoRA:提出自适应跨层共享低秩适配方法,提升大模型微调效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适配 跨层参数共享 大型语言模型 自适应学习
📋 核心要点
- 全参数微调大型语言模型成本高昂,LoRA等方法虽降低了参数量,但仍有优化空间。
- ASLoRA通过跨层共享低秩矩阵A并自适应合并矩阵B,缓解过拟合并捕获层间依赖。
- 实验表明,ASLoRA在参数量少于LoRA 25%的情况下,性能优于LoRA,并提升了模型灵活性。
📝 摘要(中文)
随着大型语言模型(LLMs)规模的增长,传统的全参数微调因其高昂的计算和存储成本而变得越来越不切实际。虽然诸如LoRA等流行的参数高效微调方法已经显著减少了可调参数的数量,但仍有进一步优化的空间。本文提出了ASLoRA,一种结合全局共享和部分自适应共享的跨层参数共享策略。具体而言,我们跨所有层共享低秩矩阵A,并在训练期间自适应地合并矩阵B。这种共享机制不仅有效地缓解了过拟合,而且捕获了层间依赖关系,从而显著增强了模型的表征能力。我们在各种NLP任务上进行了广泛的实验,结果表明ASLoRA优于LoRA,同时使用的参数不到LoRA的25%,突出了其灵活性和卓越的参数效率。此外,对自适应共享策略的深入分析证实了其在增强模型灵活性和任务适应性方面的显著优势。
🔬 方法详解
问题定义:现有的大型语言模型微调方法,如全参数微调,计算和存储成本过高。LoRA等参数高效微调方法虽然减少了可训练参数的数量,但仍然存在参数冗余,且未能充分利用层与层之间的依赖关系,导致模型性能提升受限。
核心思路:ASLoRA的核心思路是跨层参数共享,通过共享部分参数来减少模型参数量,并利用自适应合并机制来捕获层间依赖关系。具体来说,共享低秩矩阵A可以减少参数量,而自适应合并矩阵B则允许模型根据不同层的特性进行调整,从而提高模型的灵活性和表达能力。
技术框架:ASLoRA在LoRA的基础上进行改进。LoRA在预训练模型的每一层插入两个低秩矩阵A和B进行微调。ASLoRA则将矩阵A在所有层之间共享,而矩阵B则采用自适应合并的方式。训练过程中,矩阵B会根据每一层的特定需求进行调整,最终合并到原始模型参数中。
关键创新:ASLoRA的关键创新在于其自适应跨层参数共享策略。与LoRA相比,ASLoRA通过共享矩阵A进一步减少了参数量,并通过自适应合并矩阵B来增强模型的灵活性。这种共享和自适应的结合,使得ASLoRA能够在减少参数量的同时,更好地捕获层间依赖关系,从而提高模型性能。
关键设计:ASLoRA的关键设计包括:1) 矩阵A的全局共享,这显著减少了参数量。2) 矩阵B的自适应合并,这允许模型根据不同层的特性进行调整。3) 训练过程中,矩阵B的更新采用标准的梯度下降算法。具体的损失函数和网络结构与LoRA保持一致,主要关注矩阵A和B的共享和合并策略。
🖼️ 关键图片
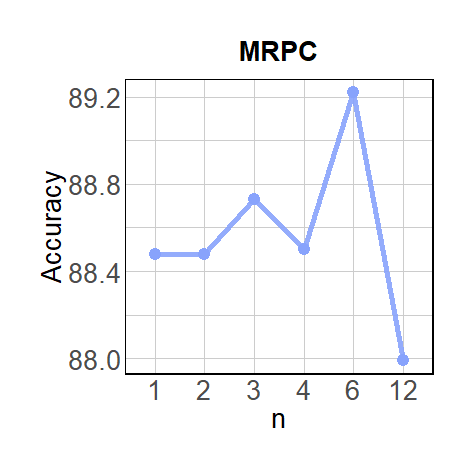
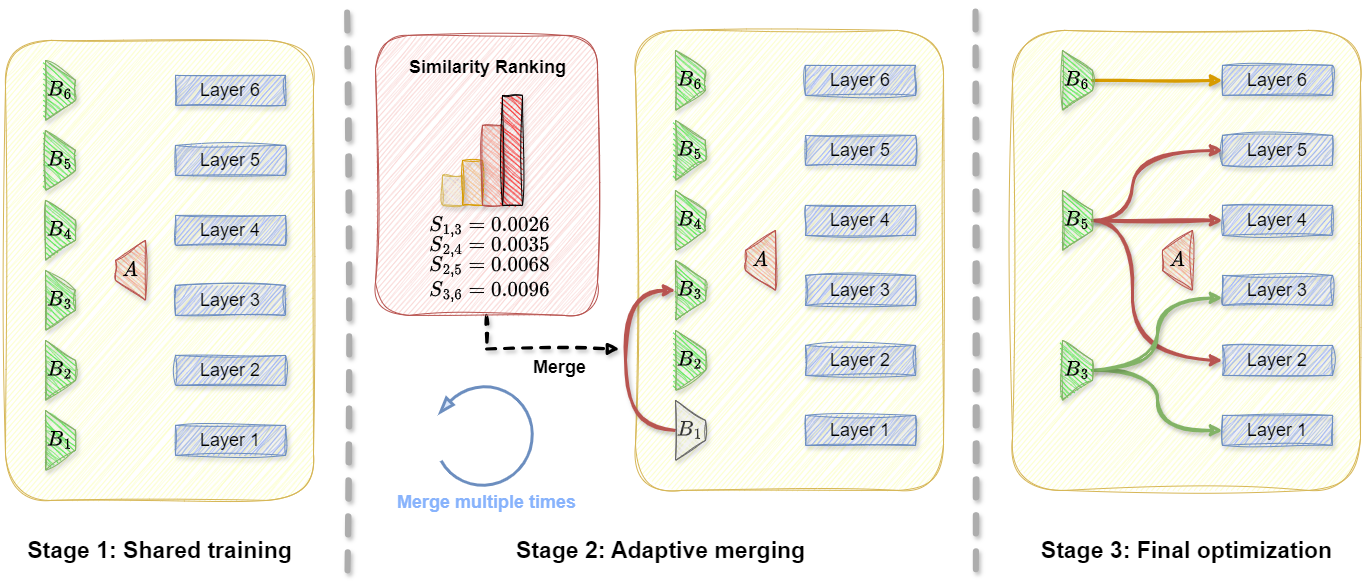

📊 实验亮点
实验结果表明,ASLoRA在多个NLP任务上优于LoRA,同时使用的参数量不到LoRA的25%。例如,在文本分类任务中,ASLoRA在参数量减少75%的情况下,性能与LoRA相当甚至略有提升。此外,对自适应共享策略的分析表明,ASLoRA能够更好地捕获层间依赖关系,从而提高模型的泛化能力。
🎯 应用场景
ASLoRA可应用于各种需要对大型语言模型进行微调的自然语言处理任务,例如文本分类、情感分析、机器翻译和文本生成。该方法尤其适用于资源受限的场景,例如移动设备或边缘计算环境,因为它能够在减少参数量的同时保持甚至提高模型性能。未来,ASLoRA可以扩展到其他类型的模型和任务中,例如计算机视觉和语音识别。
📄 摘要(原文)
As large language models (LLMs) grow in size, traditional full fine-tuning becomes increasingly impractical due to its high computational and storage costs. Although popular parameter-efficient fine-tuning methods, such as LoRA, have significantly reduced the number of tunable parameters, there is still room for further optimization. In this work, we propose ASLoRA, a cross-layer parameter-sharing strategy combining global sharing with partial adaptive sharing. Specifically, we share the low-rank matrix A across all layers and adaptively merge matrix B during training. This sharing mechanism not only mitigates overfitting effectively but also captures inter-layer dependencies, significantly enhancing the model's representational capability. We conduct extensive experiments on various NLP tasks, showing that ASLoRA outperforms LoRA while using less than 25% of the parameters, highlighting its flexibility and superior parameter efficiency. Furthermore, in-depth analyses of the adaptive sharing strategy confirm its significant advantages in enhancing both model flexibility and task adaptability.