ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
作者: Kai Yao, Zhaorui Tan, Tiandi Ye, Lichun Li, Yuan Zhao, Wenyan Liu, Wei Wang, Jianke Zhu
分类: cs.CL, cs.CR
发布日期: 2024-12-13
备注: accepted by AAAI2025
💡 一句话要点
ScaleOT:一种隐私-效用可扩展的异地调优框架,用于保护大语言模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异地调优 隐私保护 大语言模型 强化学习 模型压缩
📋 核心要点
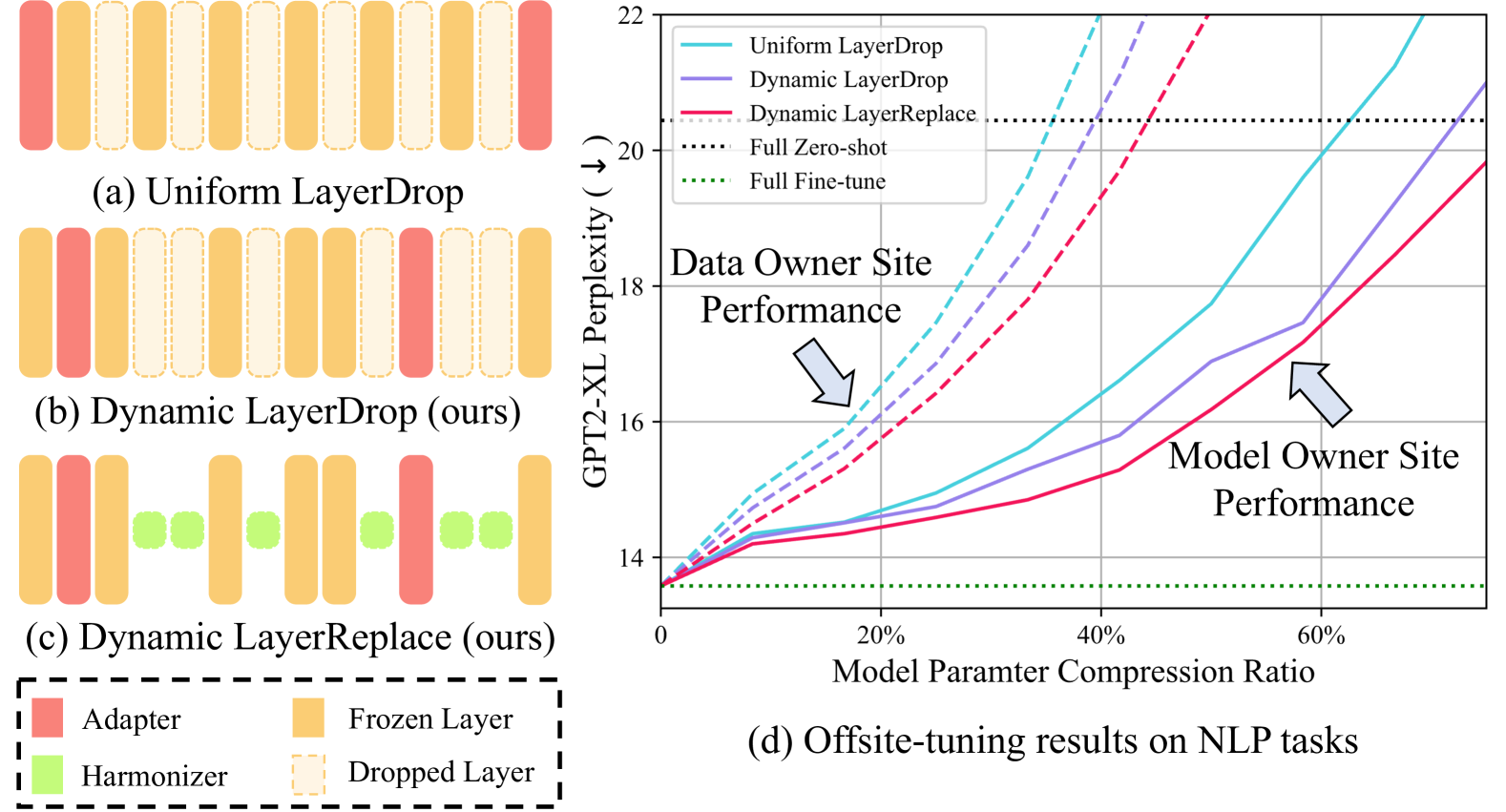
- 现有异地调优方法存在适应性退化、计算成本高以及保护强度有限等问题,主要原因是均匀丢弃LLM层或依赖昂贵的知识蒸馏。
- ScaleOT的核心思想是利用强化学习确定每一层的重要性,并使用轻量级网络(harmonizer)替换部分原始LLM层,从而构建可扩展的模拟器。
- 实验结果表明,ScaleOT在实现接近完全微调性能的同时,能够提供更好的模型隐私保护,有效平衡了隐私和效用。
📝 摘要(中文)
本文提出ScaleOT,一种新颖的隐私-效用可扩展的异地调优框架,旨在有效平衡隐私和效用。异地调优是一种保护隐私的方法,通过与数据所有者共享来自LLM所有者的有损压缩模拟器来调整大型语言模型(LLM),用于下游任务调优。ScaleOT引入了一种新颖的逐层有损压缩算法,该算法使用强化学习来获得每一层的重要性。它采用轻量级网络(称为harmonizer)来替换原始LLM层。通过以不同的比例组合重要的原始LLM层和harmonizer,ScaleOT生成定制的模拟器,以各种模型规模实现最佳性能,从而增强隐私保护。此外,本文提出了一种秩缩减方法,以进一步压缩原始LLM层,从而在对效用影响可忽略不计的情况下显着增强隐私。综合实验表明,与完全微调相比,ScaleOT可以实现几乎无损的异地调优性能,同时获得更好的模型隐私。
🔬 方法详解
问题定义:论文旨在解决异地调优中隐私保护、模型性能和计算成本之间的平衡问题。现有方法要么均匀丢弃LLM层导致性能下降,要么依赖知识蒸馏增加计算负担,同时隐私保护强度有限。
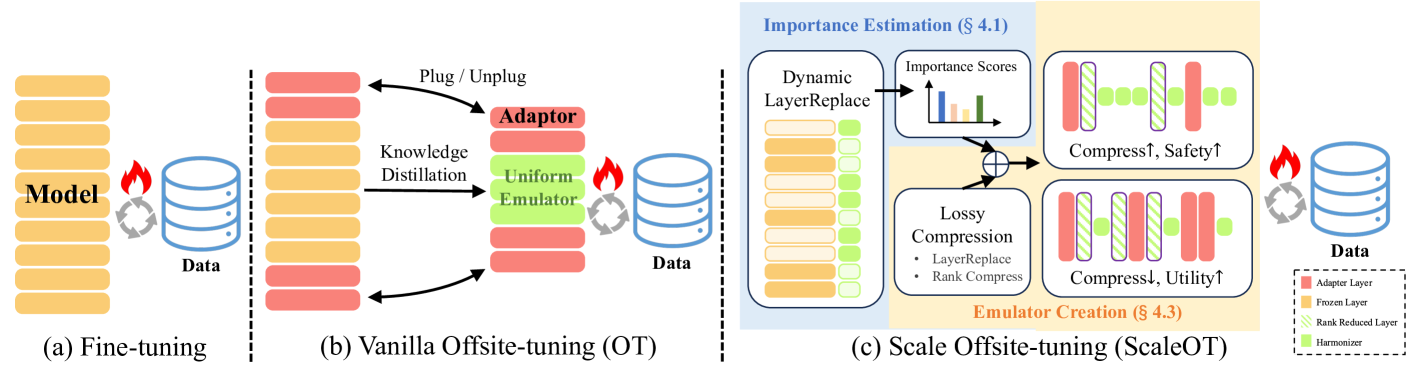
核心思路:论文的核心思路是利用强化学习确定LLM中每一层的重要性,并根据重要性自适应地进行压缩和替换。通过保留重要的原始层并用轻量级harmonizer网络替换不重要的层,可以在保证性能的同时降低模型规模,从而提高隐私保护能力。
技术框架:ScaleOT框架主要包含以下几个阶段:1) 使用强化学习确定LLM每一层的重要性;2) 使用harmonizer网络替换部分原始LLM层,构建模拟器;3) 对原始LLM层进行秩缩减,进一步压缩模型;4) 在下游任务上对模拟器进行调优。
关键创新:ScaleOT的关键创新在于:1) 提出了一种基于强化学习的逐层重要性评估方法,能够更精确地确定每一层对模型性能的贡献;2) 引入了harmonizer网络,能够在保持性能的同时显著降低模型规模;3) 结合了层替换和秩缩减两种压缩方法,进一步增强了隐私保护能力。
关键设计:在层重要性评估中,使用强化学习算法训练一个agent,agent的目标是选择哪些层需要保留,哪些层需要替换。奖励函数的设计至关重要,需要平衡模型性能和隐私保护。Harmonizer网络通常是轻量级的Transformer结构,其参数量远小于原始LLM层。秩缩减方法采用SVD分解,并保留重要的奇异值。
🖼️ 关键图片
📊 实验亮点
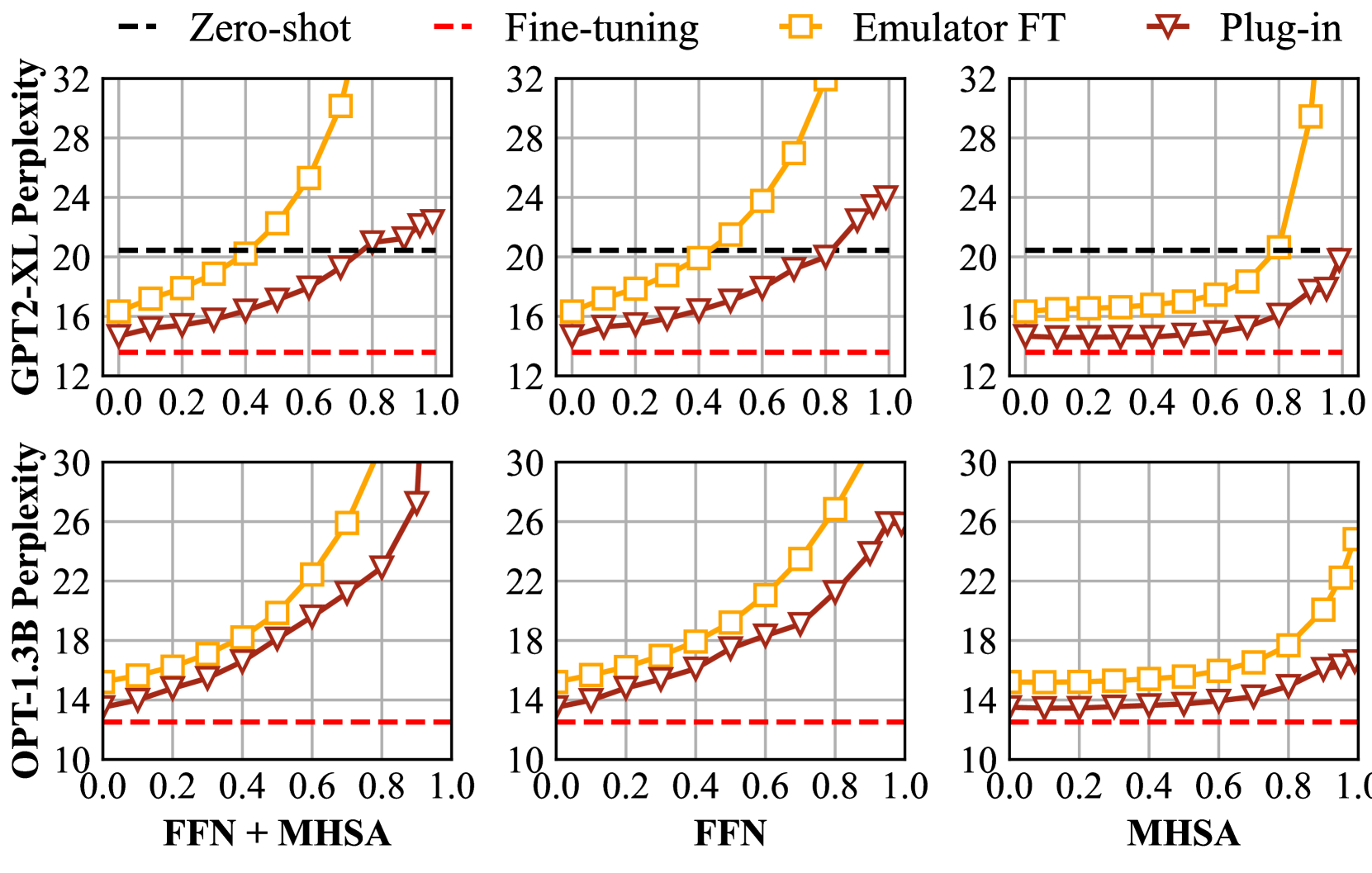
实验结果表明,ScaleOT在多个下游任务上实现了接近完全微调的性能,同时提供了更好的模型隐私保护。例如,在某些任务上,ScaleOT的性能仅比完全微调低1-2个百分点,但模型规模显著减小,从而提高了隐私保护能力。此外,秩缩减方法在几乎不影响模型性能的情况下,进一步增强了隐私保护。
🎯 应用场景
ScaleOT可应用于各种需要保护模型和数据隐私的大语言模型调优场景,例如金融、医疗等敏感数据领域。该方法能够降低模型共享的风险,促进LLM在更多场景下的应用,并为联邦学习等隐私计算技术提供新的思路。
📄 摘要(原文)
Offsite-tuning is a privacy-preserving method for tuning large language models (LLMs) by sharing a lossy compressed emulator from the LLM owners with data owners for downstream task tuning. This approach protects the privacy of both the model and data owners. However, current offsite tuning methods often suffer from adaptation degradation, high computational costs, and limited protection strength due to uniformly dropping LLM layers or relying on expensive knowledge distillation. To address these issues, we propose ScaleOT, a novel privacy-utility-scalable offsite-tuning framework that effectively balances privacy and utility. ScaleOT introduces a novel layerwise lossy compression algorithm that uses reinforcement learning to obtain the importance of each layer. It employs lightweight networks, termed harmonizers, to replace the raw LLM layers. By combining important original LLM layers and harmonizers in different ratios, ScaleOT generates emulators tailored for optimal performance with various model scales for enhanced privacy protection. Additionally, we present a rank reduction method to further compress the original LLM layers, significantly enhancing privacy with negligible impact on utility. Comprehensive experiments show that ScaleOT can achieve nearly lossless offsite tuning performance compared with full fine-tuning while obtaining better model privacy.