LLM Distillation for Efficient Few-Shot Multiple Choice Question Answering
作者: Patrick Sutanto, Joan Santoso, Esther Irawati Setiawan, Aji Prasetya Wibawa
分类: cs.CL
发布日期: 2024-12-13 (更新: 2024-12-30)
💡 一句话要点
提出基于LLM蒸馏的少样本选择题问答高效方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 少样本学习 选择题问答 知识蒸馏 大型语言模型 数据生成
📋 核心要点
- 现有MCQA方法依赖大量标注数据,但在实际应用中数据获取成本高昂,少样本学习成为关键挑战。
- 该论文提出利用LLM进行数据生成和评分,然后通过知识蒸馏将LLM的知识迁移到更小的模型。
- 实验结果表明,该方法在MMLU基准测试中,相比于直接微调,准确率提升超过10%。
📝 摘要(中文)
选择题问答(MCQA)是一个重要的问题,在医学、法律和教育等领域有广泛的实际应用。构建MCQA数据集的高成本使得少样本学习在该领域至关重要。虽然大型语言模型(LLM)可以实现少样本学习,但它们的高计算成本常常阻碍了其在实际场景中的直接应用。为了解决这个挑战,我们提出了一种简单而有效的方法,该方法使用LLM进行数据生成和评分。我们的方法利用LLM创建包含问题和选项的MCQA数据,并为生成的选项分配概率分数。然后,我们利用生成的数据和LLM分配的分数,通过蒸馏损失微调一个更小、更高效的仅编码器模型DeBERTa-v3-base。在Massive Multitask Language Understanding (MMLU)基准上的大量实验表明,我们的方法将准确率从28.9%提高到39.3%,与直接在5-shot示例上微调的基线相比,提高了10%以上。这表明了LLM驱动的数据生成和知识蒸馏对于少样本MCQA的有效性。
🔬 方法详解
问题定义:论文旨在解决少样本选择题问答(MCQA)问题。现有方法在数据量不足的情况下表现不佳,而直接应用大型语言模型(LLM)又面临计算成本过高的问题。因此,如何在计算资源有限的情况下,提升少样本MCQA的性能是本研究的核心问题。
核心思路:论文的核心思路是利用LLM的强大生成和推理能力,生成高质量的伪数据,并使用这些数据来训练一个更小、更高效的模型。通过知识蒸馏,将LLM的知识迁移到小模型,从而在保证性能的同时降低计算成本。
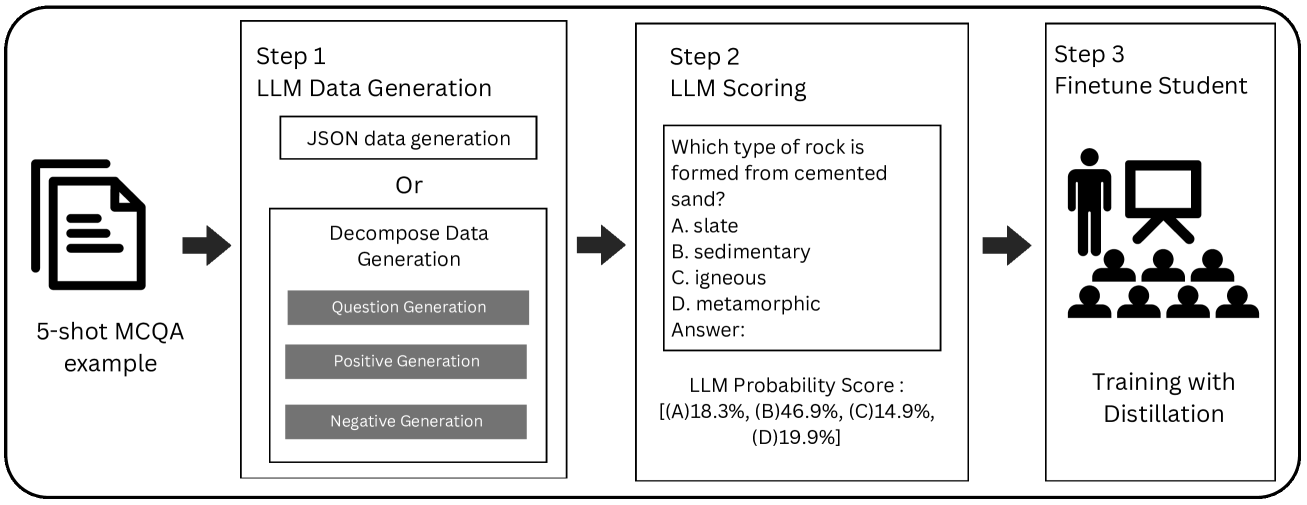
技术框架:整体框架包含两个主要阶段:1) 数据生成和评分阶段:使用LLM生成MCQA数据,并为每个选项分配概率分数。2) 模型训练阶段:使用生成的数据和LLM分配的分数,通过蒸馏损失微调一个较小的encoder-only模型(DeBERTa-v3-base)。
关键创新:该方法的主要创新在于利用LLM进行数据生成和评分,从而有效地扩充了训练数据,并为小模型提供了更丰富的监督信息。与传统的少样本学习方法相比,该方法不需要人工标注大量数据,降低了数据获取成本。与直接使用LLM相比,该方法通过知识蒸馏降低了计算成本。
关键设计:关键设计包括:1) 使用LLM生成高质量的MCQA数据,保证生成数据的多样性和真实性。2) 使用LLM为每个选项分配概率分数,作为小模型的训练目标。3) 使用蒸馏损失函数,引导小模型学习LLM的知识。4) 选择DeBERTa-v3-base作为小模型,因为它在自然语言理解任务中表现出色,并且具有较高的计算效率。
🖼️ 关键图片
📊 实验亮点
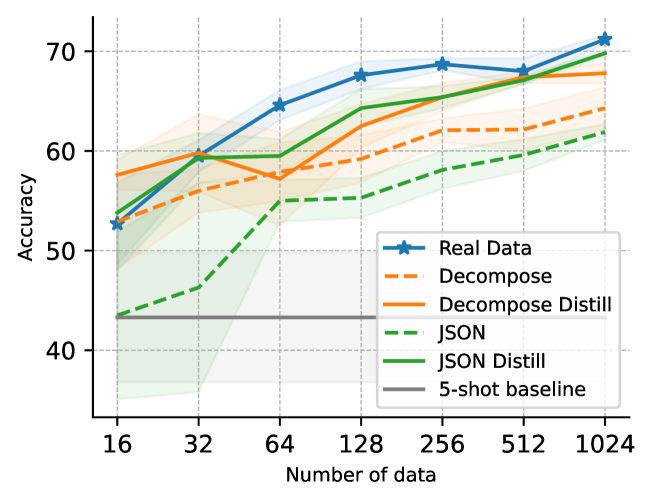
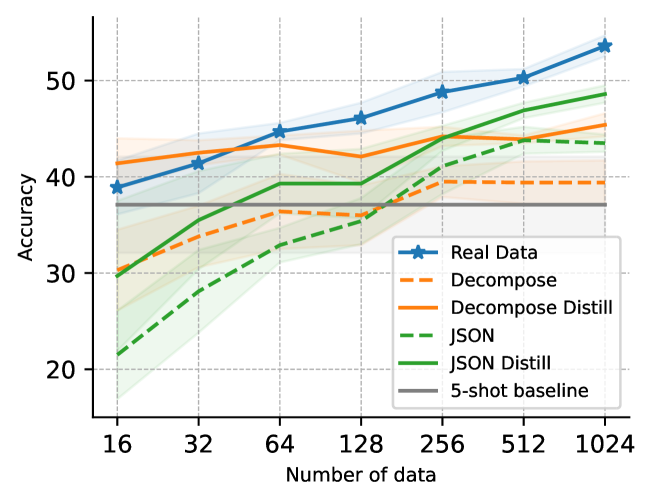
实验结果表明,该方法在MMLU基准测试中取得了显著的性能提升。与直接在5-shot示例上微调的DeBERTa-v3-base基线相比,该方法的准确率从28.9%提高到39.3%,提升超过10%。这表明了LLM驱动的数据生成和知识蒸馏对于少样本MCQA的有效性。
🎯 应用场景
该研究成果可应用于各种需要进行选择题问答的领域,例如在线教育、智能客服、医疗诊断辅助等。通过利用LLM的知识,可以构建更智能、更高效的问答系统,提升用户体验,并降低运营成本。未来,该方法可以进一步扩展到其他类型的问答任务,例如开放域问答和多轮对话。
📄 摘要(原文)
Multiple Choice Question Answering (MCQA) is an important problem with numerous real-world applications, such as medicine, law, and education. The high cost of building MCQA datasets makes few-shot learning pivotal in this domain. While Large Language Models (LLMs) can enable few-shot learning, their direct application in real-world scenarios is often hindered by their high computational cost. To address this challenge, we propose a simple yet effective approach that uses LLMs for data generation and scoring. Our approach utilizes LLMs to create MCQA data which contains questions and choices, and to assign probability scores to the generated choices. We then use the generated data and LLM-assigned scores to finetune a smaller and more efficient encoder-only model, DeBERTa-v3-base by leveraging distillation loss. Extensive experiments on the Massive Multitask Language Understanding (MMLU) benchmark demonstrate that our method improves accuracy from 28.9% to 39.3%, representing a gain of over 10% compared to a baseline finetuned directly on 5-shot examples. This shows the effectiveness of LLM-driven data generation and knowledge distillation for few-shot MCQA.