GReaTer: Gradients over Reasoning Makes Smaller Language Models Strong Prompt Optimizers
作者: Sarkar Snigdha Sarathi Das, Ryo Kamoi, Bo Pang, Yusen Zhang, Caiming Xiong, Rui Zhang
分类: cs.CL
发布日期: 2024-12-12 (更新: 2025-04-07)
备注: ICLR 2025 Camera Ready
🔗 代码/项目: GITHUB
💡 一句话要点
GReaTer:利用推理梯度优化小模型Prompt,提升其在复杂任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt优化 梯度优化 小模型 推理任务 自然语言处理 自动化Prompt工程 任务损失梯度
📋 核心要点
- 现有Prompt优化方法依赖大型LLM的文本反馈,成本高昂且小模型难以生成有效反馈,限制了Prompt优化的效率和可扩展性。
- GReaTer通过利用任务损失梯度,直接优化小模型的Prompt,无需依赖大型LLM,从而降低了Prompt优化的成本和门槛。
- 实验表明,GReaTer在多个推理任务上超越了现有Prompt优化方法,并提升了小模型的性能,使其接近甚至超过大型模型。
📝 摘要(中文)
大型语言模型(LLM)的有效性与Prompt的设计密切相关,因此Prompt优化对于提升其在各种任务中的性能至关重要。许多现有的Prompt工程自动化方法仅依赖于文本反馈,即仅基于大型、计算成本高昂的LLM识别的推理错误来改进Prompt。然而,较小的模型难以生成高质量的反馈,导致完全依赖于大型LLM的判断。此外,这些方法由于纯粹在文本空间中操作,因此无法利用更直接和细粒度的信息,例如梯度。为此,我们提出了一种新颖的Prompt优化技术GReaTer,它直接结合了任务特定推理的梯度信息。通过利用任务损失梯度,GReaTer能够为开源、轻量级语言模型实现Prompt的自我优化,而无需昂贵的闭源LLM。这使得高性能的Prompt优化无需依赖大型LLM成为可能,缩小了小型模型与Prompt改进所需的复杂推理之间的差距。在包括BBH、GSM8k和FOLIO在内的各种推理任务上的广泛评估表明,GReaTer始终优于先前的最先进的Prompt优化方法,甚至优于那些依赖于强大LLM的方法。此外,GReaTer优化的Prompt通常表现出更好的可迁移性,并且在某些情况下,将任务性能提升到与大型语言模型相当或超过的水平,突出了由推理梯度引导的Prompt优化的有效性。GReaTer的代码可在https://github.com/psunlpgroup/GreaTer 获取。
🔬 方法详解
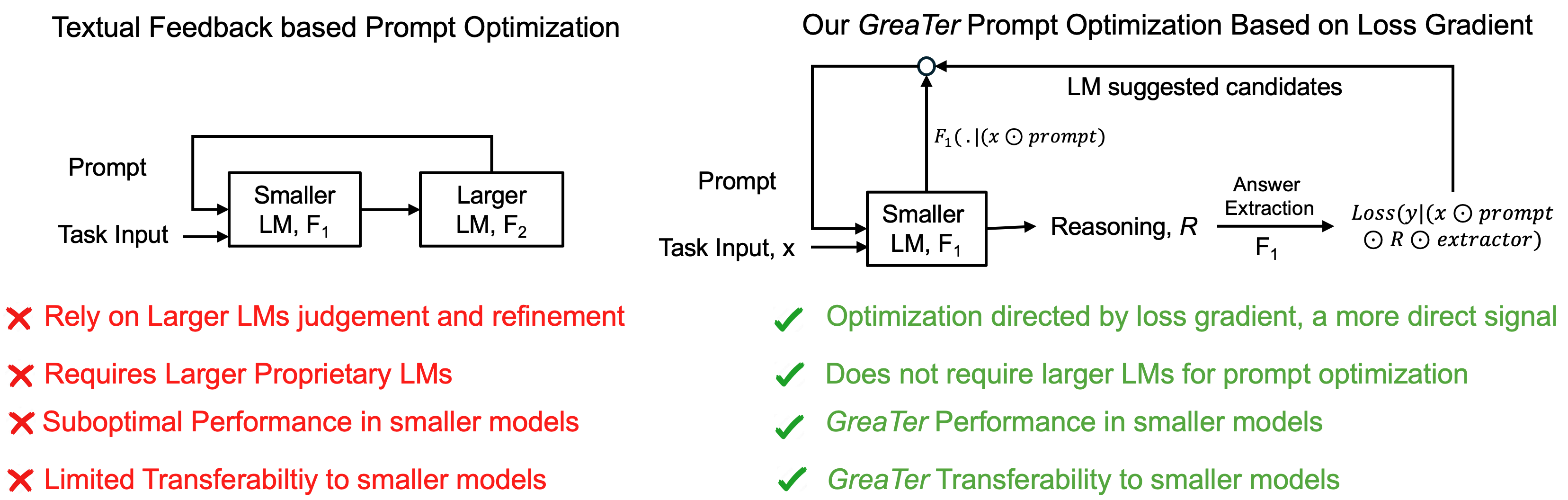
问题定义:现有Prompt优化方法主要依赖大型语言模型(LLM)的文本反馈进行迭代优化,存在以下痛点:一是计算成本高昂,依赖于计算资源密集型的大型LLM;二是小模型难以提供高质量的反馈,导致优化效果不佳;三是仅利用文本信息,忽略了更细粒度的梯度信息,限制了优化潜力。
核心思路:GReaTer的核心思路是利用任务损失梯度直接优化Prompt,从而避免对大型LLM的依赖。通过计算Prompt对任务损失的梯度,可以指导Prompt向更优的方向调整,实现Prompt的自我优化。这种方法能够充分利用小模型的计算能力,并挖掘梯度信息中蕴含的优化潜力。
技术框架:GReaTer的整体框架包括以下几个主要阶段:1) 初始化Prompt:使用某种策略(例如人工设计或随机生成)初始化Prompt。2) 前向传播:将Prompt输入到小模型中,得到任务输出。3) 计算损失:根据任务输出和真实标签计算损失函数。4) 反向传播:计算损失函数对Prompt的梯度。5) Prompt更新:根据梯度信息更新Prompt。重复步骤2-5,直到Prompt收敛或达到最大迭代次数。
关键创新:GReaTer最重要的技术创新点在于直接利用梯度信息优化Prompt,而不是依赖于大型LLM的文本反馈。这种方法能够更有效地利用小模型的计算能力,并挖掘梯度信息中蕴含的优化潜力。与现有方法相比,GReaTer无需依赖大型LLM,降低了Prompt优化的成本和门槛。
关键设计:GReaTer的关键设计包括:1) Prompt表示:Prompt通常表示为可学习的向量或嵌入。2) 梯度计算:使用自动微分技术计算损失函数对Prompt的梯度。3) Prompt更新策略:可以使用各种优化算法(例如梯度下降、Adam等)更新Prompt。4) 损失函数:根据具体的任务选择合适的损失函数(例如交叉熵损失、均方误差等)。5) 正则化:为了防止过拟合,可以添加正则化项到损失函数中。
🖼️ 关键图片

📊 实验亮点
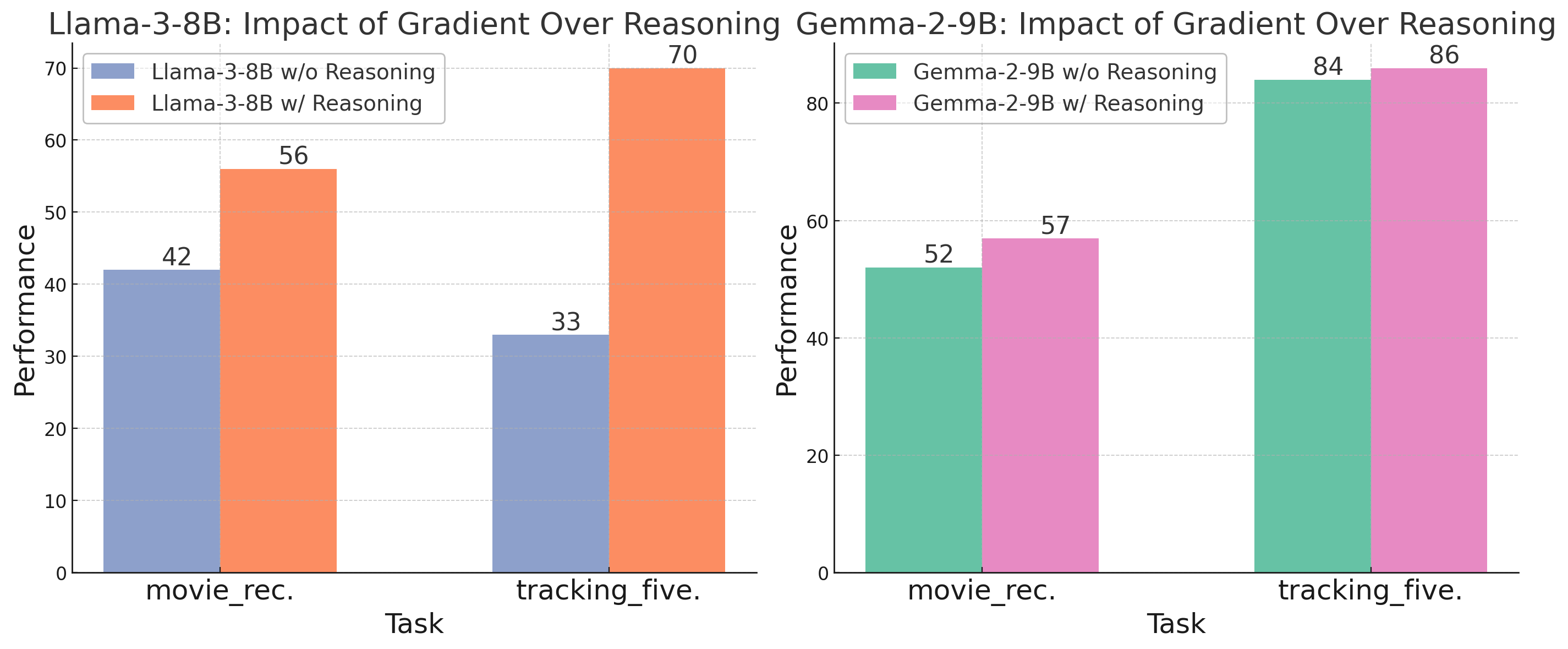
实验结果表明,GReaTer在BBH、GSM8k和FOLIO等多个推理任务上显著优于现有的Prompt优化方法。例如,在某些任务上,GReaTer优化后的Prompt甚至能够使小模型的性能达到或超过大型LLM的水平。此外,GReaTer优化后的Prompt还表现出更好的可迁移性,能够在不同的任务和数据集上取得良好的效果。
🎯 应用场景
GReaTer可应用于各种需要Prompt优化的自然语言处理任务,例如文本分类、问答、摘要生成等。它尤其适用于资源受限的场景,例如边缘计算设备或移动设备,在这些场景下,使用大型LLM进行Prompt优化是不切实际的。GReaTer的出现有望推动小模型在复杂任务上的应用,并降低人工智能技术的应用门槛。
📄 摘要(原文)
The effectiveness of large language models (LLMs) is closely tied to the design of prompts, making prompt optimization essential for enhancing their performance across a wide range of tasks. Many existing approaches to automating prompt engineering rely exclusively on textual feedback, refining prompts based solely on inference errors identified by large, computationally expensive LLMs. Unfortunately, smaller models struggle to generate high-quality feedback, resulting in complete dependence on large LLM judgment. Moreover, these methods fail to leverage more direct and finer-grained information, such as gradients, due to operating purely in text space. To this end, we introduce GReaTer, a novel prompt optimization technique that directly incorporates gradient information over task-specific reasoning. By utilizing task loss gradients, GReaTer enables self-optimization of prompts for open-source, lightweight language models without the need for costly closed-source LLMs. This allows high-performance prompt optimization without dependence on massive LLMs, closing the gap between smaller models and the sophisticated reasoning often needed for prompt refinement. Extensive evaluations across diverse reasoning tasks including BBH, GSM8k, and FOLIO demonstrate that GReaTer consistently outperforms previous state-of-the-art prompt optimization methods, even those reliant on powerful LLMs. Additionally, GReaTer-optimized prompts frequently exhibit better transferability and, in some cases, boost task performance to levels comparable to or surpassing those achieved by larger language models, highlighting the effectiveness of prompt optimization guided by gradients over reasoning. Code of GReaTer is available at https://github.com/psunlpgroup/GreaTer.