OpenNER 1.0: Standardized Open-Access Named Entity Recognition Datasets in 50+ Languages
作者: Chester Palen-Michel, Maxwell Pickering, Maya Kruse, Jonne Sälevä, Constantine Lignos
分类: cs.CL
发布日期: 2024-12-12 (更新: 2025-12-18)
备注: Published in the proceedings of EMNLP 2025
期刊: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33637-33662, Suzhou, China. Association for Computational Linguistics
DOI: 10.18653/v1/2025.emnlp-main.1708
🔗 代码/项目: GITHUB
💡 一句话要点
提出OpenNER 1.0以解决多语言命名实体识别数据集标准化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命名实体识别 多语言处理 数据集标准化 自然语言处理 机器学习
📋 核心要点
- 现有的命名实体识别数据集缺乏标准化,导致跨语言和跨本体的研究面临挑战。
- OpenNER 1.0通过统一数据集格式和标注,提供了一个多语言、多本体的NER研究平台。
- 实验结果显示,当前模型在不同语言上的表现不均衡,表明在NER任务上仍需进一步优化。
📝 摘要(中文)
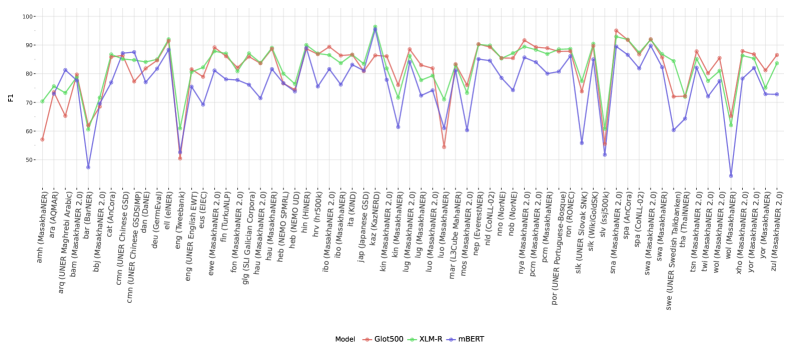
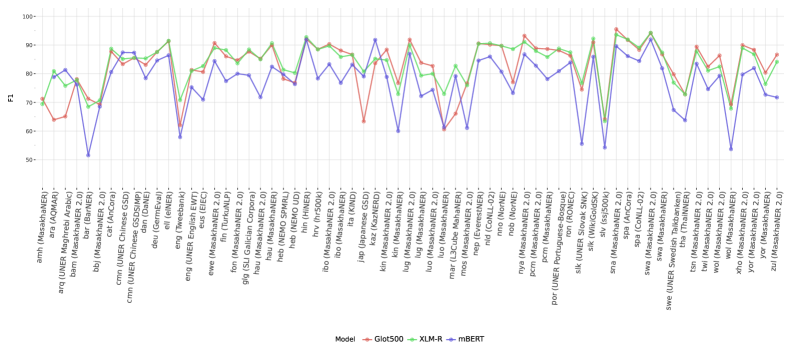
我们提出了OpenNER 1.0,这是一个标准化的开放获取命名实体识别(NER)数据集集合。OpenNER包含36个NER语料库,涵盖52种语言,并在不同的命名实体本体中进行人工标注。我们修正了标注格式问题,将原始数据集标准化为统一的表示形式,并提供了一种结构,便于多语言和多本体NER研究。我们使用三种预训练的多语言模型和两种大型语言模型提供基线结果,以比较近期模型的性能,并促进未来NER研究。我们发现没有单一模型在所有语言中表现最佳,且在NER任务上,LLMs仍需大量工作以提高性能。
🔬 方法详解
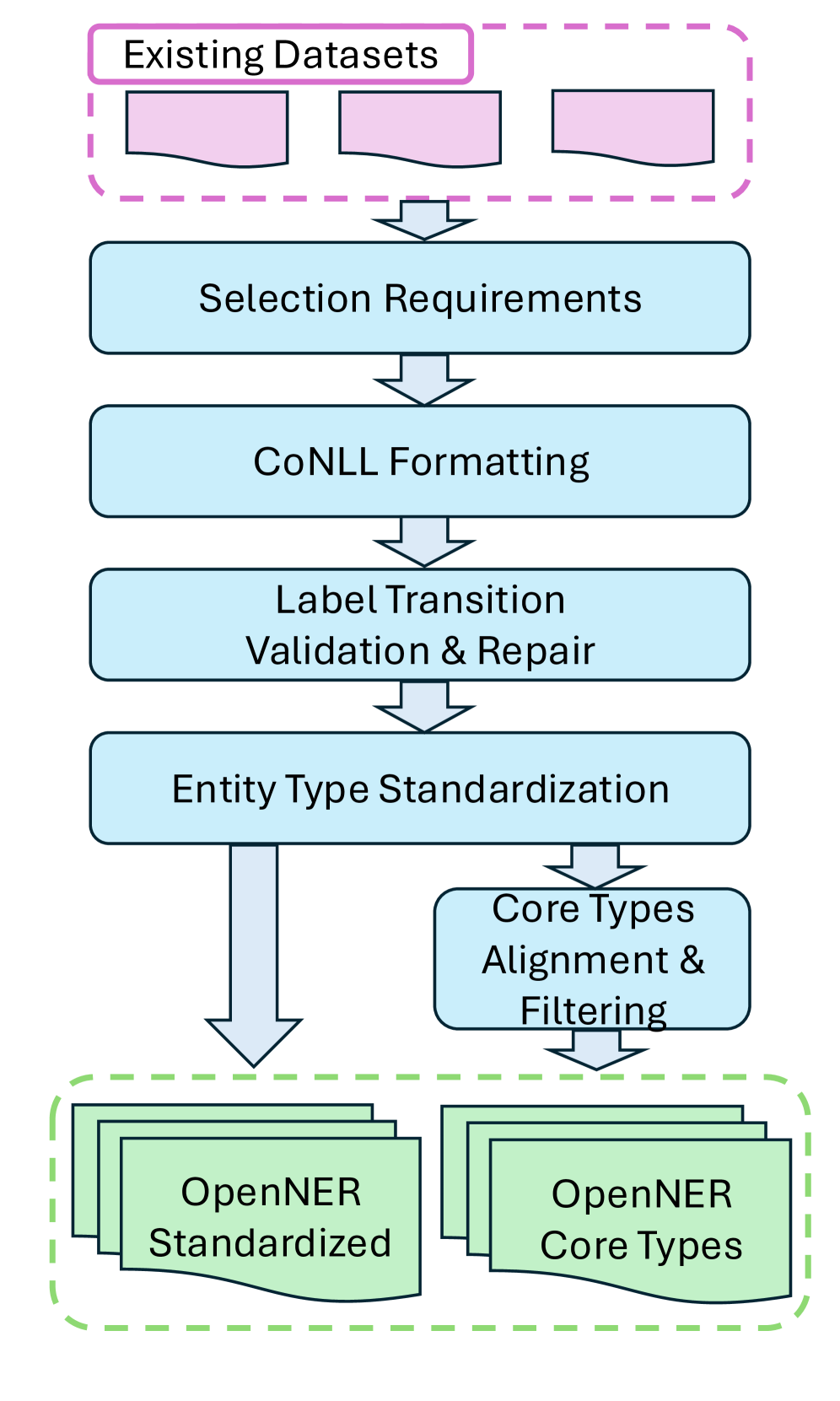
问题定义:本论文旨在解决现有命名实体识别(NER)数据集缺乏标准化的问题。现有方法在跨语言和跨本体的研究中存在标注格式不一致和数据集结构不统一的痛点。
核心思路:我们通过修正标注格式和统一数据集表示,构建了一个标准化的NER数据集集合,旨在促进多语言和多本体的NER研究。
技术框架:OpenNER 1.0包含36个NER语料库,涵盖52种语言,采用一致的实体类型名称。我们提供了一个结构化的数据集,便于研究人员进行比较和分析。
关键创新:最重要的创新在于数据集的标准化处理和统一标注,使得不同语言和本体之间的NER研究变得更加可行和高效。
关键设计:在数据集构建过程中,我们对标注格式进行了修正,并确保实体类型名称的一致性。此外,我们还使用了三种预训练的多语言模型和两种大型语言模型进行基线性能评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用OpenNER 1.0进行的基线测试显示,当前的多语言模型在不同语言上的表现差异显著,没有单一模型在所有语言中表现最佳。这一发现强调了在NER任务上进一步优化大型语言模型的必要性。
🎯 应用场景
OpenNER 1.0的研究成果可广泛应用于多语言环境下的自然语言处理任务,尤其是在命名实体识别领域。其标准化的数据集将为研究人员提供更为可靠的基准,推动多语言NER技术的发展,具有重要的学术和实际价值。
📄 摘要(原文)
We present OpenNER 1.0, a standardized collection of openly-available named entity recognition (NER) datasets. OpenNER contains 36 NER corpora that span 52 languages, human-annotated in varying named entity ontologies. We correct annotation format issues, standardize the original datasets into a uniform representation with consistent entity type names across corpora, and provide the collection in a structure that enables research in multilingual and multi-ontology NER. We provide baseline results using three pretrained multilingual language models and two large language models to compare the performance of recent models and facilitate future research in NER. We find that no single model is best in all languages and that significant work remains to obtain high performance from LLMs on the NER task. OpenNER is released at https://github.com/bltlab/open-ner.